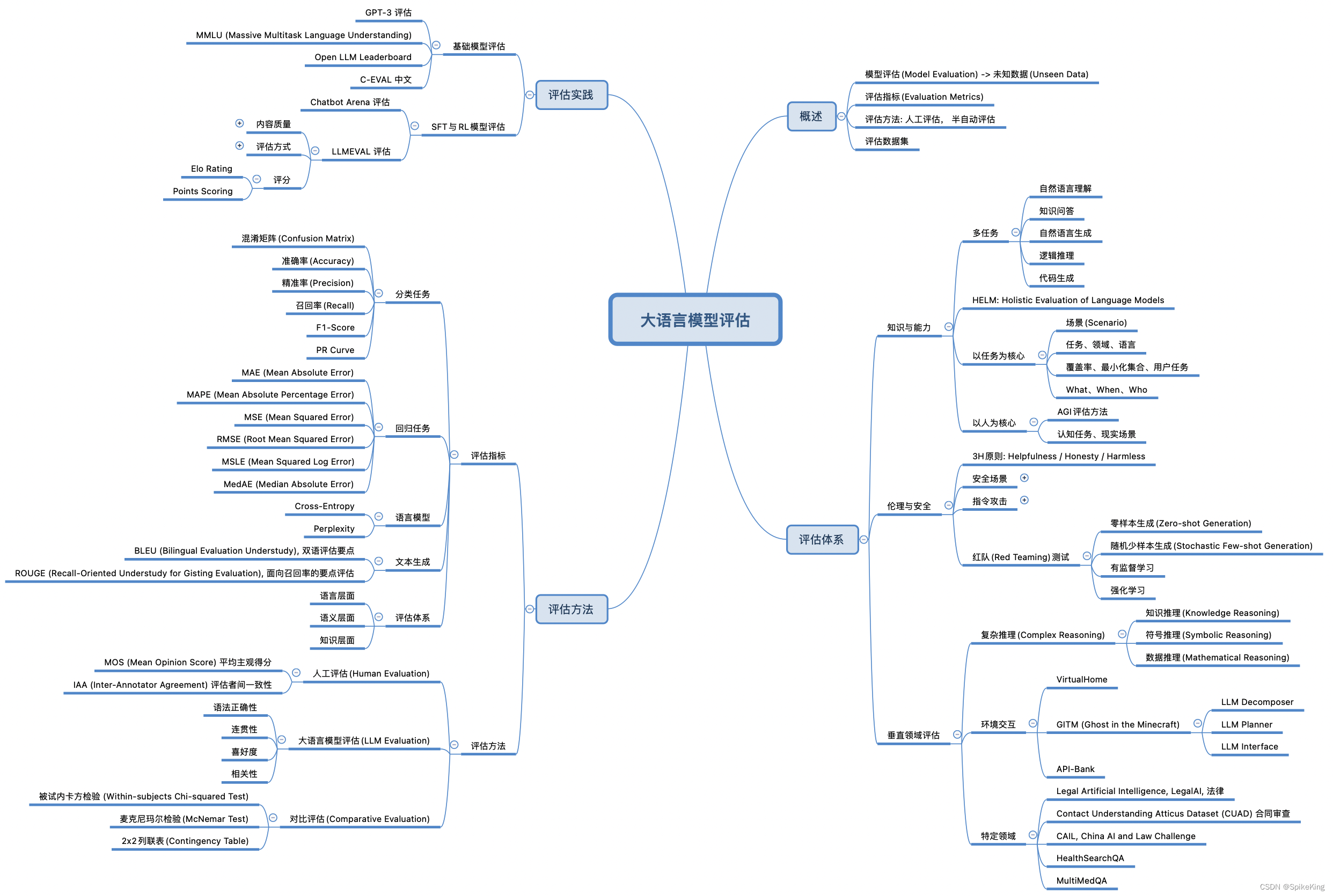
大语言模型开发过程评估
1. 提出问题
场景:我们要设计一个专有领域的大语言模型,设计思路是先选择开源的基座模型,使用领域相关的数据集对基座模型进行微调得到通用的大语言模型,再使用特定任务的数据集进一步对基座模型进行微调得到专用的大语言模型。
问题:如何对大语言模型开发的各个阶段进行评价,以确保每一步操作的有效性。
思考:第一次接触这个问题的时候,我想到的对大语言模型的评价是针对专用模型的评价,在公用的开源数据集或者基准上计算评价指标的得分,如果得分高则意味着大语言模型性能好。但是,仅考虑对专用大语言模型的评价就会忽略之前开发的各阶段所做的努力。显然,评估大语言模型开发的各个阶段更加合理,能够证明每一步工作的有效性,提高开发的效率。
2. 大语言模型开发过程评估
根据我们设计领域特定大语言模型的思路,对大语言模型开发过程的评估主要有两个方面,一个是数据的评估,一个是模型的评估。
数据评估方法
对于数据评估方法,无论是为了获得通用大语言模型还是专用大语言模型都需要使用数据对模型进行微调,即使是最终评估模型的性能,也需要考虑数据集或基准的有效性,所以评估数据主要有三个方面:
- 为了获得通用大语言模型而使用的训练数据
- 为了获得专用大语言模型而使用的训练数据
- 为了评价大语言模型性能而使用的数据集或者基准
训练数据质量评估
- 数据来源和收集:训练数据的来源和收集方式是否可靠和权威
- 数据量和多样性:训练数据的大小是否足够,数据是否覆盖了各种语言和使用场景
- 数据标注:训练数据的标准是否准确、一致
- 数据清洗和预处理:数据清洗、去重
评价数据集或者基准的质量评估
- 数据真实性和代表性:评价数据集是否基于真实数据,能够代表显示世界中的各种场景
- 评价指标的适用性:能否客观地评估模型的性能
模型评估方法
对于模型评估方法,首先是评估基准模型的性能以选择合适的基座模型,其次是评估通用的大语言模型的性能,最后是评估专用的大语言模型的性能,所以评估模型主要有三个方面:
- 评估基座模型
- 评估通用大语言模型
- 评估专用大语言模型
评估基座模型
评估通用大语言模型
- Accuracy
- Perplexity
- F1 Score(Precision、Recall)主要是针对分类任务
评估专用大语言模型
评估特定于任务的专用大语言模型,这里以我接触较多的用于代码生成任务的大语言模型为例,主要有以下评估方法:
- BLEU:将生成代码和参考代码看作tokens序列,也可以认为是将两者看作字符串序列,通过比较tokens级别的n-grams匹配精度来对大语言模型进行评价
- METEOR
- ROUGE-L
- CHRF/CHRF++
- RUBY
- CodeBLEU
- Pass@k





![[C++] 由C语言过渡到C++的敲门砖](https://img-blog.csdnimg.cn/img_convert/69a0271271d17db72b728368cd94a91b.png)