目录
一. 常见故障
单实例常见故障
1. 故障一
- 故障现象
ERROR 2002 (HY000): Can't connect to local MySQL server through socket/data/mysql/mysql.sock'(2)- 问题分析
数据库未启动或者数据库端口被防火墙拦截
- 解决方法
启动数据库或者防火墙开放数据库监听端口
2. 故障二
- 故障现象
ERROR 1045 (28000): Access denied for user 'root'@"ocalhost (using password:
NO)- 问题分析
密码不正确或者没有权限访问
- 解决方法
修改my.cnf主配置文件,在[mysqld]下添加 skip-grant-tables
update更新user表authentication_string字段
重新授权
3.故障三
- 故障现象
在使用远程连接数据库时偶尔会发生远程连接数据库很慢的问题
- 问题分析
DNS解析慢、客户端连接过多
- 解决方法
- 修改my.cnf主配置文件(增加skip-name-resolve参数)
- 数据库授权禁止使用主机名
4. 故障四
- 故障现象
Can't open file:'xxx_forums.MYI'.(errno: 145)- 问题分析
- 服务器非正常关机,数据库所在空间已满,或一些其它未知的原因对数据库表造成了损坏
- 因拷贝数据库导致文件的属组发生变化
- 解决方法
- 修复数据表 (myisamchk、phpMyAdmin)
- 修改文件的属组
5. 故障五
- 故障现象
ERROR 1129 (HY000): Host 'xxx.xxx.xxx.xxx' is blocked because of many
connection errors; unblock with 'mysqladmin flush-hosts'- 问题分析
超出最大连接错误数量限制
- 解决方法
- 清除缓存(flush-hosts关键字)
- 修改mysql配置文件 (max_connect_errors=1000)
6.故障六
- 故障现象
Too many connections- 问题分析
连接数超出MySQL的最大连接限制
- 解决方法
- 修改MySQL配置文件 (max_connections=2000)
- 临时修改参数
- set GLOBAL max_connections=2000;
7.故障七
- 故障现象
Warning:World-writable config file '/etc/my.cnf' is ignored
ERROR! MySQL is running but PlD file could not be found- 问题分析
MySQL的配置文件/etc/my.cnf 权限问题
- 解决方法
chmod 644 /etc/my.cnf
8.故障八
- 故障现象
InnoDB:Error: page 14178 log sequence number 29455369832
InnoDB: is in the future! Current system log sequence number 29455369832- 问题分析
innodb数据文件损坏
- 解决方法
- 修改 my.cnf 配置文件 (innodb_force_recovery=4)
- 启动数据库后备份数据文件
- 利用备份文件恢复数据
主从环境常见故障
1.故障一
- 故障现象
从库的Slave_lO_Running为NO
The slave I/O thread stops because master and slave have equal MySQL serverids;
these ids must be different for replication to work (or the --replicate-same-server-id
option must be used on slave but this does not always make sense;
please check the manual before using it).- 问题分析
主库和从库的server-id值一样
- 解决方法
- 修改从库的 server-id 的值,修改为和主库不一样
- 重新启动数据库并再次同步
2. 故障二
- 故障现象
从库的Slave_SQL_Running为NO
- 问题分析
主键冲突或者主库删除或更新数据,从库内找不到记录,数据被修改导致
- 解决方法
方法一
mysql> stop slave;
