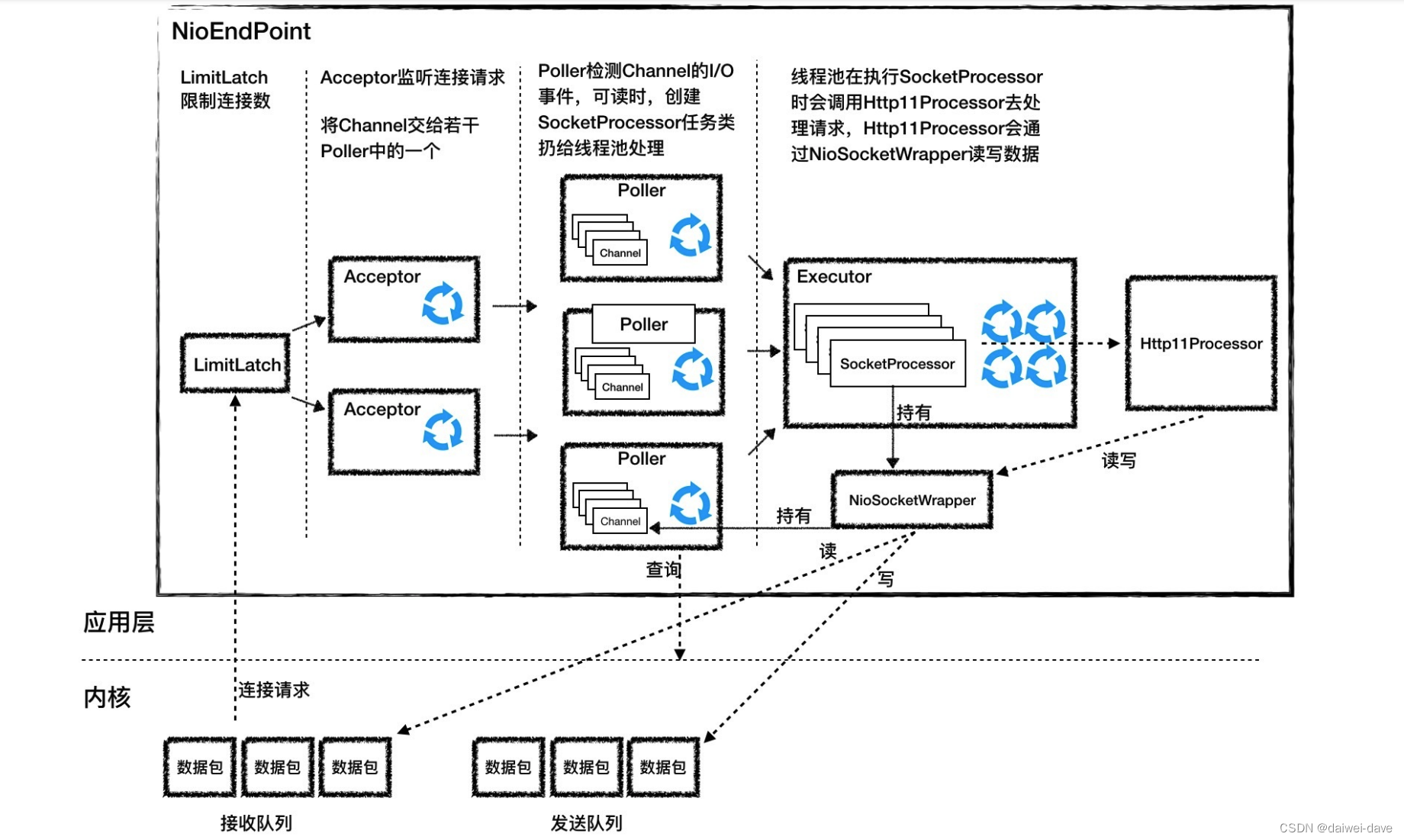
数 据 传 输
摘 要
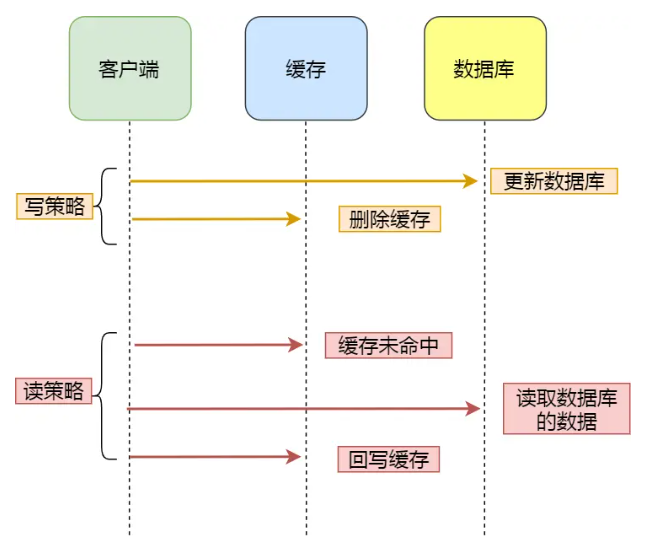
本系统对语音信号采用时域处理方法:数据采集直存直取、欠抽样采样、自相似增量调制法等三种方法,分别完成了对语音信号32.7秒、65.5秒、147.4秒的存储与回放;前置自动增益控制(AGC)将语音信号控制在A/D转换器可处理的范围内以保证话音采样不失真;带通滤波器合理的通带范围有效地滤除了带外噪声,减小了混叠失真;通过后级补偿电路对输出的语音信号进行了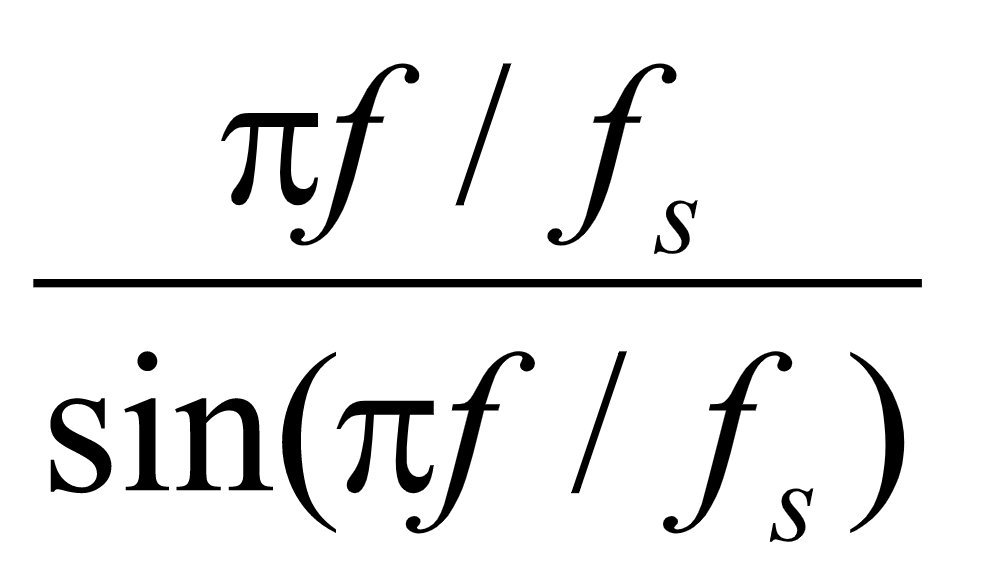 校正,回放语音清晰;并具有自动录音、手动录音、录/放音时间显示以及掉电后保护语音信号等功能。
校正,回放语音清晰;并具有自动录音、手动录音、录/放音时间显示以及掉电后保护语音信号等功能。
方案设计与论证
本题目是设计制作一个数字化语音存储与回放系统。要求前置放大器的增益为46dB,增益可调;带通滤波器,带宽为300Hz~3.4kHz;ADC采样频率fs=8kHz,字长=8位;语音存储时间≥10秒;DAC变换频率fc=8kHz,字长=8位;且要求回放语音质量好(话音清晰、失真小、杂音少)。方案考虑如下。
语音编码方案论证
语音是一维时间信号,由于是表示语言声音的信号,所以不是恒定的,信号的性质随时间变化很大。为了充分利用有限的存储空间,并不失真地传送语音信号必须对采集后的语音信号进行进一步压缩,即语音压缩。所谓语音压缩,是为了声音信号更大信息量的传送与记忆而压缩数据,并有效地回放声音的过程。语音压缩可由将语音信号采集,并利用适当的量子化形式的压缩符号化或预测符号化等进行。
现代常用的语音信号表示方法如用生成模的参数表示声音时,参数的数据率为5K比特/秒左右,与波形符号化相比,参数表现的数据率显著变低,若使用声音生成模,则以利用声音信号分析而得的模的参数为基础,可进行声音的再合成。在听觉上得到的与原声音没有多少不同的合成声音。参数的数据率为信号波形数据率的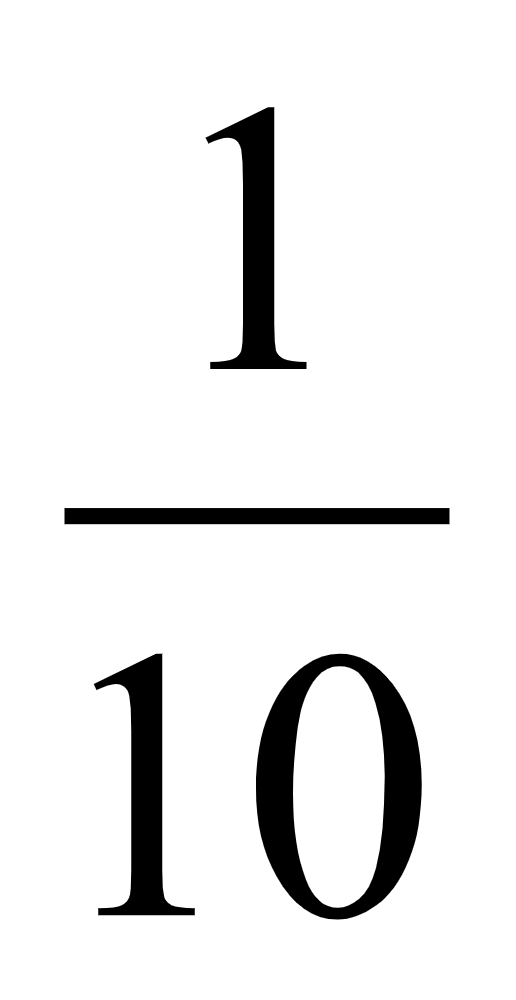 以下, 所以可进行高效的声音数据压缩。
以下, 所以可进行高效的声音数据压缩。
单从声音的存储与压缩率来考虑,生成模参数表示法明显优于信号波形表示法。但要将之应用于单片机,显然信号波形表示法相对简单易实现,具有很强的可行性。故方案的设计均从声音信号以波形存储来考虑。基于这种思路的算法,除了传统的一些脉冲编码调制外,目前已使用的有VQ技术及一些变换编码和神经网络技术,但是算法复杂,目前的单片机速度低,难以实现。结合实际情况,提出了以下几种可实现的方案。
短时平均跨零计数法
该方案通过确定信号跨零数,语音信号编码为数字信号。该方案主要应用于语音识别中,具有较小的回放失真,音质较好。但对于现用单片机,处理数据能力低,故该方法不易实现。
实时幅值采样法
采样过程如下图所示:

