主要是在Arduino 上用的,拿来实现滑动平均滤波器。已经有几个成品的库可以用,但是总有些不太满意的地方,所以决定还是自己写吧。作为一个特色,这个实现除了支持普通队列的尾部添加、头部删除模式,还可以在头部添加,尾部删除,也就是双向增减。
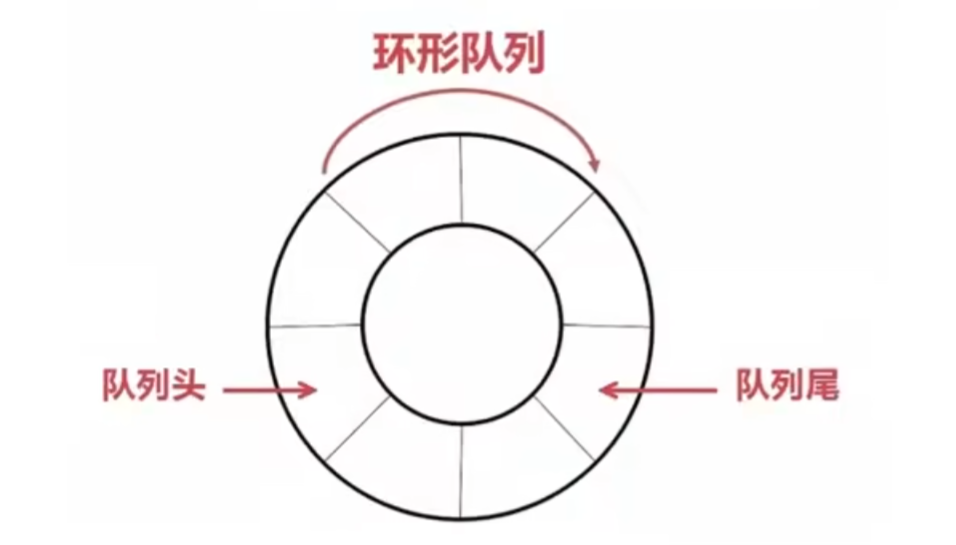
原理
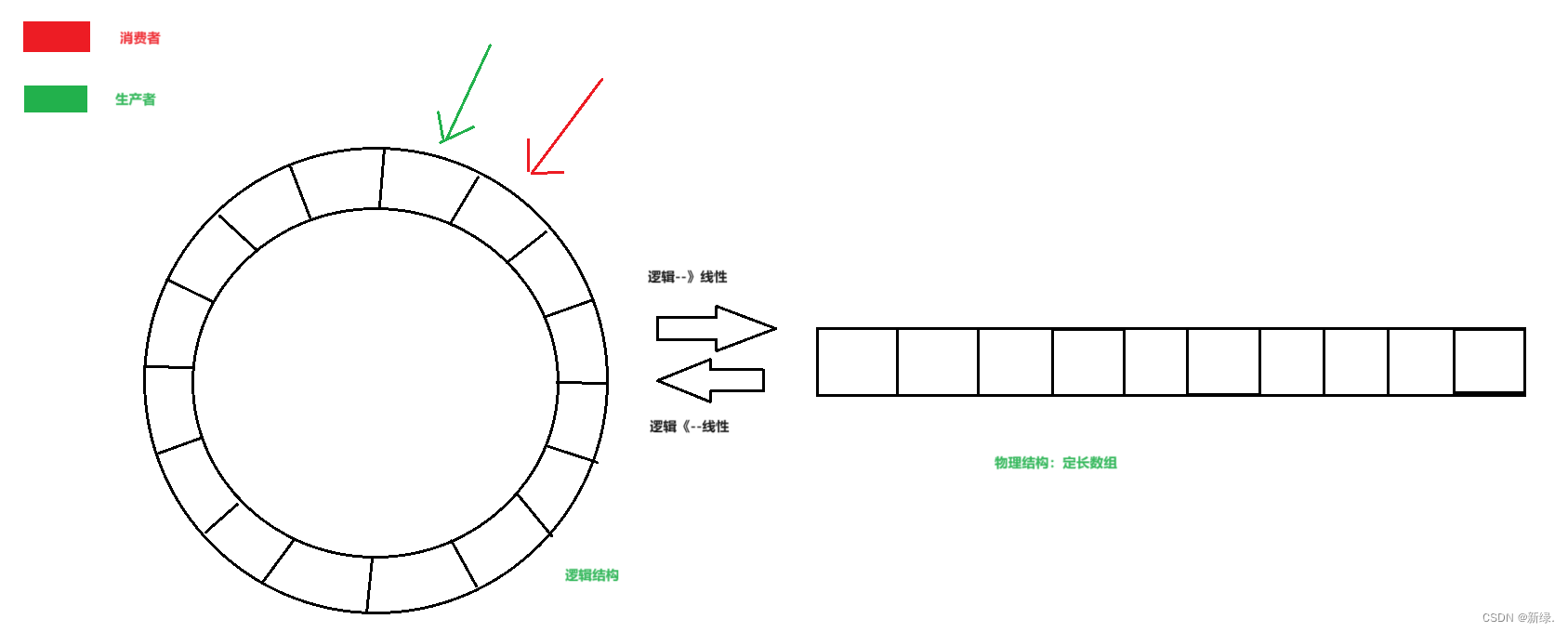
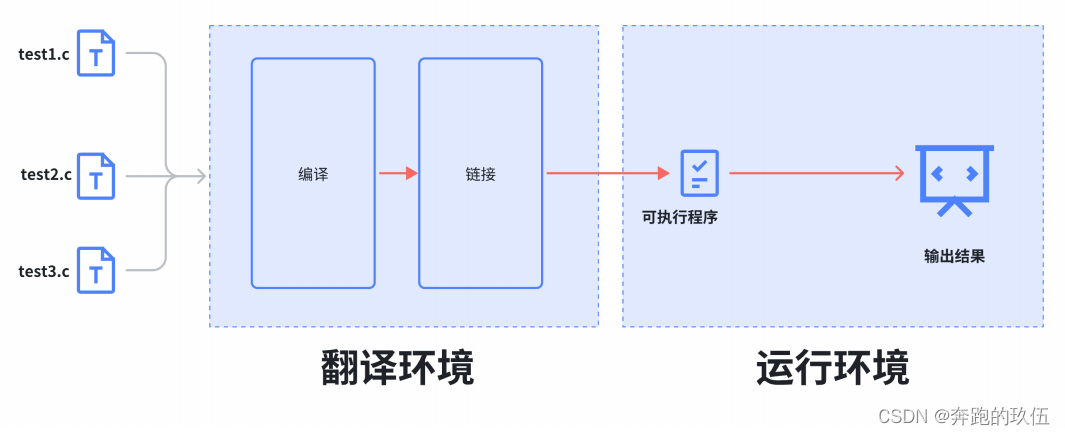
就是在对象里放一个固定长度的数组,然后用两个指针分别指向头、尾,添加或删除元素时,让指针相应的移动一格,移动到超出数组范围时就把指针绕一圈挪到另一头,所以就像是把数组头尾连接变成环形了。
实现
以下是环形缓冲器本身的代码:
#include <cstdint>
#include <cstdlib>
namespace data_basic {
/**
* @brief 精简的环形队列实现
*
* @tparam T 数据类型
* @tparam N 数组长度
*/
template <typename T, size_t N, typename _IndexType = enough_index_type_t<N>>
class RingBuffer {
public:
using IndexType = _IndexType;
private:
T _buf[N];
IndexType _index_back = 0;
IndexType _index_front = _dec_index(0);
IndexType _size = 0;
constexpr IndexType _inc_index(IndexType i) {
if (i == N - 1)
return 0;
return i + 1;
}
constexpr IndexType _dec_index(IndexType i) {
if (i == 0)
return N - 1;
return i - 1;
}
public:
bool empty() const {
return _size == 0;
}
/**
* @brief 填入缓冲区的数据个数
*
* 返回值有可能大于N,表示有旧数据被覆盖。
*
* @return IndexType
*/
IndexType size() const {
// 由于允许头尾指针各自独立生长或收缩,只靠两个指针的相对位置不可能绝对计算出准确的缓冲区尺寸
return _size;
}
size_t max_size() const {
return N;
}
/**
* @brief 缓冲区是否已满
*
* @return false 填入的数据个数大于或等于缓冲区尺寸
* @return true 可以继续安全的填入数据
*/
bool not_full() const {
return size() < N;
}
void clear() {
_index_front = _dec_index(_index_back);
_size = 0;
}
/**
* @brief 尾部追加一个元素
*
* 不检查剩余可用空间,当空间不足时将发生数据覆盖,此时 size() 的返回值可能大于N。
*
* @param val
*/
void push_back(T val) {
_buf[_index_back] = val;
_index_back = _inc_index(_index_back);
++_size;
