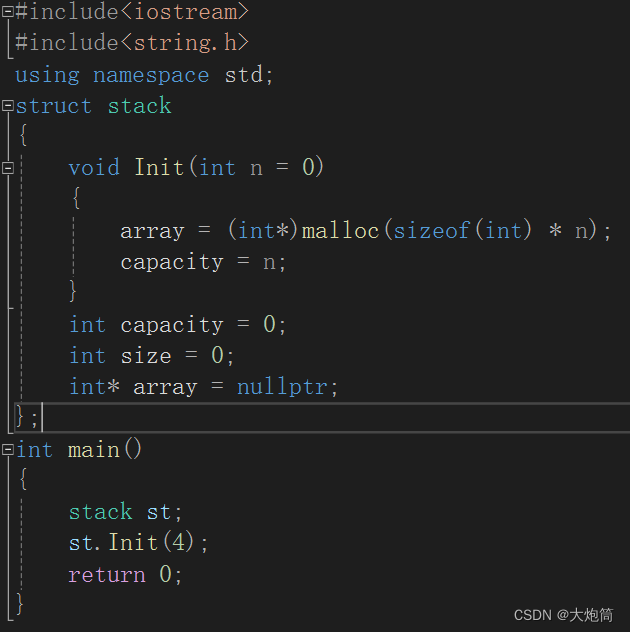
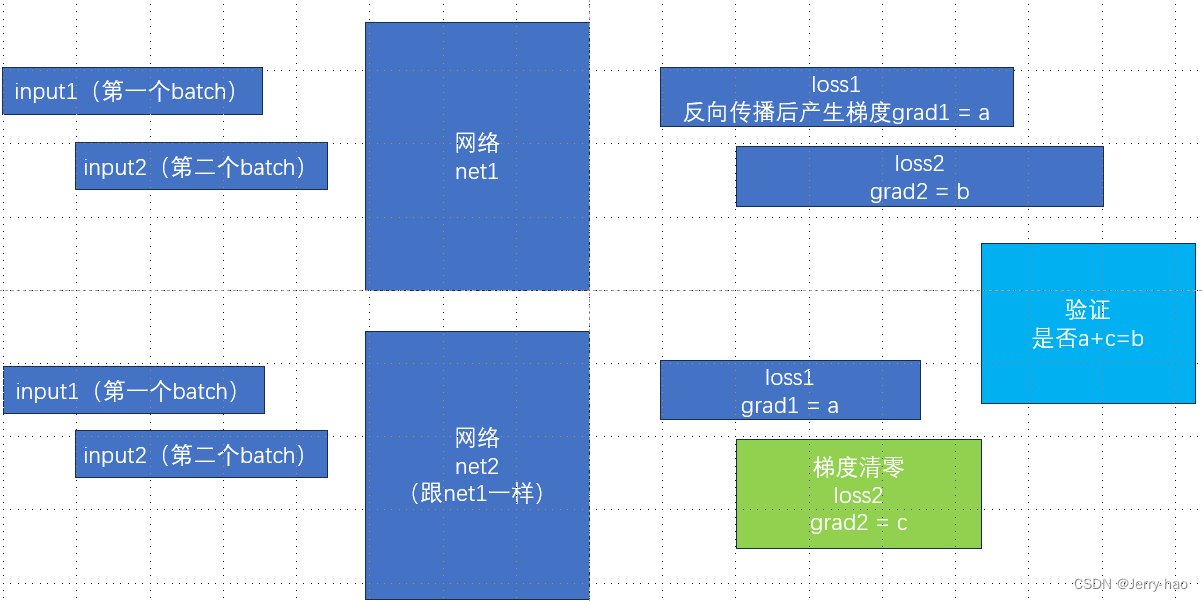
通常,在神经网络训练中,是在每个 mini-batch 处理完成后清空一次梯度,而不是在每个 epoch 结束后清空一次梯度。
这是因为在每个 mini-batch 中,模型参数的梯度是根据当前 mini-batch 的损失计算得到的,如果不在每个 mini-batch 后清空梯度,梯度会在每个 mini-batch 中累积,导致参数更新不准确。
因此,通常的做法是在每个 mini-batch 处理完成后调用优化器的 .zero_grad() 方法来清空梯度,以便接收下一个 mini-batch 的梯度信息。
在训练过程中,一个 epoch 包含多个 mini-batches,完成一个 epoch 后,模型会遍历整个训练数据集一次。在每个 epoch 开始时,一般会打乱数据集的顺序以增加模型的泛化能力。
.zero_grad()方法
.zero_grad() 是优化器对象的方法,用于将所有参数的梯度清零。
在每次进行反向传播之前,通常会调用 .zero_grad() 方法来清空之前累积的梯度信息,以准备接收新一轮的梯度信息。这样做可以确保每次参数更新只基于当前批次的梯度,而不受之前批次梯度的影响。

















![[学习笔记]pytorch tutorial](https://img-blog.csdnimg.cn/direct/c57562636c59485f8dd6c445dac0577e.png)