原文链接:
原文笔记:
What:
BETR:Pre-training of Deep Bidirectional Transformers for Language Understanding
(We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.)
Pre-training:在一个大数据集上预训练用于其他NLP任务的模型(预训练模型使得资源不多的任务(比如说训练样本比较少)的任务也能够享受深度神经网络
Deep:把网络做的深一点
Bidirectional:网络是双向的,是这篇文章的主要创新,Bert也是主要用来解决原来的语言模型是单向的限制的
Language Understanding:Transformers本来是用在翻译这种小任务上边
Bert可以使Transformer用在更广义的语言的理解上面
所以总结下来,这篇文章是关于BETR的模型,它是一个深的双向的transformer,是用来做预训练的,是针对的是一般的语言的理解任务
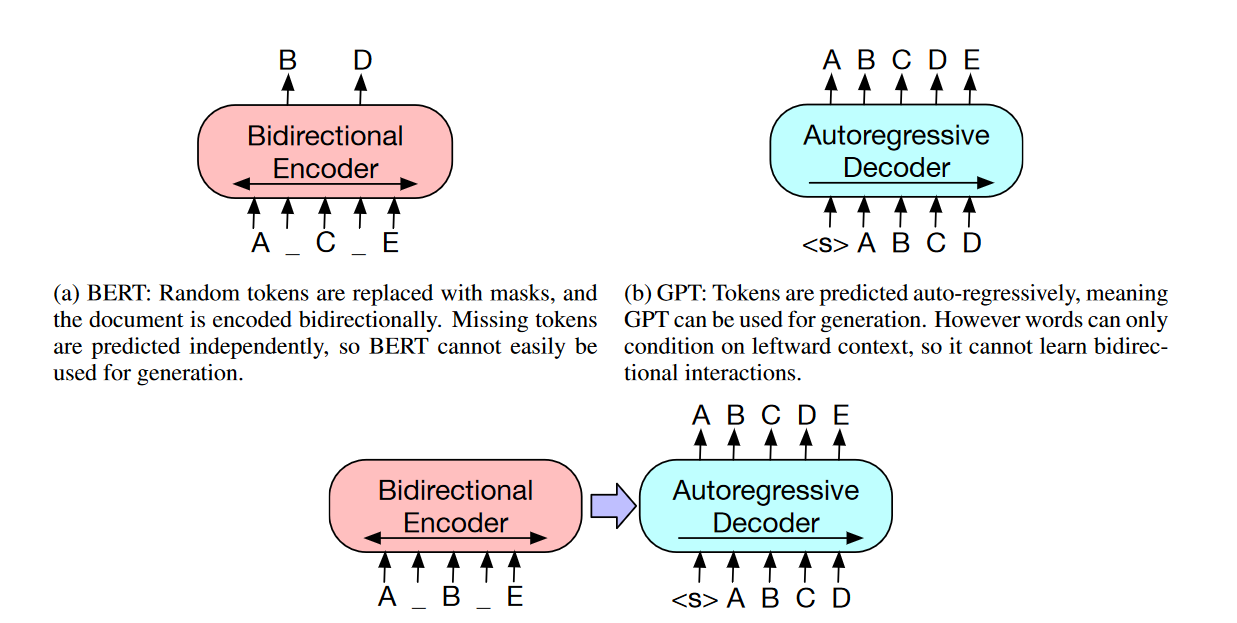
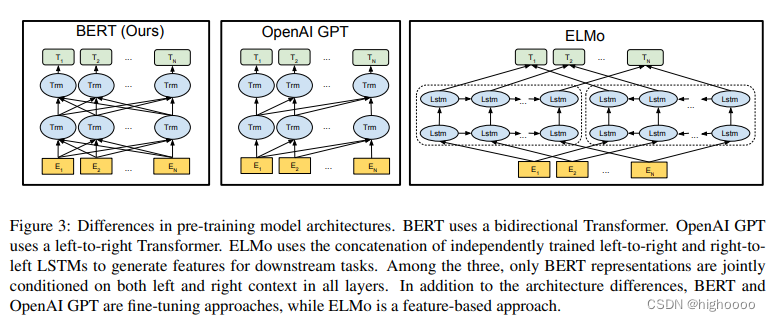
GPT只用单向信息(他用左边的上下文信息去预测未来),而Bert是用双向的上下文信息去预测中间
Elmo是用的基于RNN的架构,而Bert用的是Transformer,所以Elmo在用到一些下游的任务的时候呢,他需要对架构做一点点调整,但是BERT的地方相对比较简单,只需要改最上层的就行了,这个跟GPT其实是一样的
Bert的出现使得我们终于可以在一个大的数据集上训练好一个比较深的神经网络,然后应用在很多NLP的任务上面,既简化了这些NLP任务的训练,又提升了它的性能,所以Bert及其之后的工作使得自认语言处理在过去三年(2019-2022)里面有一个质的飞跃
