👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆下载资源链接👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆
《《《《《《《《更多资源还请持续关注本专栏》》》》》》》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html

由于单个负荷预测方法的局限性较大,为了提高算法在不同场景下的预测精度,本文设计了一种集成负荷预测模型。本文先建立了结合时序特征的Cat Boost负荷预测模型来解决Cat Boost不考虑负荷时序性的问题,再建立了多层LSTM短期负荷预测模型,用真实数据验证了两个模型的有效性。随后,采用集成学习Stacking策略,提出了基于时间间隔的加权岭回归算法来结合两个算法的优势,构建了集成预测模型,提出的结合算法可以防止模型陷入过拟合问题以及基于时间间隔调整各个样本的学习权重。通过实验将该模型与其他模型进行对比,证明了模型的优越性。
部分代码展示:
%% 导入数据
clear all
data_load=xlsread('日平均负荷.xls');
x=data_load;
k_num=0;k_num1=0;
%% 初始化
km=6;K=6;Kl=6;K3=6;%定义预期的聚类中心数
theta_N=1;% theta_N : 每一聚类中心中最少的样本数,少于此数就不作为一个独立的聚类
theta_S=1;% theta_S :一个聚类中样本距离分布的标准差
theta_c=3;% theta_c : 两聚类中心之间的最小距离,如小于此数,两个聚类进行合并
L=1;% L : 在一次迭代运算中可以和并的聚类中心的最多对数
%% K=means 方法聚类结果
[IDW,CW,sumdw,DW] = kmeans(x,km);
Clust = cell(km,1);
for i=1:km
CW1{i,1}=CW(i,:);
end
for i=1:km
clustw1=find(IDW==i);
Clust{i} = x(clustw1,:);
end
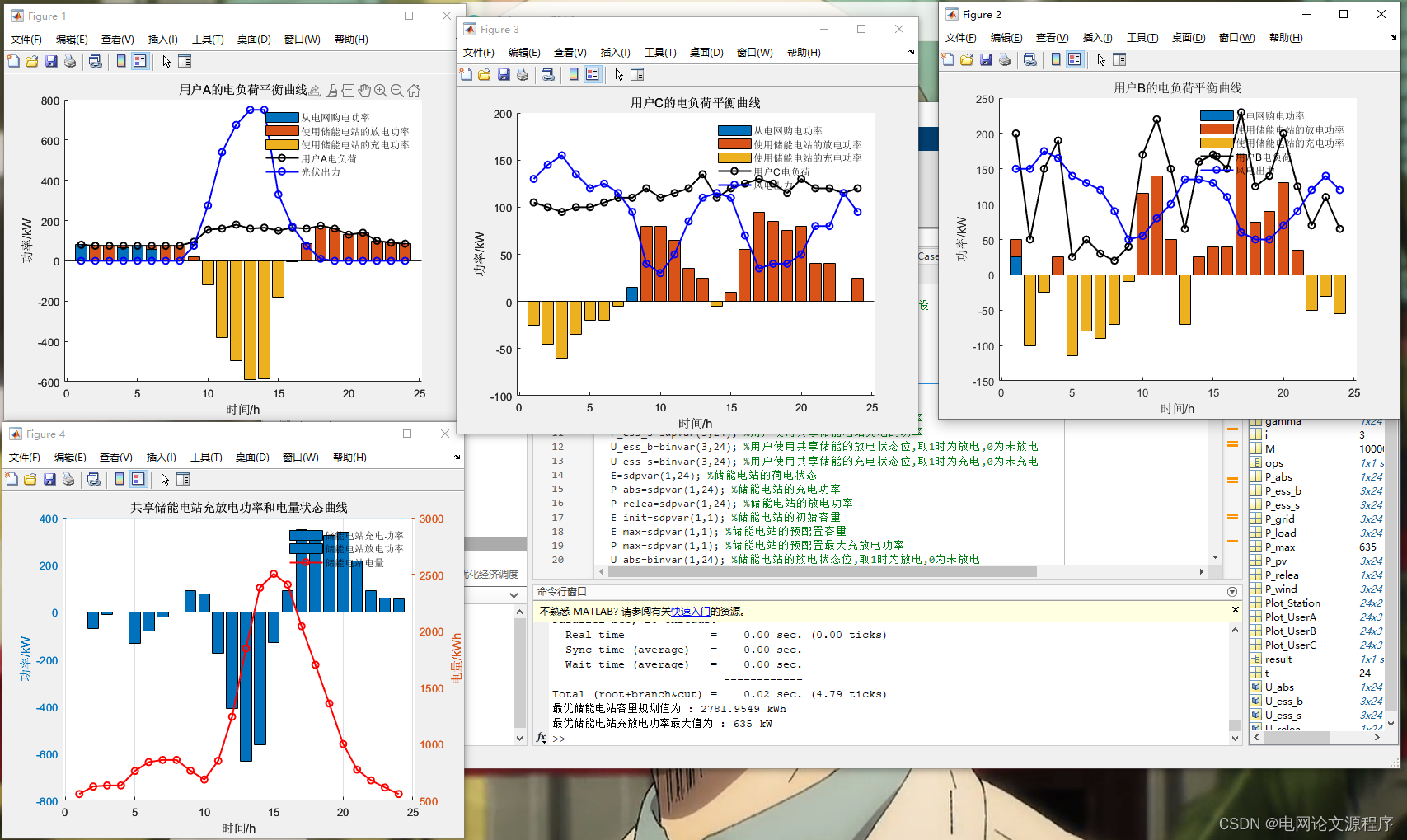
%% K-means 聚类结果图