直存直取法
该方案将话音信号的抽样值直接存取,以保证在回放时能真实的重现抽样值。由于这种方法重现的是采样的真实值,所以只存在一般量化噪声,与A/D转换精度有关。故此方法回放质量最好,但占用存储空间也最大,编码速率为62.5kBit/s,每采集1秒钟的话音信号需占用7.8125K字节。由于我们扩展了256K字节的RAM,故采用这种方法作为不压缩的存储,音质好,录音可达32.768秒。该方法示意图如图1:

图1
注:该方法中的量化台阶为10H,图中70H、80H、70H、60H、50H、40H、50H、 70H、 90H、C0H、D0H、D0H为所要存储的值,解码后所输出的值为:70H、 80H、70H、60H、50H、40H、50H、70H 90H、C0H、D0H、D0H
欠抽样采样法
虽然语音信号频谱在高频处迅速下降,但语音信号并非固有的频带受限。对于浊音来说,超过4kHz频率的频谱比其峰值要低40dB以上。另一方面,对于清音,即使超过8kHz,频谱也没有显著下降。因此为了精确的表示所有语声,常常需要大于20kHz的抽样率。然而,在大多数应用中不需要这样高的抽样率。通常我们只要有3.5kHz以下的频谱足以清晰地传输话音信号,即8kHz的采样速率足矣,通常的“电话语音”就是用4kHz的奈奎斯特频率实现的。因此可以8K的采样速率对话音信号采样,而存储时采用奇存法,即只存奇数点而抛弃偶数点,回放时在两相邻奇数点之间的偶数点只需用两数的平均值代替即可。这样既保留语音信号的主要部分,使回放的音质较为理想,又提高了存储器的利用率,理论计算录音时间可达65.536秒,数据压缩率为1:2。但是,由于这种方法的采样速率实际上只有4kHz,故在回放时会产生一定的失真。该方法示意图如图2所示

图2
注:图中70H、70H、50H、50H、90H、D0H、为所要存储的值,解码后所输出的值为:70H、70H、70H、60H、50H、50H、50H、70H 90H、B0H、D0H
自相似增量调制法
从典型的语音信号可以看到,语音信号的特征是随时间而变化的,在大多数语音处理方案中,基本的假定为语音信号特性随时间的变化是缓慢的。这个假定导出各种“短时”处理方法,在这里语音信号被分隔为一些短段再加以处理。这些短段就好像是来自一个具有固定特性的持续音片断一样。这些短段一般都按要求重复(常是周期性的)。这些有时称为分析帧的短段彼此经常有一些叠接,对每一帧的处理结果或是一个数或是一组数。所以,经过处理以后产生一个新的依赖于时间的序列而用于描述语音信号。
这种短时处理技术,可以表示成数学形式

对语音信号(或者是经线性滤波后滤出所要求的频段)做变换T[],该变换可以是线性的,也可以是非线性的,它可以依赖于某个可调参数或一组参数。然后把所得到的序列乘以窗序列,这个窗序列位于与抽样标志n相一致的时间上,最后对乘积的所有非零值求和。通常窗序列宽度是有限的,当然不总是这样。所以Qn值就是序列T[x(m)]的部分加权平均值的序列。短时分析原理的一般表示如图3所示。
 图3
图3
利用语音信号的短时平稳性及波形自相似的特点,本系统提出自相似增量调制法,该方法是以8K的采样速率,在采样过程中,以每九个相邻采样点为一组,每组中对第一个采样值保存其真实值,而其余的采样值采用增量调制的方法生成一个字节保存,这样,每一组共占用2个字节。数据压缩率为1:4.5。该方法既有
ΔM调制的优点,又同时兼有PCM编码误差较小的优点,编码误差不向后扩散。编码示意图如图4:

图4
注:图中所示增量为σ=10H,所存数据为70H,87H(10000111B),C0H,...其中,70H和87H组成上述的一组,70H为一组中的第一点,是真实的采样值,87H是增量调制后的编码,它的每一位都表示了曲线的变化趋势,增量调制用一位码表示相邻抽样值的相对大小,而相邻抽样值的相对变化同样能反映模拟信号的变化规律。只要时间间隔Δt和台阶σ都很小,则m(t)和m’(t)将会相应的接近。解码后所输出的值为:70H、80H、70H、60H、50H、40H、50H、60H、70H、C0H、D0H...
由于使用了ΔM调制使系统产生了过载量化噪声,过载量化噪声(有时简称过载噪声)发生在模拟信号斜率陡变时,由于台阶σ是固定的,而且每秒内台阶数也是确定的,因此,阶梯电压波形就跟不上信号的变化,形成了很大失真的阶梯电压波形,这样的失真称为过载现象,也称为过载噪声。
A/D、D/A及存储器芯片的选择
1.A/D转换芯片的选择
根据题目要求采样频率fs=8 kHz,字长=8位,可选择转换时间不超过125 μS的8位A/D转换芯片。当前常用的A/D转换的实现方法有多种:积分式、逐次逼近式、并行比较式和二进制斜坡式(又称计数式)、量化反馈式等。鉴于转换速度的要求,最适合本题使用的是逐次逼近式转换器,它具有转换速度较快、转换精度较高的特点,一次转换时间在数微秒至百微秒范围内。其中ADC0809是目前使用较为广泛的通用8位A/D转换芯片。它的转换时间小于120 μS,模拟输入为0 ~ 5 V,基本上可以满足题目的要求,但由于要实现自动录音,需要数微秒级的转换时间才能达到良好的效果。因而我们采用了12位逐次逼近式A/D转换芯片AD1674。它的转换时间小于10 μS,可编程为8位A/D转换工作方式,而且其可输入±5V的模拟信号,故无需在前级增加电平抬高电路,可减少因通过一级电路后引起的信号失真以及系统噪声。
2.D/A转换芯片的选择
D/A转换器的作用是将存储的数字语音信号转换为模拟语音信号,由于一般的D/A转换器都能达到1μS的转换速率,足够满足题目的要求,故我们在此选用了通用D/A转换器DAC0832。AD1674、DAC0832与单片机的连接如图5所示

图5
3.数据存储器的选择
当采样频率fs =8kHz,字长为8位时,按照1:1的存储率,一秒钟就能采样8000个点,为了能够存储多于10秒钟的语音,则存储器至少需要有78.125K×8的容量。在此我们选用了两片IS61C1024将存储容量扩展为256K×8,这样就能以1:1的存储率存储32.768秒语音信号。电路图如图6所示

图6
放大器的设计
作为语音放大器的前端放大器,有以下几点要求:
低噪声,高增益。
有较大的动态范围。
失真度小。
前端放大器:
系统要求放大器增益为64dB,由于驻极体生成的语音信号 较大,在此我们选用动圈型拾音器。为了保证录音质量,语音信号应保证满量程模数转换,所要录制的声音大小可能相差很大,因此AGC电路至关重要,所以我们将放大器做成低噪声、自动增益控制(AGC)兼手调增益型放大器。
在此选用低噪声高压摆率的运放NE5532作为放大器,对信号进行多级放大:缓冲放大、放大、调整放大,其中放大环节包括AGC和手动增益调节,且两种方式可自由切换。
后端放大器:
为了保证耳机和外放都能正常工作,语音信号的输出应有一定的输出功率,在此选用两级放大,第一级为信号放大,第二级为功率放大,由于功率放大器有较大的噪声,在使用耳机工作时需输出的功率较小,可只对语音信号进行信号放大,因此我们选用两种工作方式:信号放大、功率放大,这样既保证了使用外放的使用,又不增加耳机工作的系统噪声。
在该系统中,有两处用到放大器,增益分别为46dB和40dB,且增益均可调,既可用专用放大器实现,也可用分离元件实现,综合考虑实际应用与性价比,我们采用分立元件实现。注意到发挥部分要求减少系统噪声电平,增加自动音量控制,所以我们将放大器做成低噪声、自动增益控制(AGC)兼手调增益型放大器。
(四)滤波器的设计
为了滤除音频信号中不必要的杂波,必须在数据采集前端放置滤波器,以尽可能滤除噪声干扰与混叠失真。这里将通频带设为300Hz~3400Hz,选用分立元件构成的有源滤带通Butterworth滤波器,其性能优于集成滤波器。
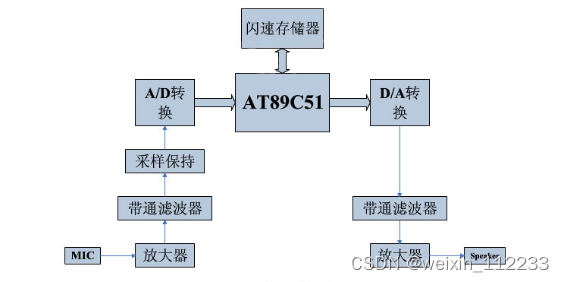
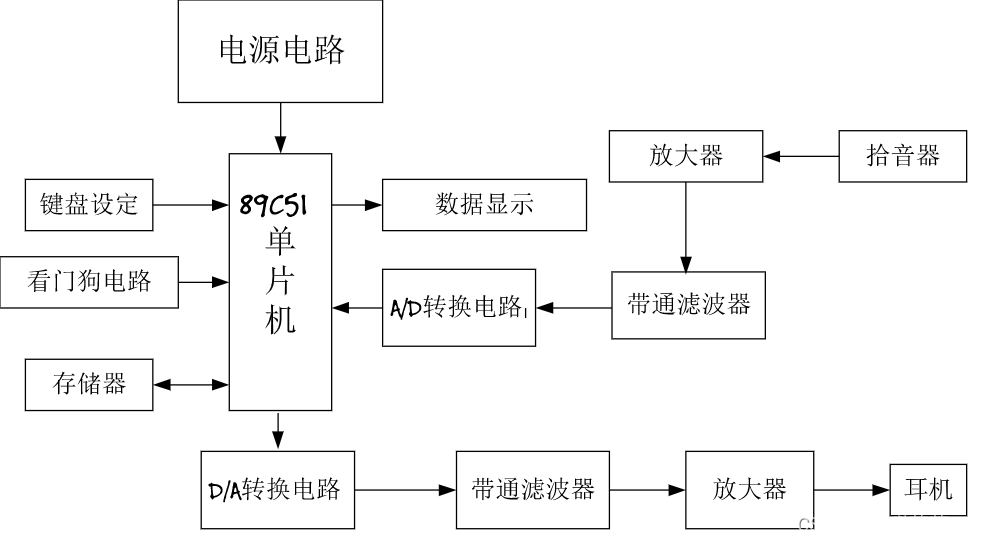 整个系统框图如图7所示。
整个系统框图如图7所示。
图7
理论分析与计算
放大器设计
这里由NE5532构成的增益放大器,增益可达64dB, 可手动调节与自动调节,手动调节时KEY与端点2连接,通过调节电位器R9改变2N7000栅极电压来调整增益,增益的达64dB且连续可调,当KEY与端点1连接时,增益可自动调节,输入信号小可到几毫伏,线性动态范围为40dB,输出OUT一直稳定在10Vp-p,电路如图8所示:

图8
该增益放大电路由三级运放组成:
第一级为缓冲放大,对语音信号进行缓冲,增益为:
第二级包括AGC和手动增益调节电路,增益为:
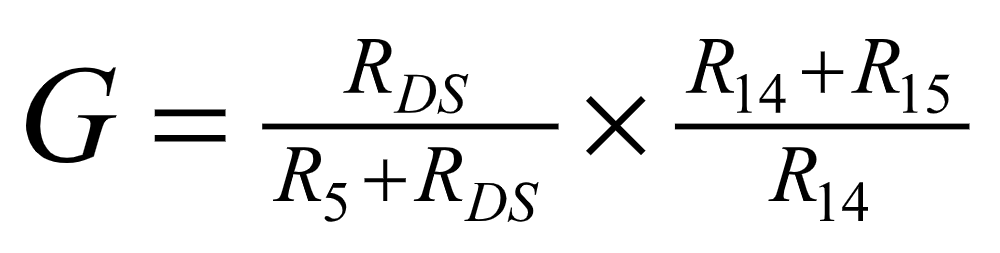
RDS 为2N7000的导通电阻,由2N7000栅极的电压决定,三极管9012构成的检波电路对第二级放大器构成了负反馈,使输出电压稳定。
第三级为调节放大,调节输出信号Vp-p=10V,即保证A/D满量程转换,增益为:
采样输出放大器:经带通滤波器输出的声音回放信号,其幅度
为0~5V,足以用耳机来收听,故不用接任何放大器。而考虑到实际中经常会用到喇叭外放,故在本系统中增加外放功能,前端放大器采用通用型音频功率放大器LM386来完成。电路如图9

图9
该电路为增益50~200连续可调,最大不失真输出功率为325mW。输出端接C2,R2串联电路,以校正喇叭的频率特性,防止高频自激。脚7接220μF去耦电容,以消除低频自激。为便于该功放在高增益情况下工作,这里将不使用的输入端脚2对地短路。
(2)有源带通滤波器设计
声音信号经动圈拾音器转化成电压信号,通过前级放大,在对其进行数据采集之前,有必要经过带通滤波器滤除带外杂波。选定该滤波器的通带范围从300Hz到3.4kHz。其作用:
(1)保证300~3400Hz的语音信号不失真的通过滤波器;
(2)滤除带外的低频信号,以减少带外工频等分量的干扰,大大
减小噪声影响,该下限频率可下沿到270Hz左右;
(3)便于滤除带外的高次谐波,以减小因8K采样率而引起的混
叠失真,根据实际情况,该上限频率可在2700Hz左右;带
通滤波器按品质因数Q的大小分为窄带滤波器(Q>10)和
宽带滤波器(Q<10)两种,本题中,上限频率fh=3400Hz,
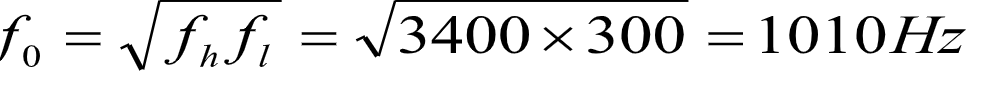 下限频率 fl=300Hz,通带滤波器中心频率:
下限频率 fl=300Hz,通带滤波器中心频率:
品质因数Q:
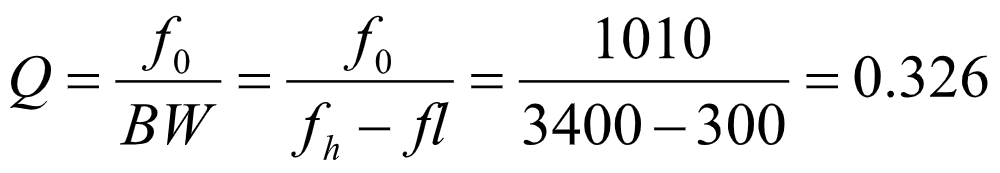
显然,Q<10,故该带通滤波器为宽带带通滤波器。
宽带带通滤波器由高通和低通滤波器级连构成,鉴于Butterworth滤波器带内平坦的响应特性,该题中,我们选用二阶Butterworth带通滤波器,电路如图10所示:
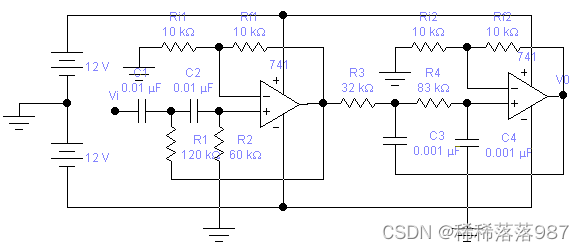 图10
图10
图种阻容值的确定按下述步骤进行:
(1) 设放大倍数为4,则选Ri1=Ri2=Rf1=Rf2=10K;
(2) 带通滤波器的前半部分(高通滤波器)阻容值的确定:
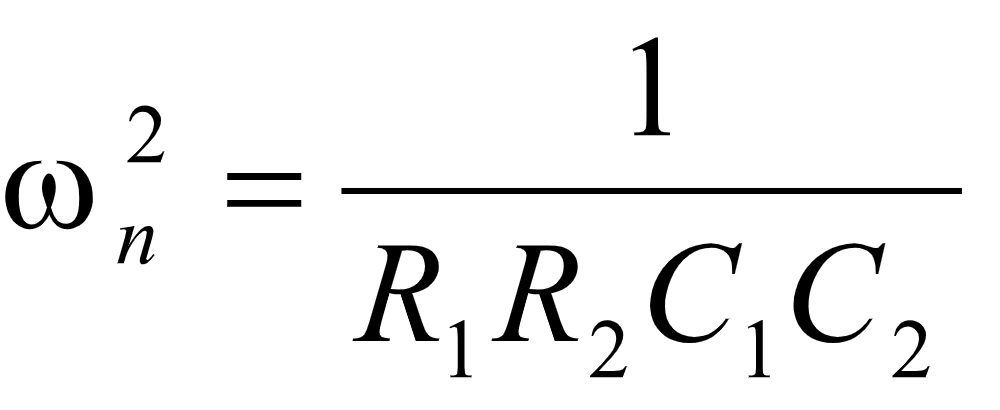 由于自由振荡角频率:
由于自由振荡角频率:
阻尼系数 :