Bert主要的工作就是把前任的结果拓展到深的双向的架构上面,使得同样的一个预训练模型能够处理大量的不一样的自然语言任务
这篇文章的贡献:
1、Bert模型展现了双向信息的重要性,GPT只用了单向,并且作者的双向的不是像其他一些工作一样把两个方向的信息做一个简单的concat,Bert模型在双向信息的应用上更好一点
2、假设有一个比较好的预训练模型的话,就不需要对特定的任务做些特定的模型的改动了,作者说Bert是第一个基于微调的模型,在一系列的NLP任务上(包括句子层面的任务和词元层面的任务)都取得了最好的成绩
3、代码开源
4、Bert和他以后的一些工作证明了,在NLP上面使用没有标号的大量的数据集训练成模型,效果比你在有标号的相对小一些的数据集上训练模型效果更好(同样的想法现在也在渐渐的被计算机视觉使用
Why:
1、在计算机视觉领域存在在ImageNet数据集上预训练好的CNN模型能直接用来迁移学习去处理视觉领域的其他任务,在NLP领域Bert没出现之前不存在这么一个深得神经网络使得我训练好之后能够帮助一大片的NLP的任务,就是说在NLP领域每次还是根据具体的任务去构造神经网络分别去做训练(Bert不是第一个提出来这么做的人,而是说Bert让这个想法出圈了,让后面的研究者都跟这Bert用这个方法做自然语言处理的任务)
2、标准的语言模型是单向的,这导致在选架构的时候有一些局限性,比如说在gpt里面它用的是一个从左到右的一个架构(假设句子是从左读到右的话),但是如果要做句子层面的分析的话,比如做句子的情感分析的话将句子从左读到右和把句子从右读到左都是合法的,就算是词元上的一些任务,不如说Q&A(问答)任务的时候,也可以是看完整个句子去选答案而不是真的要去一个一个的去读每个词元,如果把两个方向的信息都放进来的话,应该是能提升这些任务的性能的
