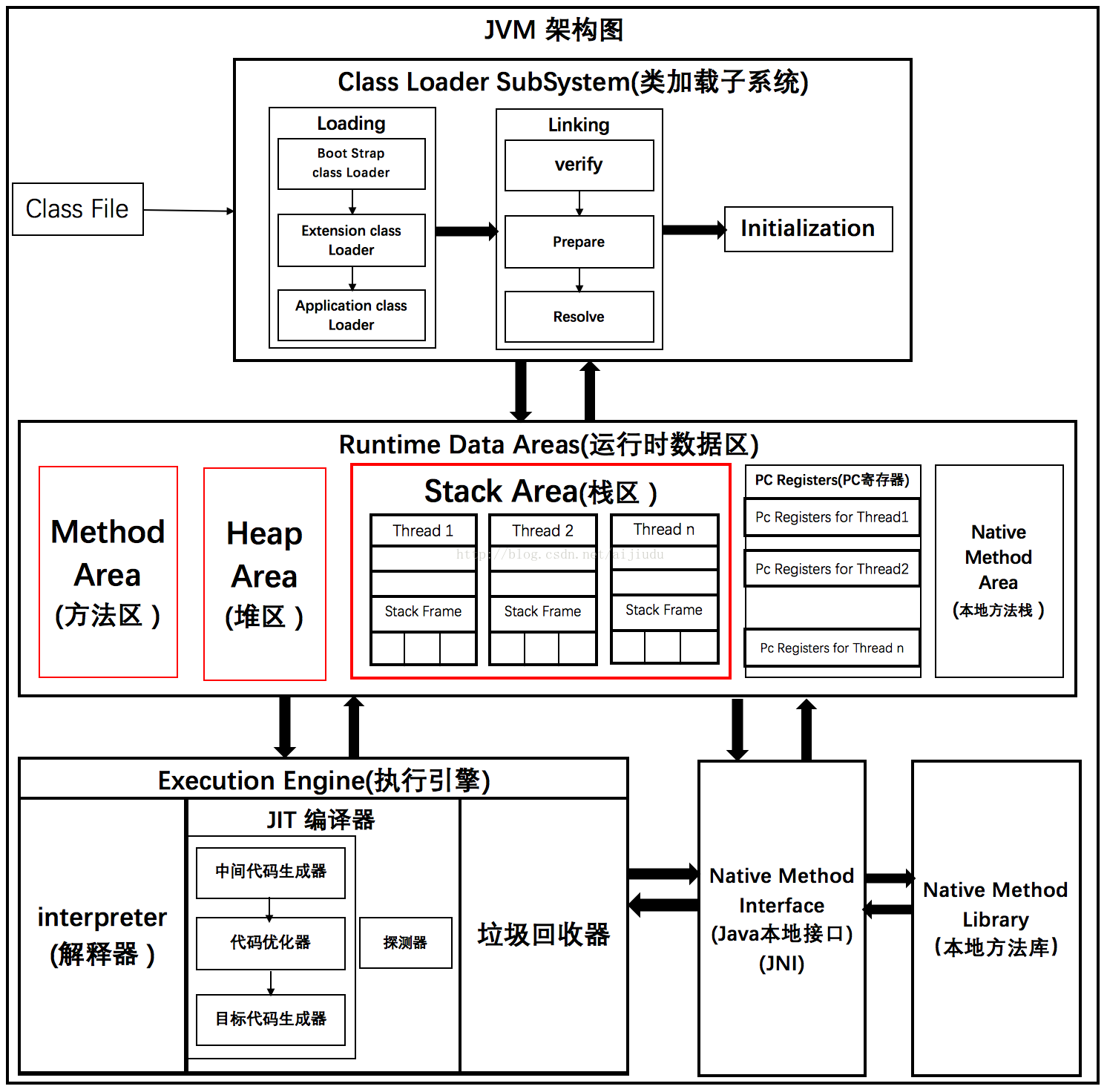
在Spark中,分区(Partition)是RDD(弹性分布式数据集)内部并行计算的一个计算单元。当Spark处理大规模数据时,数据被分割成小块,每小块数据被称为一个分区。这些分区在集群的不同节点上进行分布式处理和存储。每个分区的数据都是RDD的一个子集,可以在一个任务中进行并行计算。
分区的概念对于Spark的并行计算和数据处理至关重要。通过将数据划分为多个分区,Spark能够利用集群中的多个节点进行并行处理,从而提高数据处理的速度和效率。每个分区的数据可以在一个单独的任务中进行处理,而这些任务可以在集群的不同节点上并行执行。
此外,分区还可以帮助优化数据局部性,减少数据在不同节点之间的传输开销。当数据分区与计算任务的分配相匹配时,可以最大限度地利用数据局部性,提高计算性能。
在创建RDD时,可以指定分区的数量和分区策略。例如,使用textFile方法读取文件时,可以指定文件的分区数。Spark会根据指定的分区数将数据划分为相应数量的分区,并在集群中进行分布式处理。