mysqI> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> start slave;
方法二
set global read_only=true;
3. 故障三
- 故障现象
Error initializing relay log position: I/O error reading the header from
the binary log- 问题分析
从库的中继日志 relay-bin 损坏
- 解决方法
手工修复,重新找到同步的 binlog 和 pos 点,然后重新同步即可
mysqI> CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxx',MASTER_LOG_POS=xxx;二. 优化
可以从不同角度进行优化:
- 硬件优化
- MySQL配置文件优化
- SQL优化
- MySQL架构优化
1.硬件方面
服务器硬件,最主要的无非 CPU、内存、磁盘三大关键因素
1.1 关于CPU
CPU 对于 MySQL 应用,推荐使用 S.M.P.架构的多路对称 CPU。
例如:可以使用两颗 Intel Xeon 3.6GHz 的 CPU。现在比较推荐用 4U 的服务器来专门做数据库服务器,不仅仅是针对于 MySQL。
1.2 关于内存
物理内存对于一台使用 MySQL 的 Database Server 来说,服务器内存建议不要小于2GB,推荐使用 4GB 以上的物理内存。不过内存对于现在的服务器而言,可以说是一个可以忽略的问题,工作中遇到了高端服务器基本上内存都超过了 32G。
1.3 关于磁盘
磁盘寻道能力(磁盘 I/O)。以目前市场上普遍高转速 SAS 硬盘(15000 转/秒)为例, 这种硬盘理论上每秒寻道 15000 次,这是物理特性决定的,没有办法改变。 MySQL 每秒钟都在进行大量、复杂的查询操作,对磁盘的读写量可想而知。所以通常认为磁盘 I/O 是制约 MySQL 性能的最大因素之一,通常是使用 RAID-0+1 磁盘阵列,注意不要尝试使用RAID-5,MySQL 在 RAID-5 磁盘阵列上的效率并不高。如果不考虑硬件的投入成本,也可以考虑固态(SSD)硬盘专门作为数据库服务器使用。数据库的读写性能肯定会提高很多。
2. 配置文件优化
通常默认的 my.cnf 配置文件无法发挥出 MySQL 最高的性能,所以需要根据不同的硬件进行优化,配置文件的优化也是重点。下面是物理内存为 32G 的数据库优化参数,具体从全局、二进制日志、主从、innodb、myisam 几个方面优化
default-time-zone=+8:00
#默认 MySQL 使用的是系统时区,修改为北京时间,也就是所说的东八区
interactive_timeout = 120
#服务器关闭交互式连接前等待活动的秒数
wait_timeout = 120
#服务器关闭非交互连接之前等待活动的秒数
open_files_limit = 10240
#MySQL 服务器打开文件句柄数限制
group_concat_max_len = 102400
#MySQL 默认的拼接最大长度为 1024 个字节,由于 1024 个字节会出现不够用的情况, 根据实际情况进行修改
user=mysql
#使用 mysql 用户运行
character-set-server=utf8、init_connect='SET NAMES utf8'
#设置字符集为 utf8
back_log = 600
#在 MySQL 暂时停止响应新请求之前,短时间内的多少个请求可以被存在堆栈中。
如果系统在短时间内有很多连接,则需要增大该参数的值,
该参数值指定到来的 TCP/IP 连接的监听队列的大小。默认值 50
max_connections = 5000
#MySQL 允许最大的进程连接数,如果经常出现 Too Many Connections 的错误提示, 则需要增大此值
max_connect_errors = 6000
#设置每个主机的连接请求异常中断的最大次数。当超过该次数,MySQL 服务器将禁止
host 的连接请求,
直到 MySQL 服务器重启或通过flush hosts 命令清空此host 的相关信息
table_cache = 1024
数据表调整缓冲区大小。它设置表高速缓存的数目。每个连接进来,都会至少打开一个表缓存。因此,table_cache 的大小与 max_connections 的设置有关。例如,对于 200 个并行运行的连接,应该让表的缓存至少有 200×N。这里 N 是应用可以执行查询的一个连接中表的最大数量。