3、作者基于两个前人工作做改进
1、Elmo:使用的是双向的信息,但是用的架构比较老是RNN,非监督的基于特征的工作
2、GPT:用的是新一点的transformer架构,但是它只能处理单向的信息,非监督的基于微调的工作
作者想把ELMo双向的想法和GPT使用tranformer的架构相结合成为了Bert
Challenge:
1、如何设计双向的Encoder结构?
2、MLM (Masked language model)带来的问题:预训练和微调看到的数据不一样。
Idea:
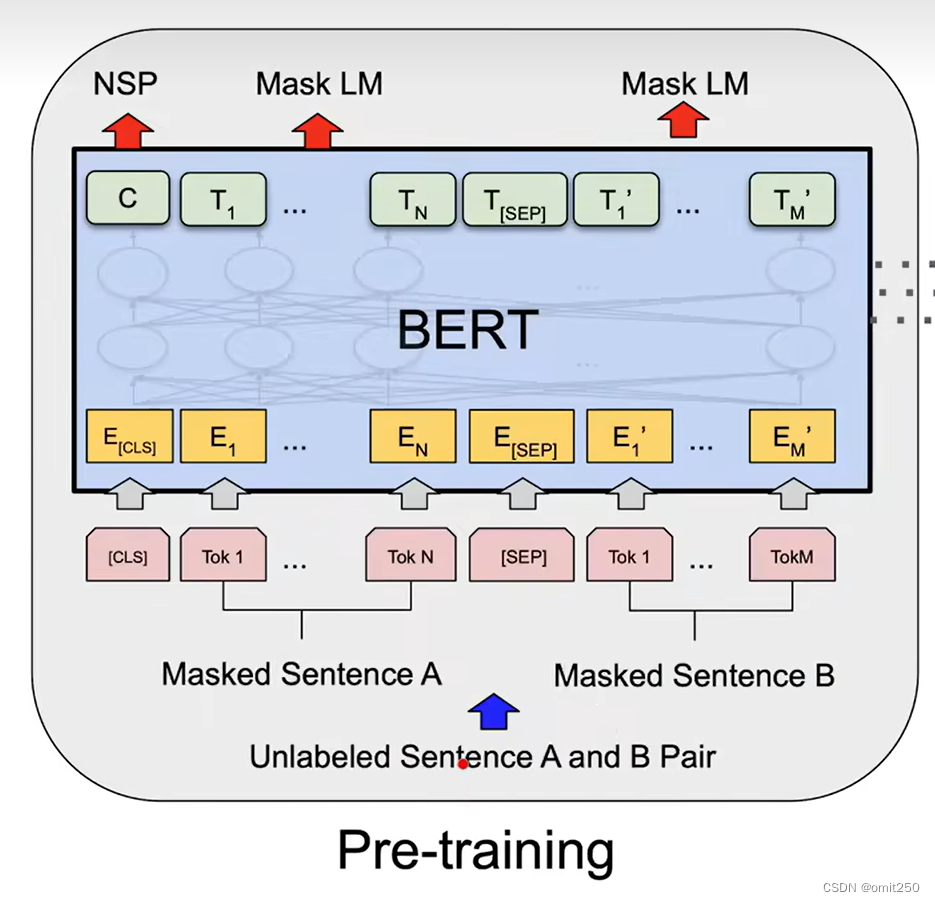
1、提出了一种带掩码的语言模型:每次随机选择一些词元去把它盖住(用掩码),目标是预测这些被盖住的那些词,等价于给一个句子挖一些空,让你去做完形填空,与标准的从左到右的语言模型不同的是,带掩码的语言模型允许你去看左右的信息,就是说你做完形填空的时候不能只看左边的信息也要看看右边的信息才行,只有结合填空位置的上下文信息才能正确的填空
(做语言模型的时候不是预测未来而是变成完形填空)
2、在带掩码的语言模型之外,作者还训练了一个别的任务:“下一个句子的预测”它的核心思想是说我给你两个句子,让模型来判断这两个句子在原文中是相邻的还是在全文中随机采样的两个句子放在了一起,这样的话能让模型学习到句子层面的一些信息
Model:
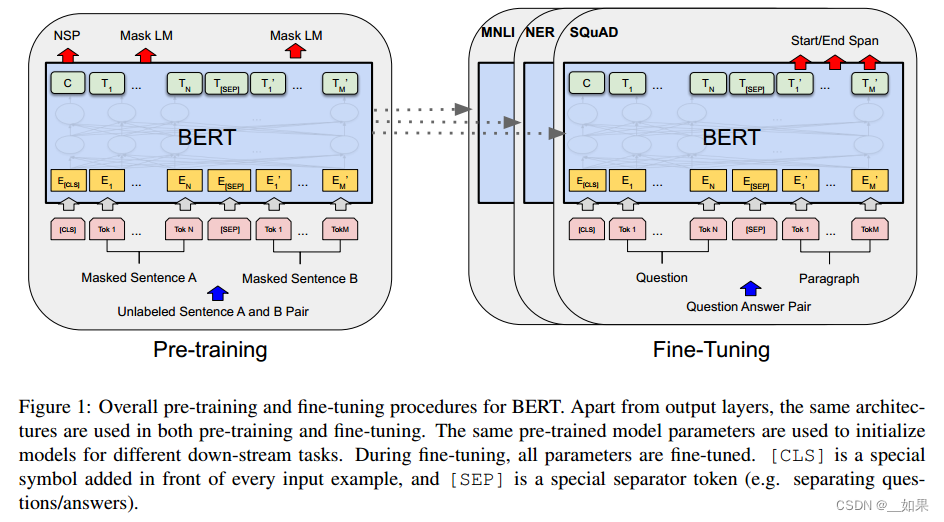
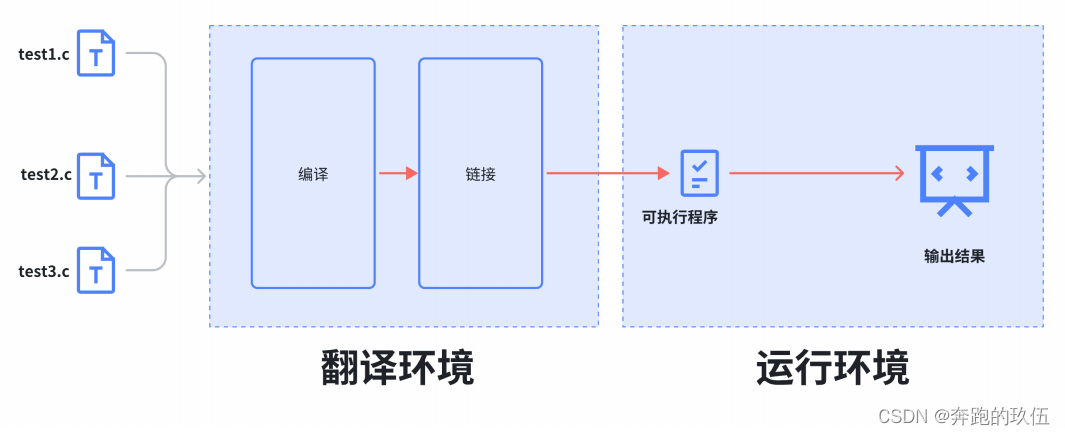
Bert里面包含两个步骤:
1、预训练
在这个步骤中模型是在一个没有标号的数据上训练的
2、微调
在微调的时候我们同样是用一个bert模型,但是他的权重就是被初始化成我们在预训练中间得到的那个权重,所有的权重在微调的过程中都会参与训练,用的是有标号的数据,每一个下游数据都会创建一个新的Bert模型(虽然初始化都是用的预训练的权重)
