435.无重叠区间
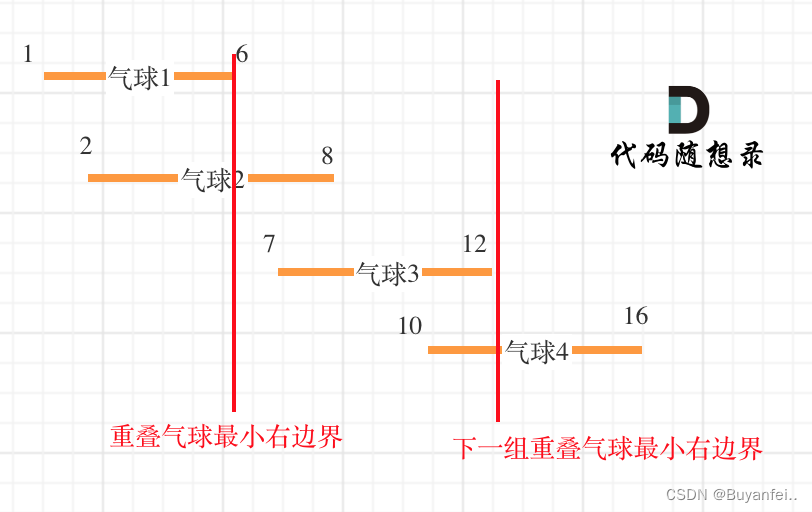
本题与 452.用最少数量的箭引爆气球 的思路类似:若按左边界排序,如果当前区间的 左边界 < 前一区间的 右边界,则说明重叠。此时我们有两种移除选择:
- 移除前一个区间,或者
- 移除当前区间
我们使用贪心策略:为了最小化总体上需要移除的区间数量,我们选择保留结束较早的区间(即右边界较小的区间),因为它留给后续区间的潜在重叠空间更小。
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
intervals.sort(key=lambda x: x[0]) # 按照左边界升序排序
count = 0
for i in range(1, len(intervals)):
# 当前区间的 左边界 < 上一区间的 右边界
# 说明区间重叠
if intervals[i][0] < intervals[i-1][1]:
count += 1
intervals[i][1] = min(intervals[i][1], intervals[i-1][1])
return count763.划分字母的区间
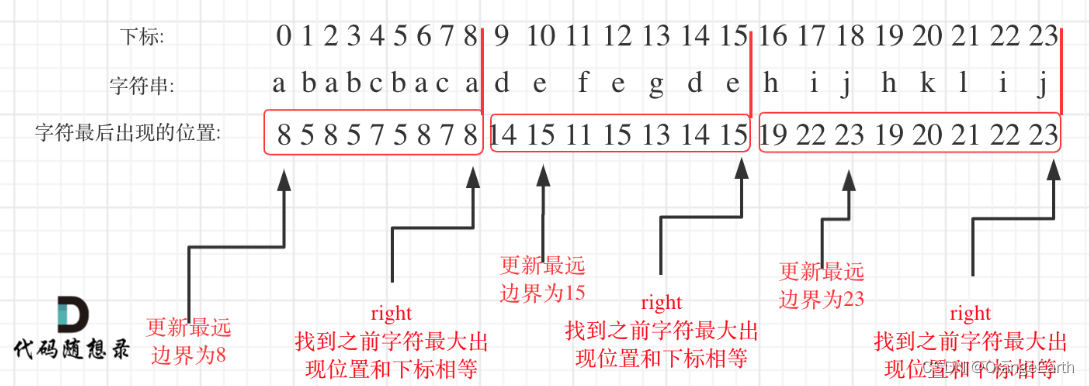
1. 记录每个字符的最后出现位置
算法首先遍历整个字符串,为每个字符记录下它在字符串中最后一次出现的索引位置。这一步是关键,因为要确保一个片段包含了其所有字符的所有出现,这个片段就必须延伸到每个字符的最后出现位置。
2. 确定片段边界
接下来,算法再次遍历字符串,这次是为了确定片段的边界。这通过以下方式完成:
- 为每个正在考察的字符,确定它的最后出现位置(使用之前记录的信息)。
- 使用一个变量
end来跟踪当前片段的潜在结束位置。对于每个新字符,如果它的最后出现位置比当前的end大,就更新end为这个更大的值。这确保了当前片段能包含目前所有已遍历字符的最后出现。- 当遍历到的位置
i等于end时,说明找到了一个片段的边界。此时,可以从start到end的这一段字符串切分出来作为一个独立的片段,因为它包含了这个范围内所有字符的所有出现,且不会与下一个片段重复。3. 更新并记录片段长度
每当找到一个片段的边界时,计算这个片段的长度(
end - start + 1),并将这个长度加入到最终结果的列表中。随后,更新start为end + 1,即下一个片段的起始位置,继续寻找下一个片段直到字符串结束。

class Solution:
def partitionLabels(self, s: str) -> List[int]:
record = {}
res = []
for index, char in enumerate(s):
record[char] = index
end, start = 0, 0
for index, char in enumerate(s):
end = max(end, record[char])
# 说明一个符合条件的区间遍历完成
if index == end:
res.append(end - start + 1)
start = end + 1
return res56.合并区间
思路与 452.用最少数量的箭引爆气球 和 435.无重叠区间 类似:遍历排序后的区间列表,对每个区间,判断它是否与前一个区间重叠。如果不重叠,就直接将当前区间添加到结果列表中。如果重叠,就将前一个区间的结束位置更新为当前区间结束位置和前一个区间结束位置的较大值,从而合并这两个区间。
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key = lambda x: x[0])
res = []
# 需要将第一个区间放入,以便后续合并或加入区间
res.append(intervals[0])
for i in range(1, len(intervals)):
# 注意区间紧挨也要合并
if res[-1][1] >= intervals[i][0]:
res[-1][1] = max(res[-1][1], intervals[i][1])
else:
res.append(intervals[i])
return res