第1关:Concat与Append操作
import pandas as pd
"""
data.csv和data1.csv是两份与各国幸福指数排名相关的数据,为了便于查看排名详情,所以需要将两份数据横向合并。数据列名含义如下:
列名 说明
Country (region) 国家
Ladder 排名
SD of Ladder 排名的偏差
Positive affect 积极影响
Negative affect 消极影响
Social support 社会福利
Freedom 自由度
Corruption 腐败程度
Generosity 慷慨程度
Log of GDP per capita 人均GDP的对数
Healthy life expectancy 健康程度
读取step1/data.csv和step1/data1.csv两份数据;
首先将两个数据横向合并;
将索引设为排名(Ladder)列;
填充空值为0;
具体要求请参见后续测试样例。
"""
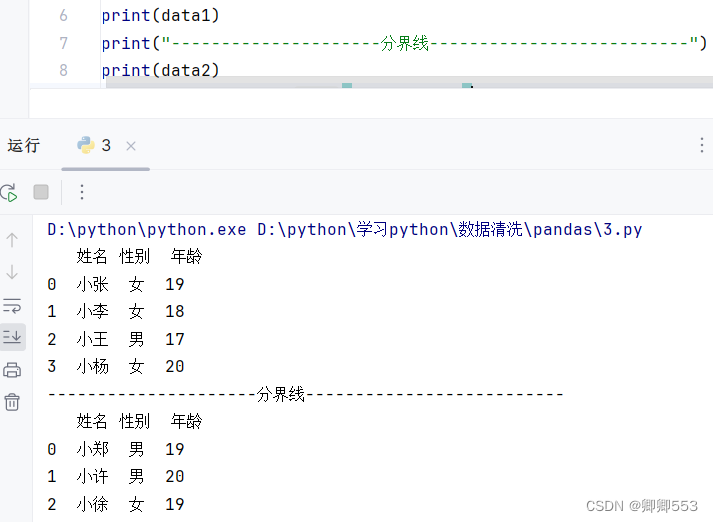
def task1():
d1 = pd.read_csv('step1/data.csv', header=0)
d2 = pd.read_csv('step1/data1.csv', header=0)
d3 = pd.concat([d1, d2], axis=1)
result = d3.set_index('Ladder').fillna(0)
return result
第2关:合并与连接
import pandas as pd
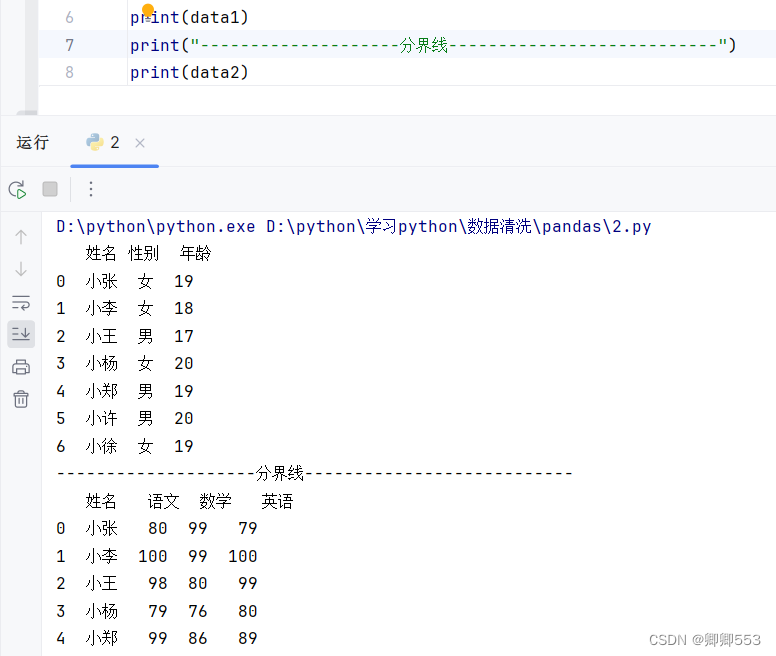
def task2(dataset1,dataset2,dataset3):
data = pd.DataFrame(dataset1)
data1 = pd.DataFrame(dataset2)
data2 = pd.DataFrame(dataset3)
data2.rename(columns={"id": "user_id"}, inplace=True)
data3 = pd.merge(data, data1, on="user_id", how="left")
data4 = pd.concat([data2, data3], ignore_index=True)
result = data4.sort_values("user_id").drop_duplicates("user_id")
return result
第3关:案例:美国各州的统计数据
import pandas as pd
import numpy as np
def task3():
pop = pd.read_csv('./step3/state-population.csv')
areas = pd.read_csv('./step3/state-areas.csv')
abbrevs = pd.read_csv('./step3/state-abbrevs.csv')
pa = pd.merge(pop, abbrevs, left_on=['state/region'], right_on=['abbreviation'], how='outer')
pa = pa.drop('abbreviation', axis=1)
"""
# 来全面检查一下数据是否有缺失,对每个字段逐行检查是否有缺失值,通过结果可知只有population和state列有缺失值;
for i in pa:
print(i, pa[i].isnull().any())
# 输出发现state/region = PR的对应的population和state都是空值
print(pa[pa['population'].isnull()])
# US对应的state也是空值
print(pa[pa['state'].isnull()])
"""
pa.loc[pa['state/region'] == 'PR', 'state'] = 'Puerto Rico'
pa.loc[pa['state/region'] == 'USA', 'state'] = 'United States'
pa = pd.merge(pa, areas, on='state', how='left')
pa = pa.dropna()
data2010 = pa[pa['year'] == 2010]
data2010.set_index('state', inplace=True)
density = data2010['population'] / data2010['area (sq. mi)']
sum_density = density.groupby('state').sum()
sort_sum_density = sum_density.sort_values(ascending=False)
print('前5名:\n{}'.format(sort_sum_density.head(5)))
print('后5名:\n{}'.format(sort_sum_density.tail(5)))


















![树形DP——[CTSC1997]选课](https://img-blog.csdnimg.cn/direct/13e95c95aed9488fa2db2a2ca59add8e.png)