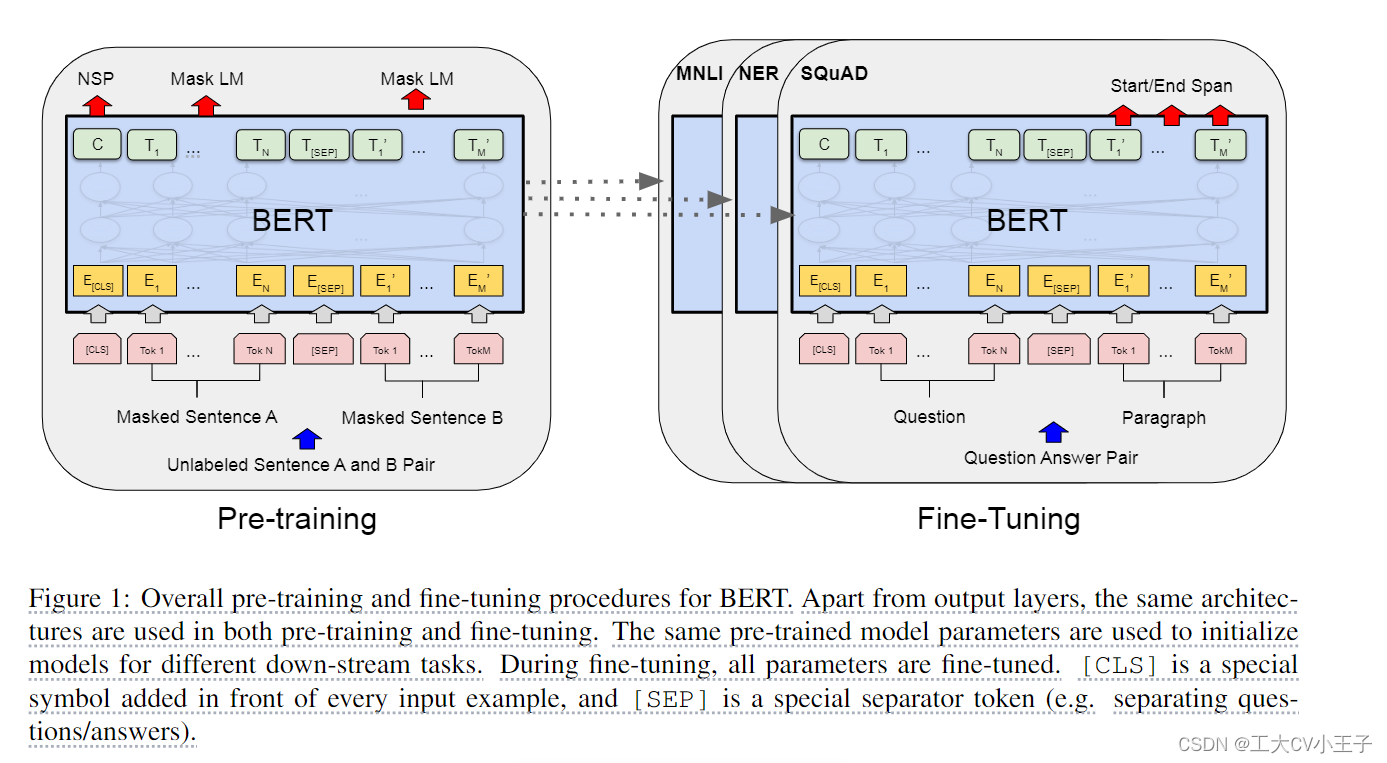
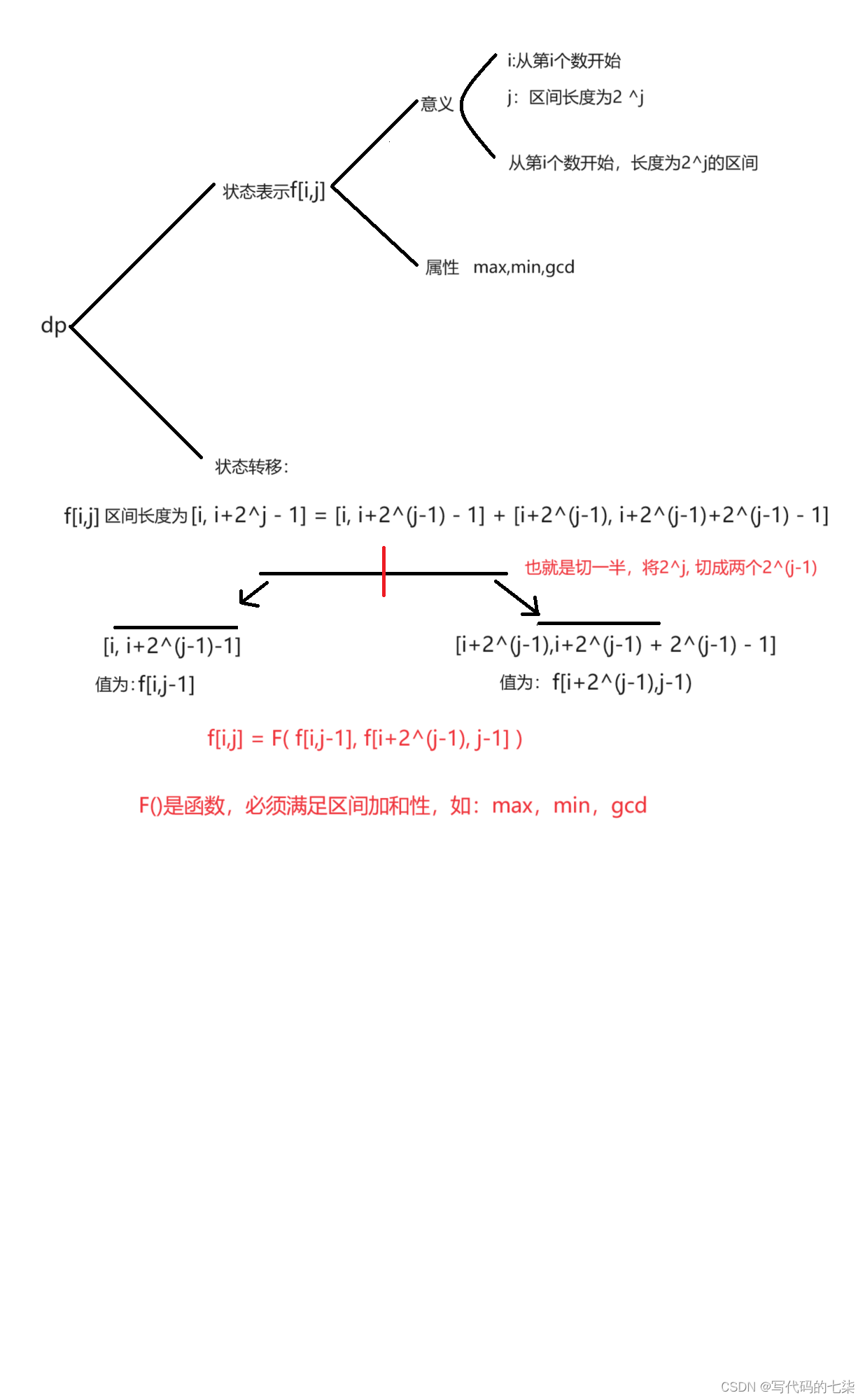
Model Architecture:
(challenge1)模型的架构就是一个多层的双向的Transformer的编码器,而且它是直接基于原始的论文和原始的代码没有什么改动,作者主要调了三个参数,一个是Transformer块的个数,一个是隐藏层的大小,还有一个是多头注意力的头的个数,作者设计了两个版本的Bert:BERTbase(L=12,H=768,A=12,总参数量:110M)BERTlarge(L=24,H=1024,A=16,总参数量:340M)
(bert的复杂度和L是线性的关系,跟你的H是一个平方的关系,因为L变为原来的两倍,所以要使H^2大概等于原来的H^2的两倍,头的个数变成的16是因为每个头它的维度都固定在了64)
bert用于和gpt作比较,bertlarge用于刷榜
Bert只有一个编码器,所以如果输入是句子对的话要把他们拼接在一起
Bert采用WordPiece Embedding
Input/Output Representations
下游任务有处理一个句子 or 处理 2 个句子,BERT 能处理不同句子数量的下游任务,使输入可以是 a single sentence and a pair of sentences (Question answer)
a single sentence: 一段连续的文字,不一定是真正上的语义上的一段句子,它是我的输入叫做一个序列 sequence。
A "sequence" 序列可以是一个句子,也可以是两个句子。