此外,还需要为临时表和文件保留一些额外的文件描述符。 当 MySQL 访问一个表时, 如果该表在缓存中已经被打开,则可以直接访问缓存。如果还没有被缓存,但是在 MySQL 表缓冲区中还有空间,那么这个表就被打开并放入表缓冲区。如果表缓存满了,则会按照一定的规则将当前未用的表释放,或者临时扩大表缓存来存放,使用表缓存的好处是可以更快速地访问表中的内容。执行 flushtables 会清空缓存的内容。
一般来说,可以通过 showstatus 命令查看数据库运行峰值时间的状态值 Open_tables 和 Opened_tables,判断是否需要增加 table_cache 的值(其中 open_tables 是当前打开的表的数量,Opened_tables 则是已经打开的表的数量)。若 open_tables 接近 table_cache, 并且 Opened_tables 值在逐步增加, 那就要考虑增加这个值的大小了。还有就是Table_locks_waited 比较高的时候,也需要增加 table_cache
table_open_cache = 2048
指定表高速缓存的大小。每当 MySQL 访问一个表时,如果在表缓冲区中还有空间,该表就被打开并放入其中,这样可以更快地访问表内容
max_heap_table_size = 256M
这个变量定义了用户可以创建的内存表 (memory table) 的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变,即 set @max_heap_table_size=#。但是对于已经存在的内存表就没有什么用了,除非这个表被重新创建(create table)、修改(alter table)或者truncate table。服务重启也会设置已经存在的内存表为全局 max_heap_table_size 的值
external-locking = false
使用 skip-external-lockingMySQL 选项以避免外部锁定。该选项默认开启
max_allowed_packet = 32M
设置在网络传输中一次消息传输量的最大值。系统默认值为 1MB,最大值是 1GB,必须设置 1024 的倍数
sort_buffer_size = 512M
Sort_Buffer_Size 是一个 connection 级参数,在每个 connection(session)第一次需要使用这个 buffer 的时候,一次性分配设置的内存。Sort_Buffer_Size 并不是越大越好,由于是 connection 级的参数,过大的设置+高并发可能会耗尽系统内存资源
join_buffer_size = 8M
用于表间关联缓存的大小,和 sort_buffer_size 一样,该参数对应的分配内存也是每个连接独享
thread_cache_size = 300
服务器线程缓存这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中;如果线程重新被请求,那么请求将从缓存中读取;如果缓存中是空的或者是新的请求,那么这个线程将被重新创建;如果有很多新的线程,增加这个值可以改善系统性能。通过比较 Connections 和 Threads_created 状态的变量,可以看到这个变量的作用。设置规则如下:1GB 内存配置为 8,2GB 配置为 16, 3GB 配置为 32,4GB 或更高内存,可配置更大
thread_concurrency = 8
设置 thread_concurrency 值的正确与否,对 MySQL 的性能影响很大,在多个 CPU(或多核)的情况下, 错误设置了 thread_concurrency 的值, 会导致 MySQL 不能充分利用多CPU(或多核),出现同一时刻只能一个 CPU 在工作的情况。thread_concurrency 应设为CPU
核数的 2 倍。比如有一个双核的 CPU,那么 thread_concurrency 的应该为 4;2 个双核的
cpu,thread_concurrency 的值应为 8
query_cache_size = 512M
使用 MySQL 的用户,对于这个变量一定不会陌生。前几年的 MyISAM 引擎优化中, 这个参数也是一个重要的优化参数。但随着发展,这个参数也爆露出来一些问题。机器的内存越来越大,人们也都习惯性的把以前有用的参数分配的值越来越大。这个参数加大后也引发了一系列问题。首先分析一下 query_cache_size 的工作原理:一个 SELECT 查询在 DB 中工作后,DB 会把该语句缓存下来。当同样的一个 SQL 再次来到 DB 里调用时,DB 在该表没发生变化的情况下把结果从缓存中返回给 Client。这里有一个关建点,就是 DB 在利用Query_cache 工作时,要求该语句涉及的表在这段时间内没有发生变更。那如果该表在发生变更时,Query_cache 里的数据又怎么处理呢?首先要把 Query_cache 和该表相关的语句全部设置为失效,然后再写入更新。那么如果 Query_cache 非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是 Insert 就会很慢,这样看到的就是 Update 或是Insert 怎么这么慢了。所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建议把该功能禁掉