for i=1:km
figure
subplot(2,1,1);
plot(CW(i,:)/(max(CW(i,:))),'-');xlabel('采样点');ylabel('标幺值');axis([1 92 -inf inf])
titlemane=strcat('k-means第',num2str(i),'聚类中心(归一化)');
title(titlemane)
subplot(2,1,2);
cu=Clust{i};
plot(cu','-');xlabel('采样点');ylabel('负荷');axis([1 92 -inf inf])
titlemane=strcat('k-means第',num2str(i),'场景聚类');
title(titlemane)
end
%% ISODATA聚类方法
[AA,BB]=ISODATA(x,K,theta_N,theta_S,theta_c,L);
for i=1:K
if size(AA{i},2)==1
k_num1=k_num1+1;
AA{i,1}=[];
BB{i,1}=[];
end
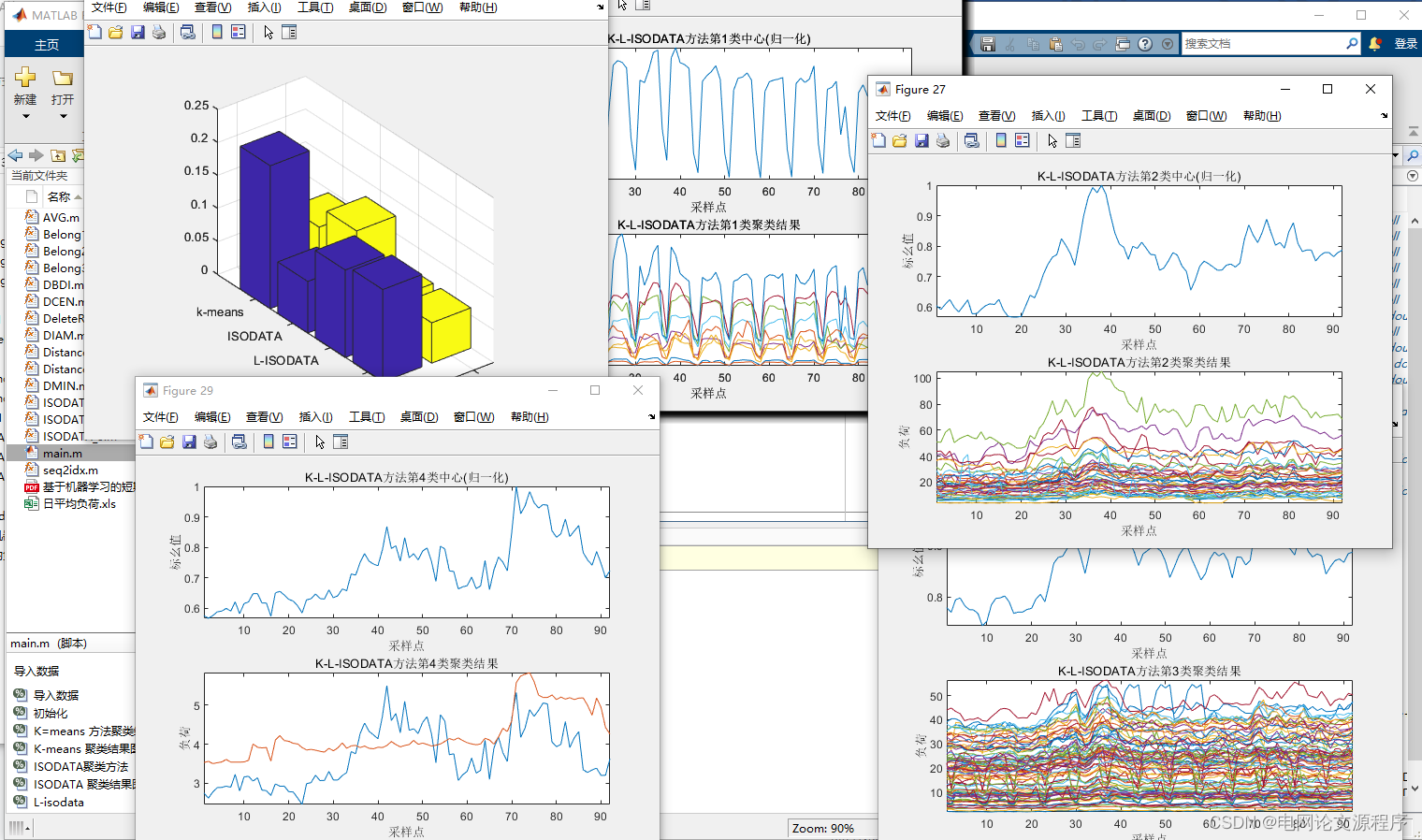
end效果展示:
null![]() https://download.csdn.net/download/LIANG674027206/89039113 👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆下载资源链接👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆
https://download.csdn.net/download/LIANG674027206/89039113 👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆下载资源链接👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆
《《《《《《《《更多资源还请持续关注本专栏》》》》》》》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html