BERT 的输入和 transformer 区别?
transformer 预训练时候的输入是一个序列对。编码器和解码器分别会输入一个序列。
BERT 只有一个编码器,为了使 BERT 能处理两个句子的情况,需要把两个句子并成一个序列。
BERT 如何切词?
WordPiece, 把一个出现概率低的词切开,只保留一个词出现频率高的子序列,30k token 经常出现的词(子序列)的字典。
否则,空格切词 --> 一个词是一个 token。数据量打的时候,词典会特别大,到百万级别。可学习的参数基本都在嵌入层了。
BERT 的输入序列如何构成?
[ CLS ] + [ SEP ]
序列开始: [ CLS ] 输出的是句子层面的信息 sequence representation
BERT 使用的是 transformer 的 encoder,self-attention layer 会看输入的每个词和其它所有词的关系。
就算 [ CLS ] 这个词放在我的第一个的位置,他也是有办法能看到之后所有的词。所以他放在第一个是没关系的,不一定要放在最后。
区分 两个合在一起的句子 的方法:(不是或的关系而是同时使用)
1、每个句子后 + [ SEP ] 表示 seperate
2、学一个嵌入层 来表示 整个句子是第一句还是第二句
[ CLS ] [Token1] …… [Token n] [SEP] [Token1'] …… [Token m]
每一个 token 进入 BERT 得到 这个 token 的embedding 表示。
对于 BERT,输入一个序列,输出一个序列。
最后一个 transformer 块的输出,表示 这个词源 token 的 BERT 的表示。在后面再添加额外的输出层,来得到想要的结果。