query_cache_limit = 4M
指定单个查询能够使用的缓冲区大小,缺省为 1M
query_cache_min_res_unit = 2k
默认是 4KB,设置值大对大数据查询有好处,但如果查询都是小数据查询,就容易造成内存碎片和浪费,查询缓存碎片率=Qcache_free_blocks/Qcache_total_blocks*100%。 如果查询缓存碎片率超过 20%,可以用 FLUSHQUERYCACHE 整理缓存碎片,或者尝试减小 query_cache_min_res_unit 。 如果查询都是小数据量, 那么查询缓存利用率
=(query_cache_size–Qcache_free_memory)/query_cache_size*100%。查询缓存利用率在 25%以下,说明 query_cache_size 设置的过大,可适当减小。查询缓存利用率在 80%以上而且 Qcache_lowmem_prunes>50 的话说明 query_cache_size 可能有点小,要不就是碎片太多。查询缓存命中率=(Qcache_hits–Qcache_inserts)/Qcache_hits*100%
default-storage-engine = innodb
默认引擎,现在一般都是 innodb 引擎表居多
thread_stack = 192K
设置 MySQL 每个线程的堆栈大小,默认值足够大,可满足普通操作。可设置范围为
128K 至 4GB,默认为 192KB
transaction_isolation = READ-COMMITTED
设定默认的事务隔离级别,READCOMMITTEE 是读已提交
tmp_table_size = 256M
tmp_table_size 的默认大小是 32M。如果一张临时表超出该大小,MySQL 产生一个Thetabletbl_nameisfull 形 式 的 错误 ; 如 果 执 行很 多 高 级 GROUPBY 查 询, 增 加tmp_table_size 值。如果超过该值,则会将临时表写入磁盘
key_buffer_size = 1024M
指定用于索引的缓冲区大小,增加它可以得到更好的索引处理性能
read_buffer_size = 2M
MySQL 读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL 会为它分配一段内存缓冲区。read_buffer_size 变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。和 sort_buffer_size 一样,该参数对应的分配内存也是每个连接独享
read_rnd_buffer_size = 256M
MySQL 的随机读(查询操作)缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL 会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度。如果需要排序大量数据,可适当调高该值。但 MySQL 会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大
bulk_insert_buffer_size = 64M
批量插入数据缓存大小,可以有效提高插入效率,默认为 8M。(31)skip-name-resolve
禁止域名解析,包括主机名.所以授权的时候要使用 IP 地址
ft_min_word_len = 1
从 MySQL4.0 开始就支持全文索引功能,但是 MySQL 默认的最小索引长度是 4。如果是英文默认值是比较合理的,但是中文绝大部分词都是 2 个字符,这就导致小于 4 个字的词都不能被索引。MySQL 全文索引是专门为了解决模糊查询提供的,可以对整篇文章预先按照词进行索引,搜索效率高,能够支持百万级的数据检索。
下面几个参数时关于 MySQL 二进制日志文件的优化。
log-bin=mysql-bin
打开 MySQL 二进制功能
binlog_cache_size = 4M