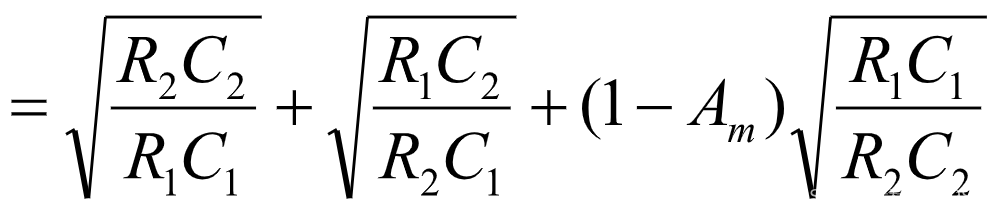
当下限频率fl=280Hz时,取ξ=1.414,C 1=C2=0.01μF,Am=2
带入上两式得R1、R2 理论值:R1=82K,R2=41K;
选标定值,则R1=120K,R2=60K;
(3)带通滤波器后半部分(低通滤波器)阻容值的确定:
与(2)中阻容值的求法相似,不同处仅上限频率fh=3.4K,C3=C4=0.001μF,求得R3、R4理论值:R3=33K,R4=66K;
结合实际情况,取标定值,则:R3=32K,R4=83K;
仿真结果如图11、12所示:
· 3dB下限频率fl=298Hz
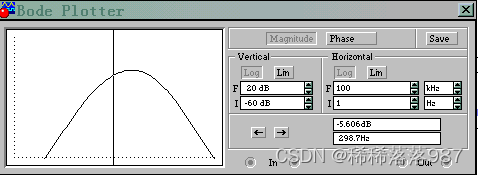
图11
·3dB上限频率fh=3.2KHZ
 图12
图12
实验证明,该滤波器能有效地滤除低频分量,大大减少噪声干扰,与之同时也滤除了多余的高频分量,消除了混叠失真,性能足以满足要求。
(3)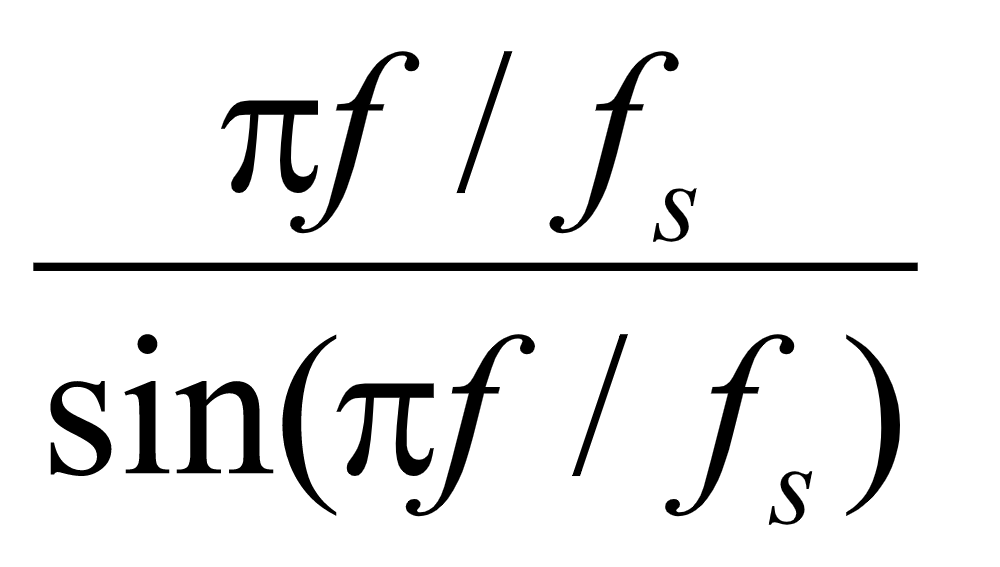 校正
校正
系统中的数模转换采用DAC0832,该芯片完成数字信号到模拟信号的转换。从D/A转换的过程来看,其作用是首先通过解码将数字信号转换成时域离散信号,再经过零解保持器和平滑滤波,最后得到模拟信号(话音信号),恢复过程如图13所示:

图13
零阶保持器的作用是将前一个取样值保持到下一个取样时刻,因此相当于常数内插。零阶保持器的单位冲击函数h(t)以及输出波形如图14所示。
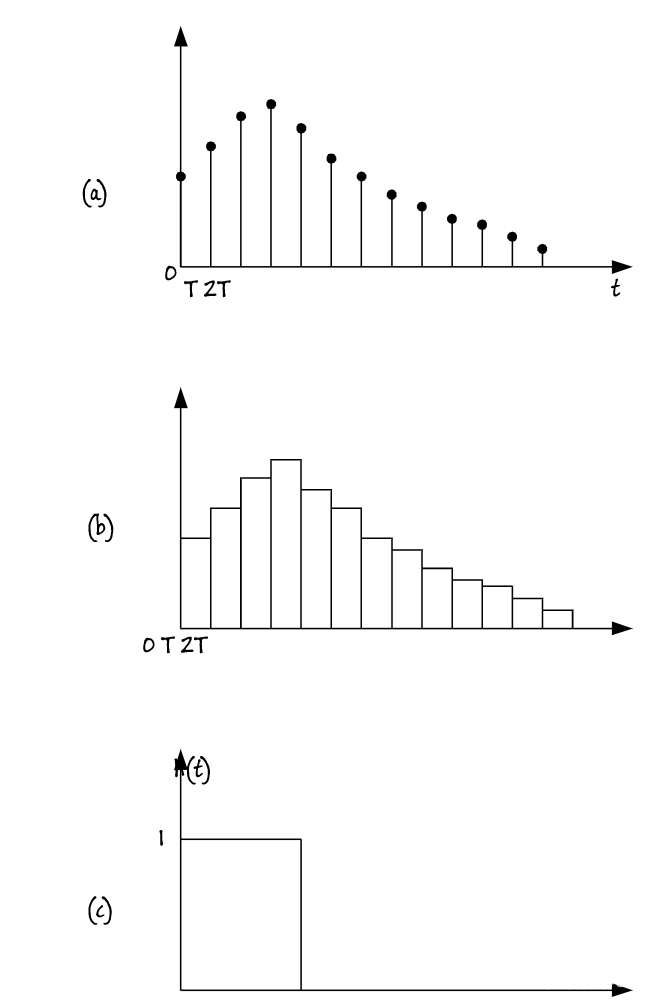
图14
对h(t)进行傅里叶变换,得到零阶保持器的传输函数H(jΩ)