For a given token, 进入 BERT 的表示 = token 本身的表示 + segment 句子的表示 + position embedding 位置表示
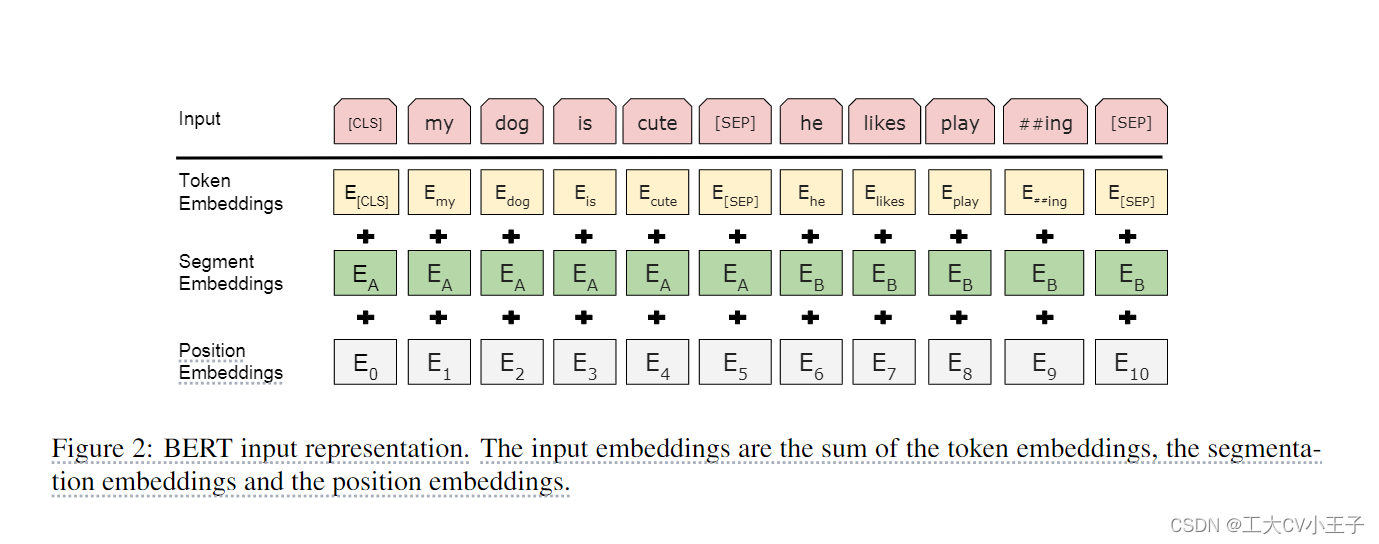
图 2 BERT 嵌入层
一个词源的序列 --> 一个向量的序列 --> 进入 transformer 块
Token embeddings: 词源的embedding层,整成的embedding层, 每一个 token 有对应的词向量。
Segement embeddings: 这个 token 属于第一句话 A还是第二句话 B。
Position embeddings: 输入的大小 = 这个序列最长有多长? i.e., 1024
Position embedding 的输入是 token 词源在这个序列 sequence 中的位置信息。从0开始 1 2 3 4 --> 1024
BERT input representation = token embeddings + segment embeddings + position embeddings
BERT 的 segment embedding (属于哪个句子)和 position embedding (位置在哪里)是学习得来的,transformer 的 position embedding 是给定的。
BERT 关于 pre-train 和 fine-tune 同样的部分 == end
MLM 带来的问题:预训练和微调看到的数据不一样。预训练的输入序列有 15% [MASK],微调时的数据没有 [MASK].(challenge2)(为了训练深度双向表示,我们只需随机屏蔽一定百分比的输入标记,然后预测这些掩码标记。)
15% 计划被 masked 的词: 80% 的概率被替换为 [MASK], 10% 换成 random token,10% 不改变原 token。但 T_i 还是被用来做预测。