在事务过程中容纳二进制日志 SQL 语句的缓存大小。二进制日志缓存是服务器支持事务存储引擎并且服务器启用了二进制日志(—log-bin 选项)的前提下为每个客户端分配的内存。
注意:是每个 Client 都可以分配设置大小的 binlogcache 空间。可以通过 MySQL 的以下两个 状态变量来判 断当前的 binlog_cache_size 的状况 : Binlog_cache_use 和Binlog_cache_disk_use
max_binlog_cache_size = 128M
表 示 binlog 能 够使 用的 最大 cache 内 存大 小。 执行 多语 句事 务的 时候 , max_binlog_cache_size 如 果 不 够 大 的 话 , 系 统 可 能 会 报 出“Multi-statementtransactionrequiredmorethan'max_binlog_cache_size'bytesofstorage” 的错误
max_binlog_size = 1G
Binlog 日志最大值,一般来说设置为 512M 或者 1G,但不能超过 1G。该大小并不能非常严格控制 Binlog 大小,尤其是当到达 Binlog 比较靠近尾部而又遇到一个较大事务的时候,系统为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的所有 SQL 都记录进入当前日志,直到该事务结束。这一点和Oracle 的Redo 日志有点不一样,因为Oracle 的 Redo 日志所记录的是数据文件的物理位置的变化,而且里面同时记录了 Redo 和 Undo 相关的信息,所以同一个事务是否在一个日志中对 Oracle 来说并不关键。而 MySQL 在Binlog 中所记录的是数据库逻辑变化信息,MySQL 称之为 Event,实际上就是带来数据库变化的 DML 之类的 Query 语句
sync_binlog=1
在 MySQL 中系统默认的设置是 sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候的性能是最好的,但是风险也是最大的。因为一旦系统 Crash,在 binlog_cache 中的所有 binlog 信息都会被丢失。而当设置为“1”的时候最安全,但也是性能损耗最大的设置。因为当设置为 1 的时候,即使系统 Crash,也最多丢失 binlog_cache 中未完成的一个事务,对实际数据没有任何实质性影响。从以往经验和相关测试来看,对于高并发事务的系统来说,“sync_binlog”设置为 0 和设置为 1 的系统写入性能差距可能高达 5 倍甚至更多
binlog_format=mixed
默认使用 statement 模式,基于 SQL 语句的复制,另外一种是基于行的复制,为提升效率,可以将以上两种模式混合使用。一般的复制使用 STATEMENT 模式保存 binlog,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog,MySQL 会根据执行的SQL 语句选择日志保存方式
expire_logs_days = 7
二进制日志只留存最近 7 天,不用人工手动删除
log-slave-updates
这条参数只读主从架构适用,当从库 log_slave_updates 参数没有开启时,从库的 binlog 不会记录来源于主库的操作记录。只有开启 log_slave_updates,从库 binlog 才会记录主库同步的操作日志
slow_query_log
打开慢查询日志
slow_query_log_file=slow.log
慢查询日志文件位置
long_query_time = 2
记录超过 2 秒的 SQL 查询
关于引擎是 innodb 的优化如下:
innodb_additional_mem_pool_size = 64M
这个参数用来设置 InnoDB 存储的数据目录信息和其它内部数据结构的内存池大小,类似于 Oracle 的 library cache。这不是一个强制参数,可以被突破
innodb_buffer_pool_size = 20480M
用于缓存索引和数据的内存大小,这个选项的值越多越好, 数据读写在内存中非常快, 减少了对磁盘的读写。当数据提交或满足检查点条件后才一次性将内存数据刷新到磁盘中。 然而内存还有操作系统或数据库其他进程使用,推荐设置 innodb-buffer-pool-size 为服务器总可用内存的 75%。 若设置不当, 内存使用可能浪费或者使用过多。 对于繁忙的服务器, buffer pool 将划分为多个实例以提高系统并发性, 减少线程间读写缓存的争用。buffer pool 的大小首先受 innodb_buffer_pool_instances 影响,当然影响较小