}
T pop_back() {
_index_back = _dec_index(_index_back);
--_size;
return _buf[_index_back];
}
void push_front(T val) {
_buf[_index_front] = val;
_index_front = _dec_index(_index_front);
++_size;
}
T pop_front() {
_index_front = _inc_index(_index_front);
--_size;
return _buf[_index_front];
}
/**
* @brief 将一个数据重复填入缓冲区指定的次数
*
* @param val
* @param count
*/
void init(T val, size_t count) {
// assert(count <= N, 'Max Size N Can Not Be Exceeded');
while (count--) {
push_back(val);
}
}
T &back() {
return _buf[_dec_index(_index_back)];
}
T &front() {
return _buf[_inc_index(_index_front)];
}
const T& back() const {
return _buf[_dec_index(_index_back)];
}
const T& front() const {
return _buf[_inc_index(_index_front)];
}
};
} // namespace data_basic
介绍
老实说太简单了,没什么好说的。成员函数的命名参考了C++ 的STL,push 和pop 应该不用解释,front 指头部,back 是尾部。举个例子:
data_basic::RingBuffer<int, 10> buf; // 存储int 类型数据的缓冲区,最大容量为10
// 往尾部添加几个元素
buf.push_back(1);
buf.push_back(2);
buf.push_back(3);
// 此时缓冲区内的数据是: [ 1, 2, 3 ]
// 再从头部添加
buf.push_front(-2);
buf.push_front(-3);
buf.push_front(-4);
// 此时缓冲区内的数据是: [ -4, -3, -2, 1, 2, 3 ]
// 从头部删除元素
buf.pop_front(); // 删除并返回-4,结果:[ -3, -2, 1, 2, 3 ]
// 从尾部删除元素
buf.pop_back(); // 删除并返回3,结果:[ -3, -2, 1, 2 ]
老实说,从头部添加元素应该并不是什么常见的需求~ 但是反正加上去也没什么代价。
类里面的IndexType 默认是根据N 计算出来的,如果缓冲区最大长度是10,那只用uint8_t 就足以索引数组中所有元素,最大长度是500 就要用uint16_t,依次类推,算是个节约空间的小花招,主要在Arduino UNO 这种8 位单片机上有点用处,之后再介绍原理。
前面原理中提到“指针” 在代码中实际是用索引代替了,因为更方便。而负责让指针分别向前、后移动一格的是_dec_index 和_inc_index 函数,输入当前索引位置,返回移动结果。
头、尾指针
值得一说的是头、尾指针的初始位置,代码中初始值是:
IndexType _index_back = 0; // 尾指针
IndexType _index_front = _dec_index(0); // 头指针
初始状态缓冲区为空,所以尾指针当然就指向0,但头指针能否同样指向0 呢?
先考虑另一个问题:如果缓冲区是空的,那么push_back 或 push_front 添加的元素能不能在同一处?
答案显然是不能,如果是在同一处,比如,push_back 和push_front 都往索引0 处写入第一个值,那么如果先push_back 再push_front,两函数都往0 处写入,就相互覆盖了。想避免覆盖,要么让头尾指针初始不在同一个位置,要么让push_back 和push_front 的逻辑不一致,我选择前者。
上面代码中能看出,push_back 和push_front 都是先写入再移动指针,而头指针的初始值是0 - 1,实际是绕到缓冲区的倒数第一个位置了,所以,尾部写入第一个元素的位置在0 处,而头部第一个元素在-1。
init
提供了一个方便的成员函数init,可以把一个值重复往缓冲区里添加一定次数,作用就是初始化。更方便的方法或许是提供一个打洞函数,把内部的缓冲区返回给用户,让用户直接初始化里面的值,呃,不太优雅,还是先别这么整。
IndexType 小花招
根据缓冲区大小N 选择索引类型的原理如下:
#include <cstdint>
#include <cstdlib>
namespace data_basic {
namespace _hide {
template <bool fit_in_8, bool fit_in_16, bool fit_in_32>
struct _enough_index_type {
};
template <>
struct _enough_index_type<true, true, true> {
using type = uint8_t;
};
template <>
struct _enough_index_type<false, true, true> {
using type = uint16_t;
};
template <>
struct _enough_index_type<false, false, true> {
using type = uint32_t;
};
template <>
struct _enough_index_type<false, false, false> {
using type = uint64_t;
};
} // namespace _hide
/**
* @breif 根据所需索引的元素数量,选择最小能容纳的整数类型
*
* 若列表最多元素数量为100,则可用uint8_t 索引其中每个元素;若元素数量为1000,则需要用uint16_t。
*
*/
template <size_t Count>
struct enough_index_type {
using type = typename _hide::_enough_index_type<Count <= UINT8_MAX, Count <= UINT16_MAX, Count <= UINT64_MAX>::type;
};
template <size_t Count>
using enough_index_type_t = typename enough_index_type<Count>::type;
} // namespace data_basic
就是个简单的模板特化的技巧,看不懂就算了。
不熬夜了,睡觉。