80%, 10%, 10% 的选择,有 ablation study in appendix
unchanged 和 微调中的数据应该是一样的。
原文翻译
Abstract:
我们引入了一种新的语言表示模型 BERT,它代表来自 Transformer 的双向编码器表示。与最近的语言表示模型 (Peters et al., 2018aElmo; Radford et al., 2018GPT) 不同,BERT 旨在通过联合考虑所有层中的左右上下文来从未标记文本中预训练深度双向表示。(这句话是针对GPT而说的)因此,预训练的 BERT 模型只需一个额外的输出层就可以进行微调,为各种任务(例如问答和语言推理)创建最先进的模型,而无需大量特定于任务的架构修改(这句话是针对Elmo而说的(Elmo基于RNN,Bert基于Transformer))。(跟另外和我比较相关的工作的区别是什么,跟别人比改进了什么地方)
BERT 在概念上很简单,在实验上很强大。它在 11 个自然语言处理任务上获得了新的最先进的结果,包括将 GLUE 分数提高到 80.5%(7.7% 的绝对改进)、MultiNLI 准确率提高到 86.7%(4.6% 的绝对改进)、SQuAD v1.1 问答测试 F1 到 93.2(1.5 分绝对改进)和 SQuAD v2.0 测试 F1 到 83.1(5.1 分绝对改进)。(讲故事的时候绝对精度(在整体指标的一个什么水平)和相对精度(跟别人比)都很重要)(我的结果特别好,结果比别人好在什么地方)
Introduction (交代研究方向的上下文关系)
Related Work
1、非监督的基于特征的工作
2、非监督的基于微调的工作
3、在有标号的数据上做迁移学习(自然语言推理/机器翻译)
剩下略了。。。
参考文献