innodb_data_file_path = ibdata1:1024M:autoextend
用 来 指 定 innodb tablespace 文 件 , 如 果 我 们 不 在 my.cnf 文 件 中 指 定innodb_data_home_dir 和innodb_data_file_path 那么默认会在datadir 目录下创建ibdata1 作为 innodb tablespace
innodb_file_io_threads = 4
文件 IO 的线程数,一般为 4,但是在 Windows 下,可以设置得较大
innodb_thread_concurrency = 8
服务器有几个 CPU 就设置为几,建议用默认设置,一般为 8
innodb_write_io_threads = 8
InnoDB 使用后台线程处理数据页上写 I/O(输入输出)请求的数量。一般设置为 CPU
核数,比如 CPU 是 2 颗 8 核的,可以设置为 8
innodb_read_io_threads = 8
InnoDB 使用后台线程处理数据页上读 I/O(输入输出)请求的数量。一般设置为 CPU
核数,比如 CPU 是 2 颗 8 核的,可以设置为 8
innodb_flush_log_at_trx_commit = 2
如果将此参数设置为 1,将在每次提交事务后将日志写入磁盘。为提高性能,可以设置为 0 或 2,但要承担在发生故障时丢失数据的风险。设置为 0 表示事务日志写入日志文件,
而日志文件每秒刷新到磁盘一次。设置为 2 表示事务日志将在提交时写入日志,但日志文件每次刷新到磁盘一次
innodb_log_buffer_size = 16M
此参数确定日志文件所用的内存大小,以 M 为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL 开发人员建议设置为 1-8M 之间
innodb_log_file_size = 256M
此参数确定数据日志文件的大小,以 M 为单位,较大的值可以提高性能,但也会增加恢复故障数据库所需的时间
innodb_log_files_in_group = 3
为提高性能,MySQL 可以以循环方式将日志文件写到多个文件
innodb_file_per_table = 1
独享表空间(关闭)
innodb_max_dirty_pages_pct = 90
Buffer_Pool 中 Dirty_Page 所占的数量, 直接影响 InnoDB 的关闭时间。 参数innodb_max_dirty_pages_pct 可以直接控制了 Dirty_Page 在 Buffer_Pool 中所占的比率, 而且幸运的是 innodb_max_dirty_pages_pct 是可以动态改变的。所以,在关闭 InnoDB 之前先将 innodb_max_dirty_pages_pct 调小,强制数据块 Flush 一段时间,就能够大大缩短MySQL 关闭的时间
innodb_lock_wait_timeout = 120
InnoDB 有其内置的死锁检测机制,能导致未完成的事务回滚。但是,如果结合 InnoDB 使用 MyISAM 的 locktables 语句或第三方事务引擎,InnoDB 就无法识别死锁。为消除这种可能性,可以将 innodb_lock_wait_timeout 设置为一个整数值,设置 MySQL 在允许其他事务修改那些最终受事务回滚的数据之前要等待多长时间(秒数)
innodb_open_files = 8192 innodb
打开文件句柄数
关于引擎是 myisam 的优化如下
myisam_sort_buffer_size = 128M
MyISAM 表发生变化时重新排序所需的缓冲大小
myisam_max_sort_file_size = 10G
MySQL 重建索引时所允许的最大临时文件的大小(当 REPAIR,ALTERTABLE 或者
LOADDATAINFILE)。如果文件大小比此值更大,索引会通过键值缓冲创建(更慢)
myisam_repair_threads = 1
如果一个表拥有超过一个索引,MyISAM 可以通过并行排序使用超过一个线程去修复。这对于拥有多个 CPU 以及大量内存情况的用户是一个很好的选择
myisam_recover
自动检查和修复没有适当关闭的 MyISAM 表
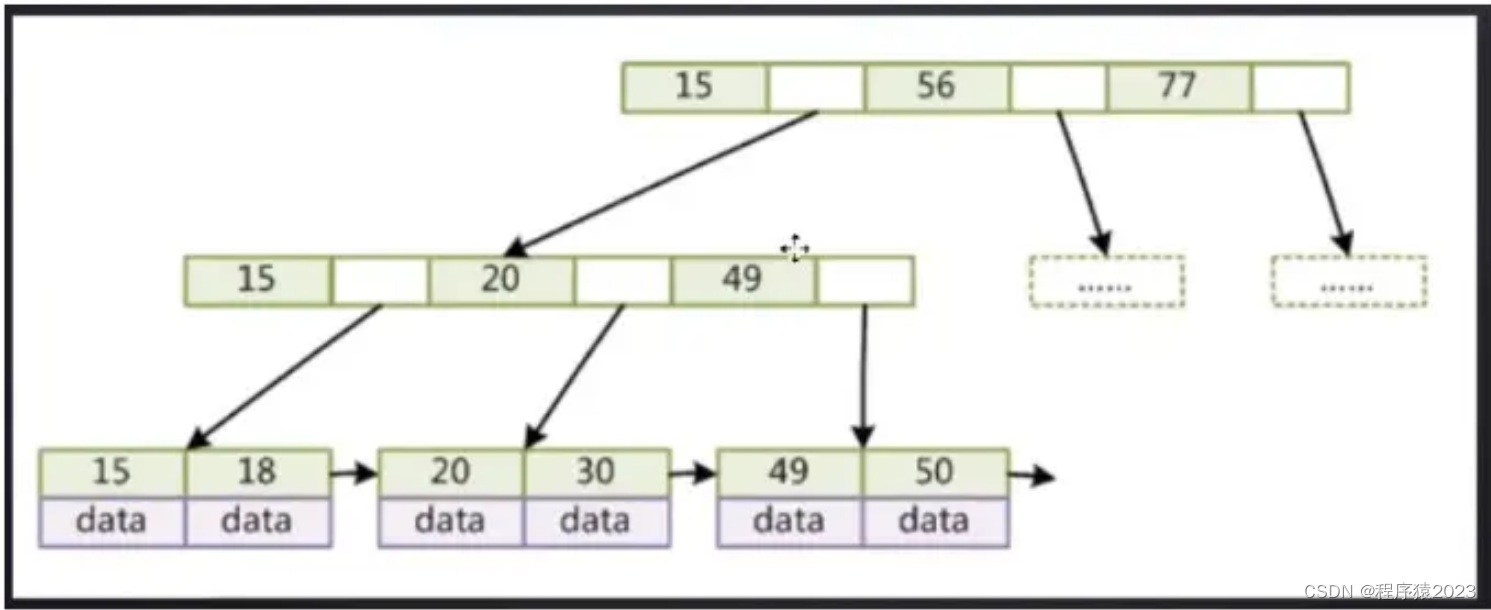
3.SQL优化
- 尽量使用索引进行查询
- 优化分页
- GROUP BY优化
4. 架构优化
架构选择: 主从、主主、一主多从、多主多从