上一节我们第一阶段,训练特征映射层,对应的训练脚本,已经提供,指定训练数据集以后,
直接用一张或者8张A100 一张80G显存去跑就可以了.
然后第二阶段就是对大语言模型进行微调,这里需要两类数据,对话数据的两类,一类是:
常规对话数据:
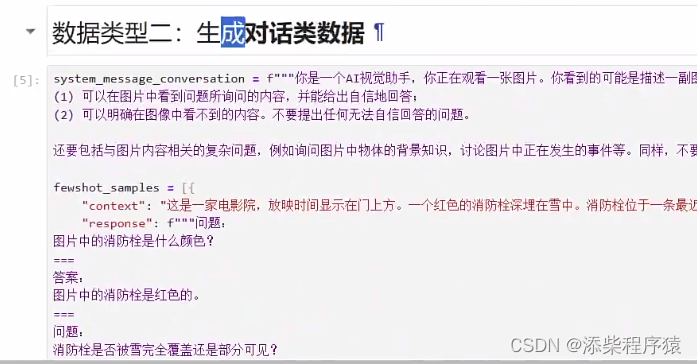
之前我们生成的,第二类是:

第二类是复杂推理类对话数据,可以看到,包含了图片中物体的位置信息数据.
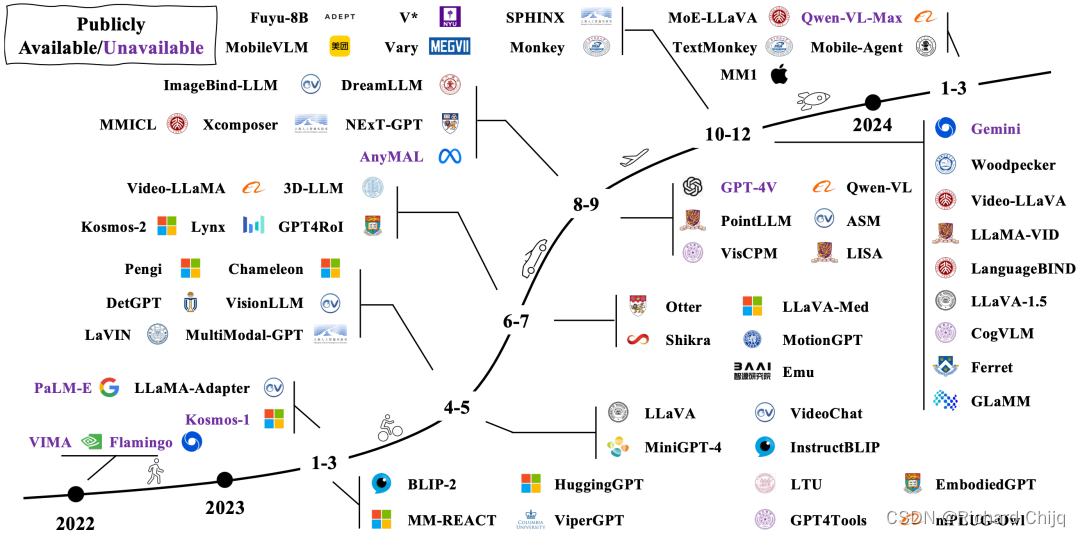
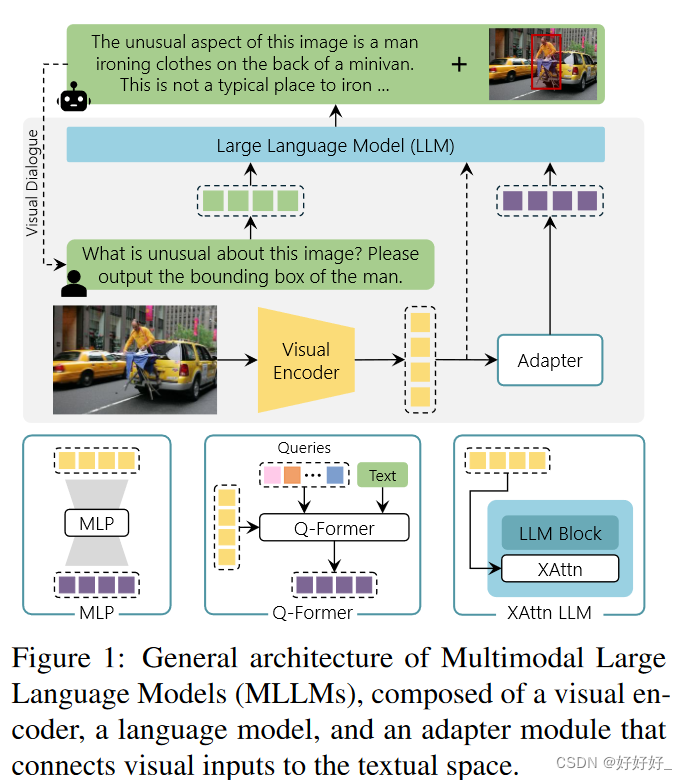
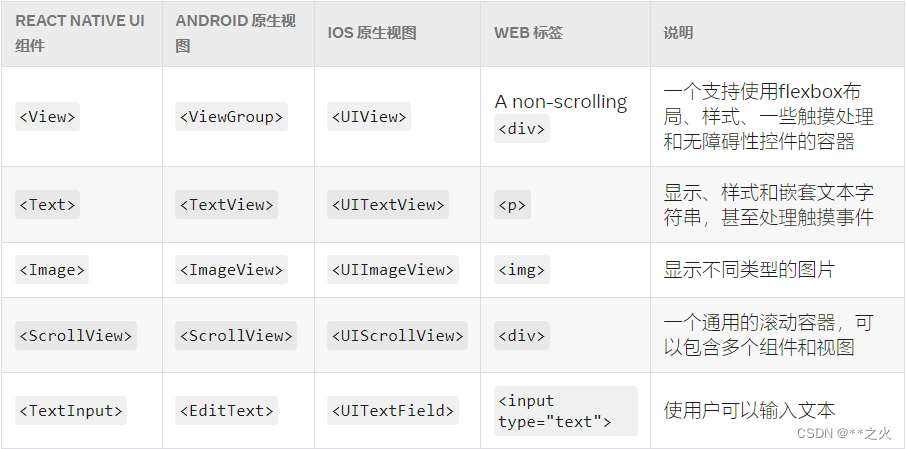
LLaVA是一种结合了文本和图像数据的多模态预训练模型。它基于大型语言模型和视觉模型,通过多模态融合技术将这两种模型的信息进行整合,从而能够处理和理解多种不同类型的数据。
LLaVA模型的主要特点包括:
1. 多模态输入:LLaVA模型可以同时接收文本和图像输入,这使得它能够更好地理解和处理多模态数据。
2. 预训练任务:LLaVA模型在预训练阶段使用了大量的文本和图像数据进行训练,以学习如何将这两种不同类型的数据进行有效融合。
3. 多模态融合:LLaVA模型采用了多模态融合技术,如注意力机制和多层感知器,将文本和图像的特征进行整合,从而能够生成更加丰富和全面的理解。
4. 应用广泛:由于LLaVA模型能够处理和理解多模态数据,它在许多领域都有广泛的应用,如图像描述生成、视觉问答、多模态对话等。
总的来说,LLaVA模型是一种强大的多模态