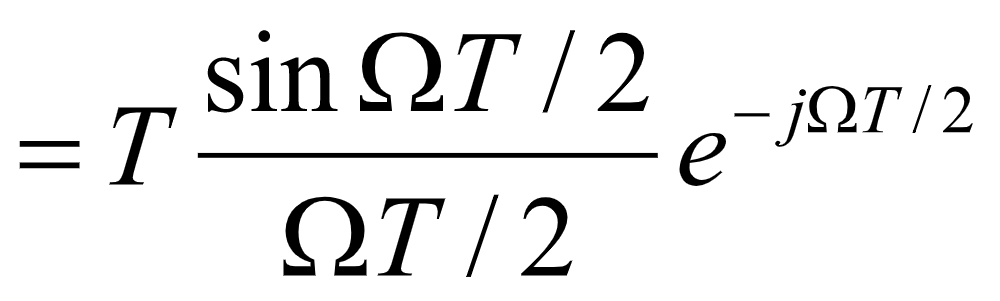
其幅频特性如图15所示:
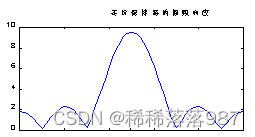
图15
由图看到,零阶保持器是一个低通滤波器,能够起到将采样信号恢复成模拟信号的作用。由于零阶保持器的幅度特性与理想低通滤波器的幅度特性有明显差别,主要是在|Ω|>π/T区域有较多的高频泄漏,表现在时域图上如图14的(b)所示,波形有阶梯不够平滑。因此需要在D/A变换后,加模拟低通滤波器,滤除不必要的高频分量,对波形起平滑作用,该模拟滤波器也称平滑滤波器。
经过上述处理的话音信号,具体实现后与原声对比可知:处理后的信号失真较小。从另一个方面考虑上述处理过程,零阶保持器在将采样信号恢复成模拟信号的同时,由于低通的作用,对信号加了一个小的相移, 由于人耳对相位的失真是不敏感的,故不考虑相位的滞后;除此以外,还对高频少部分信号进行了不应有的衰减,增大了信号的失真,若能将这部分衰减进行补偿,则可使话音信号的失真进一步减小。鉴于此,我们对零阶保持器传输函数H(jΩ)中因Sa函数而引起的衰减进行补偿,即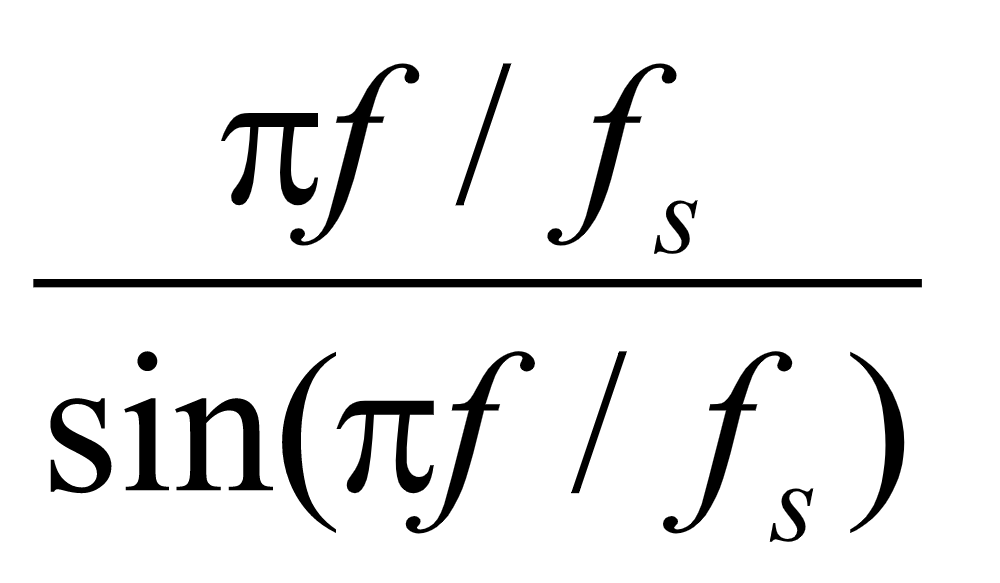 校正,具体方法如下:
校正,具体方法如下:
首先对频域中的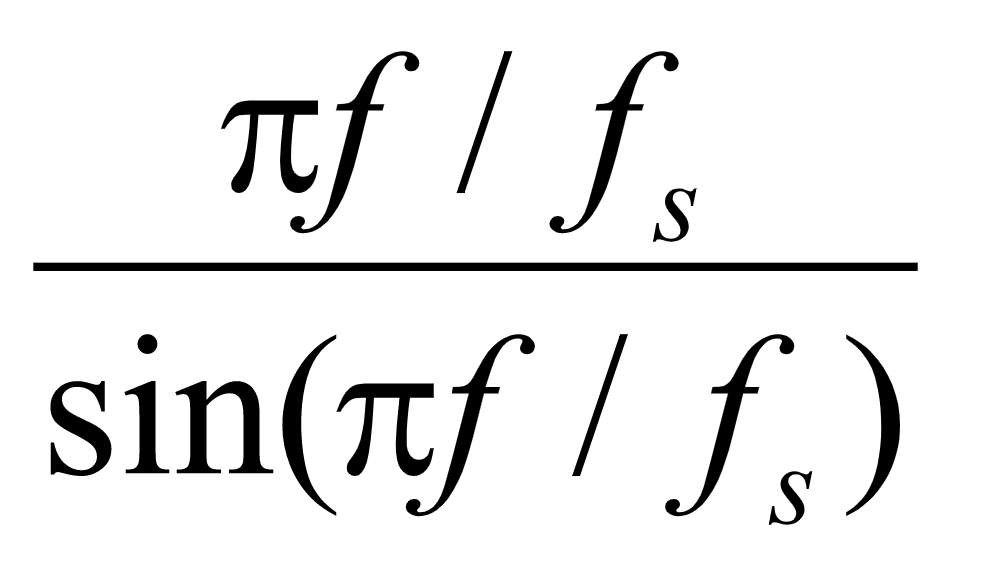 函数进行分析,
函数进行分析,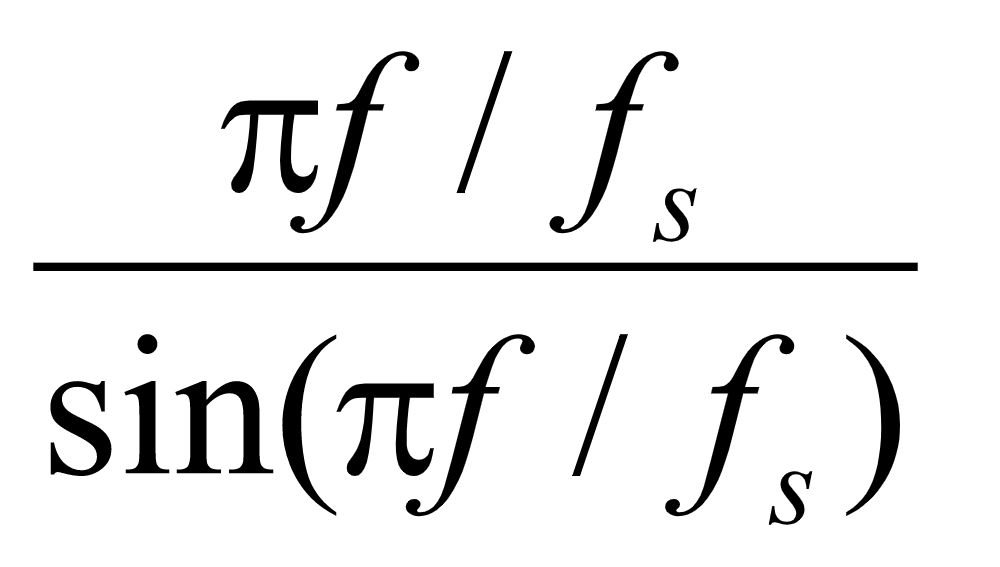 在频域30~4030HZ范围内的曲线如图16所示:
在频域30~4030HZ范围内的曲线如图16所示:
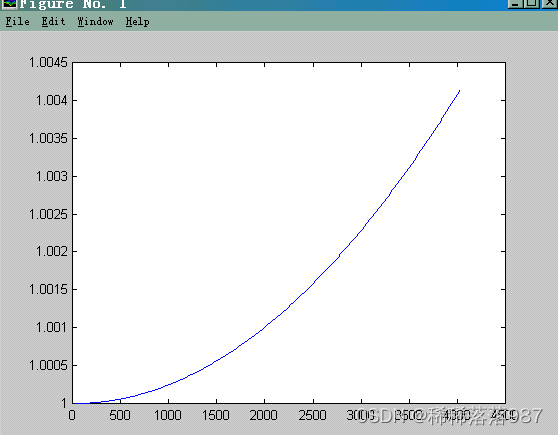
图16
由图可见,它近似于阻带内增益变化极为缓慢的阻带内近恒定增益的高通滤波器;进一步分析可知,该曲线在频率很高处有大幅度的下降,故可用带通滤波起来拟和该曲线,由于受单片机数据运算处理能力(0.5MPS)的限制,数字滤波不易实现,故这里采用硬件滤波,滤波电路如图17所示:
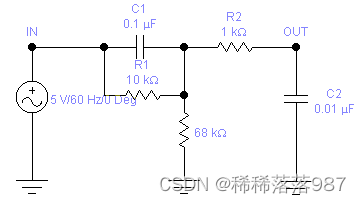 图17
图17
该滤波网络采用简单的无源滤波网络即可实现,图中C1、R1构成初始放大倍数近乎恒定的网络,观察到 在频率 较高处有大幅度的衰减,故该网络还应满足在频率较高处的衰减 特性,考虑到对于声音信号,过多的高频分量只能增加噪声,所以后接R2、C2构成低通滤波器,截止频率合理的设在3.4k±100HZ。仿真结果如图18、19所示:
在频率 较高处有大幅度的衰减,故该网络还应满足在频率较高处的衰减 特性,考虑到对于声音信号,过多的高频分量只能增加噪声,所以后接R2、C2构成低通滤波器,截止频率合理的设在3.4k±100HZ。仿真结果如图18、19所示:
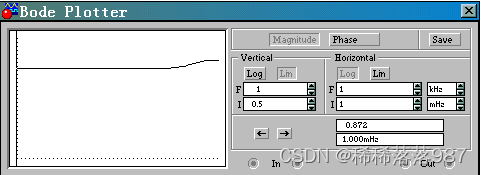
图18
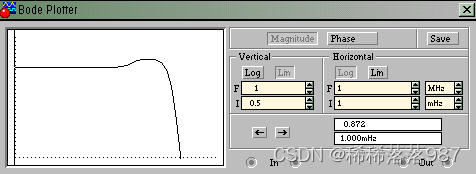 图19
图19
由仿真结果可知,该网络在频域由30Hz起,增益缓慢增大,从3.4kHz处幅频响应大幅度降底,曲线拟和较好,补偿了Sa函数。
软件设计流程
系统软件总体流图见图20、21所示。
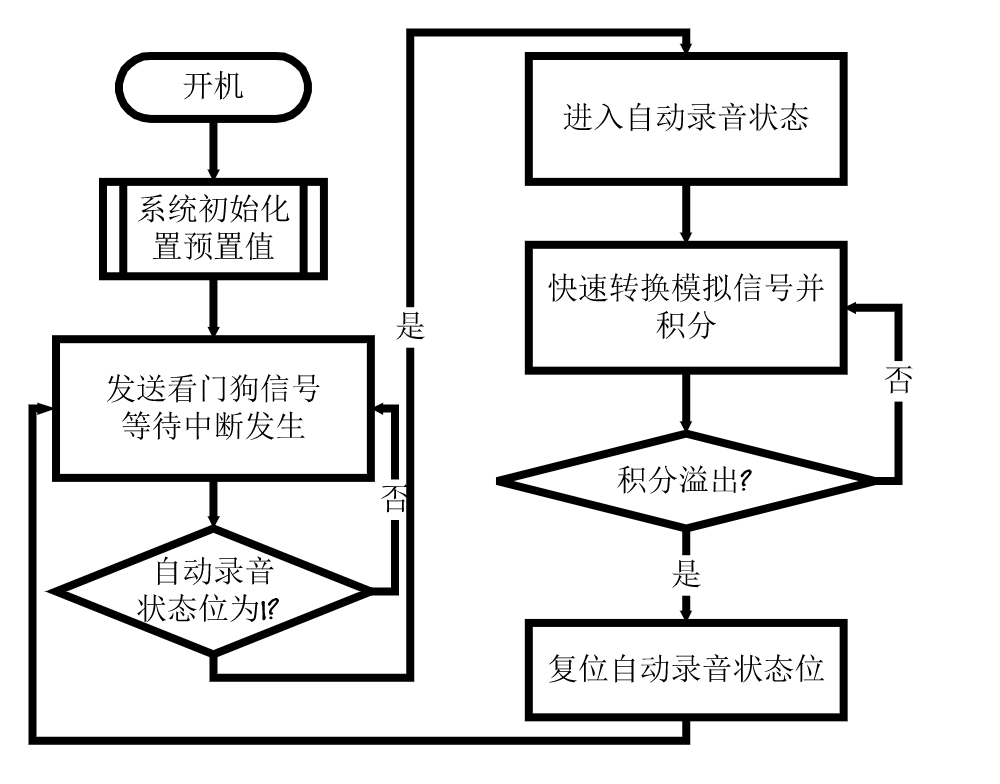
图20
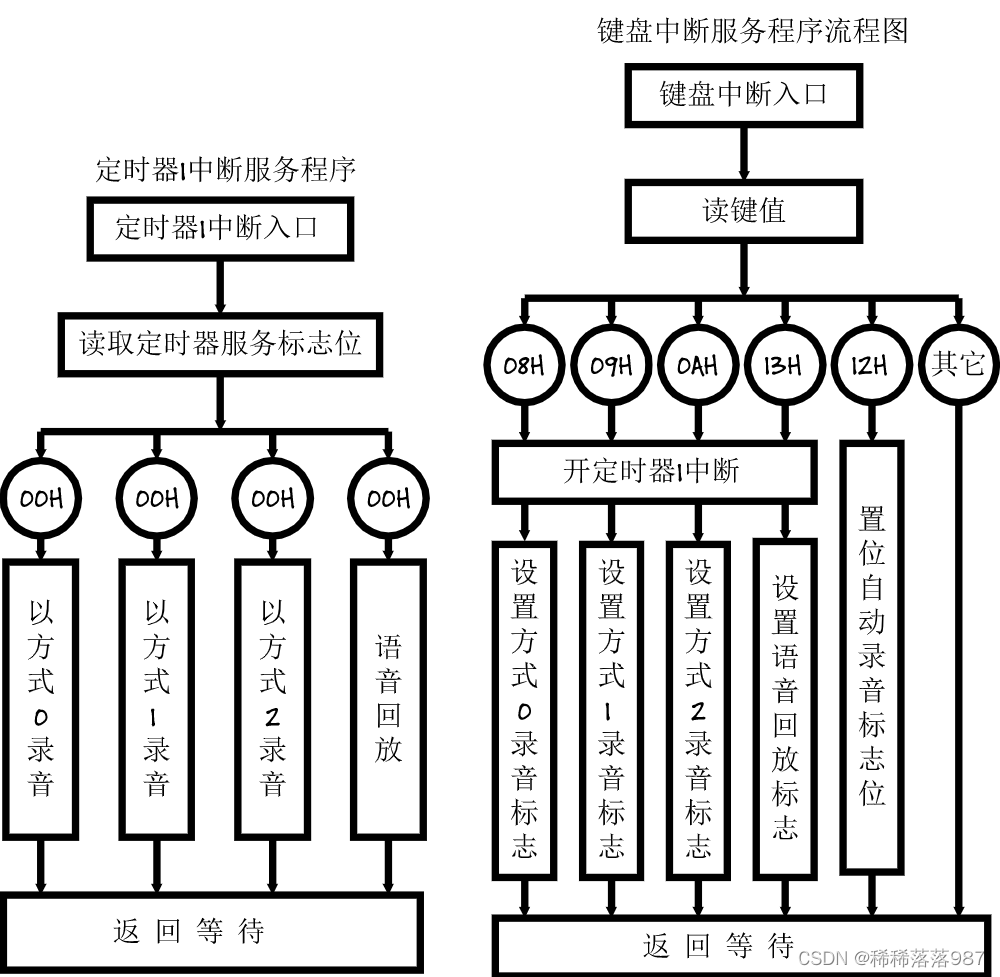
图21
其它功能的实现:
良好的人机界面:
系统工作状态由数码管显示,系统状态的转换有键盘控制包括三种处理方式的切换:直存直取法、欠抽样采样法、自相似增量调制法;录音开始时间的选择:即时式、自检测式。
录放音时间可由数码管显示。
存储的语音信号掉电不丢失,掉电后RAM由电池供电,掉电保护电路如图22:

图22
系统录音的自检测功能:
录音的开始时间有两种方式:即时录音方式即可在按键后开始录音,自检测方式是在按键后并不开始录音,而是在当有声音发出时才开始录音。当键按下后,A/D进行高速采样,对采样值进行积分并进新判断,积分能消除噪声干扰,高速采样保证了响应的及时性。
系统开机自检及监控电路
系统开机自检包括了对RAM的数据校验。为了防止程序跑飞,在此选用X25045作为看门狗电路,它具有低电源电压检测以及直至Vcc=1V复位信号有效;复位时间可由软件设置等特点
测试结果分析
使用的仪器仪表
PC机 HH1713双路直流稳压电源
ICE-51 仿真器 HP54645D示波器
20MHZ双踪示波器 WD-4微机稳压电源
HG1643功率函数信号发生器 TD-9202数字万用表
秒表
误差分析
对于任何系统,误差的出现是不可避免的。要减小系统误差,误差分析是必需的。下面就系统误差作如下分析:
量化误差 在进行语音信号采集存储时,由于是8位的A/D转换,量化误差为
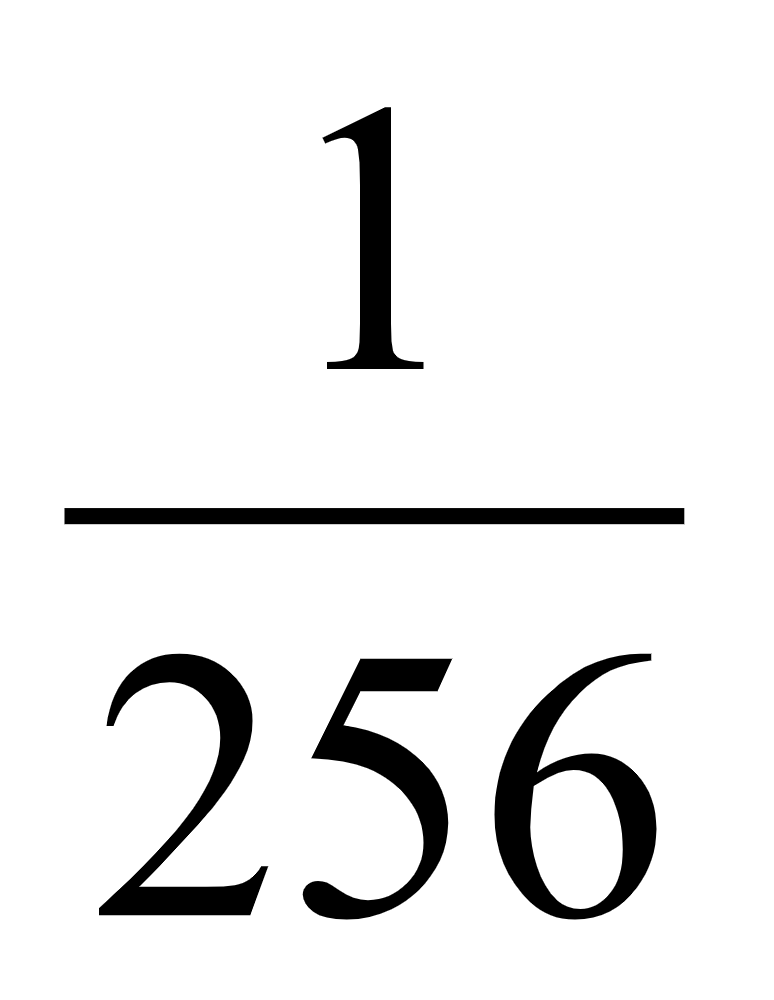 ;
;失真度 语音信号的回放与原话音信号相比,存在一定的失真,由于话音信号分别在采集与放音前分别经过了一个带通滤波器,而对带通滤波器,带内平缓,带外陡峭不易同时达到,所以使声音信号有一定的失真。
系统测试结果
根据题目要求,使用上述仪器系统整机实时测量数据如下所示:
滤波器特性测试
测试条件:输入为VP-P=1V的正弦波
校正滤波器特性 (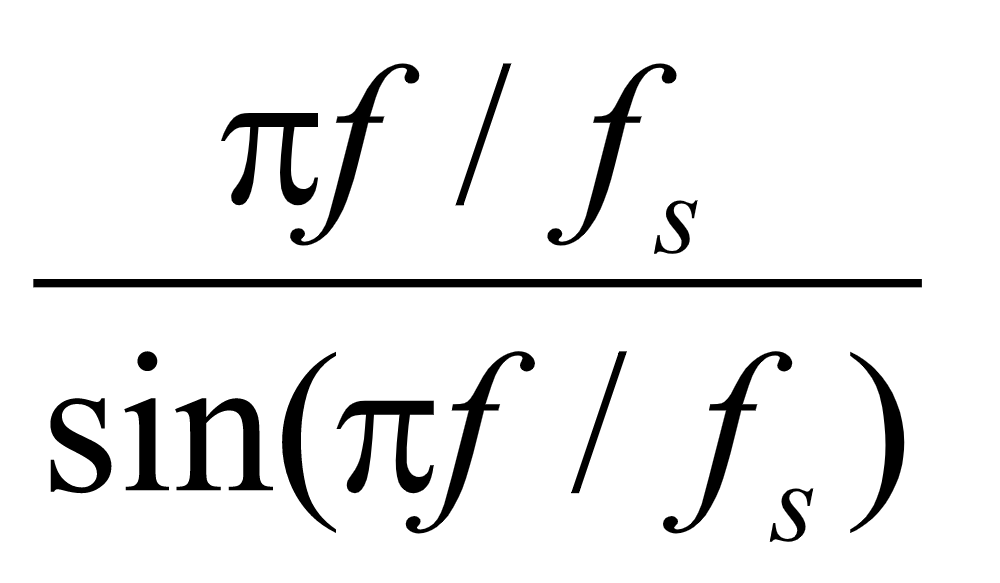 校正):
校正):


图1
带通滤波器特性

表2
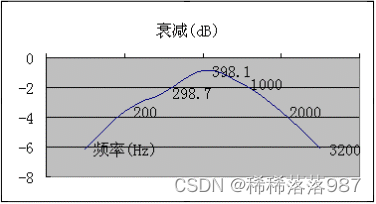
图2
自动音量控制(AGC)

图3
(3)语音信号清晰度测试
限于测试条件,这里只能以人为听觉为标准。
未压缩语音存储时间:32.7秒 (回放语音清晰)
压缩后语音存储时间:65.5秒 (回放语音清晰)
147.4秒 (回放语音较清晰)
通过对测试结果进行分析,全部测试结果满足或高于设计要求。