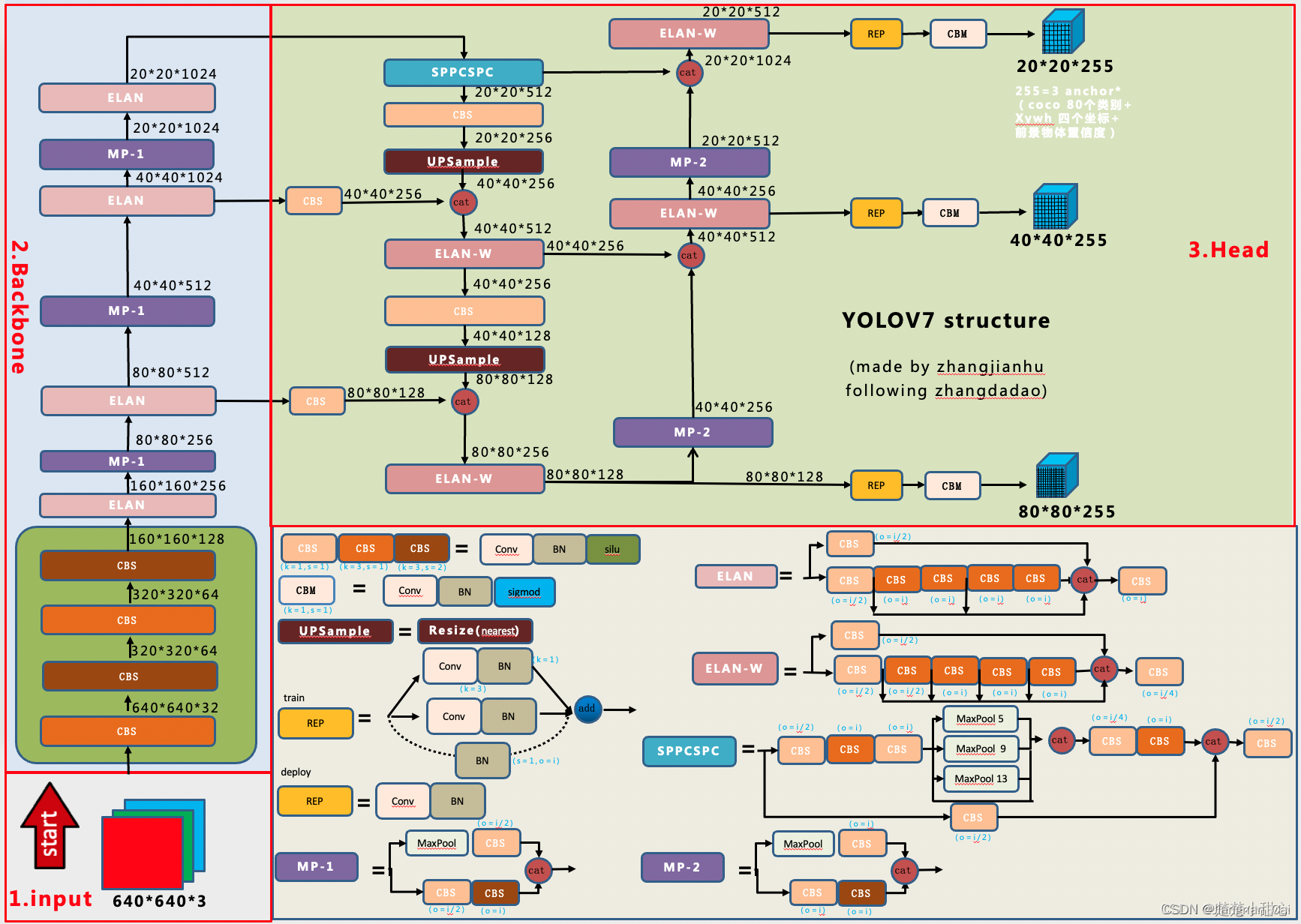
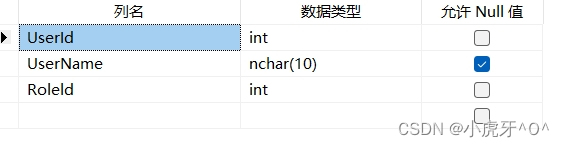
因为这个图已经比较详细和简明了,所以暂时就不自己画图了。
从上面看出来,相较于 YOLOv3,YOLOv4 将 DarkNet53 换成了 CspDarkNet53,也就是引入 Csp 模块。
Csp 模块的设计思路
通过分割梯度流,使梯度流通过不同的网络路径传播。通过切换串联和过渡步骤,传播的梯度信息可以具有较大的相关性差异。
Csp 模块的输入输出变化:
- 尺寸 size:height 和 width 都变为原来的 1/2
- 通道 channel:channel 变为原来的 2 倍
感觉重点就是 梯度组合 + 特征融合,虽然和 Inception 的模块结构不太一样,但是感觉设计思路都是一样的,采用分支来分流梯度,通过不同卷积组合或者残差结构获得不同的阶段的梯度信息,然后进行特征融合,最后输出。
Mish 激活函数
Mish 激活函数只在 YOLOv4 使用过,之后的 YOLOv5 就将它抛弃了。
从激活函数的曲线上来看,我们可以将 ReLU,Swish 和 Mish 三种激活函数拿出来比较。
 |
 |
 |
|---|---|---|
| ReLU | Swish | Mish |
可以看得出来,三种波形比较类似,只有细微差别。
- 共同点:
- 首先 3 个激活函数都有 上无界,下有界 的特点,
- 无上界:意味着可以防止网络饱和,即梯度消失,因为激活函数输出值达到某个上限的时候,梯度变化很小,接近于零,容易发生梯度消失的问题。
- 有下界:下界的存在有助于实现强正则化效果,这意味着模型能够更好地防止过拟合。
- 首先 3 个激活函数都有 上无界,下有界 的特点,
- 不同点:
- 单调性: 但是 ReLU 相较于后两者来说,是单调的,而 Swish 和 Mish 是非单调的,从上面的波形图也可以看得出来
- 负半轴:尽管都是有下界,但是 ReLU 在负半轴完全为零,梯度为零,出现神经元坏死,而 Swish 与 Mish 在负半轴会有负输出,保留一定的负信息。
- 平滑:Swish 和 Mish 相较于 ReLU 更为平滑,连续可微。
其实我们可以看到 Swish 与 Mish 函数的波形几乎一模一样,Swish 是 google 通过自动搜索技术搜索出来的最佳激活函数(多个一元或者二元函数组合),将 x 与 sigmoid 函数组合获得的。
Mish 也差不多是这样排列组合出来的。
虽然实验上某些指标有微小提升,但是个人觉得,Mish 的公式比 Swish 复杂多了,引入的计算量和微小的提升相比感觉不太值当,大概这就是只在 YOLOv4 用了一次之后,就被抛弃的原因吧。
DropBlock
在 YOLOv4 好像是有引入这个 trick,这个和 Dropout 有一点区别,如果说 Dropout 是在全连接层按照随机概率舍弃一些神经元,这个 DropBlock 则是作用与中间的卷积层,类似 CutOut 作用于数据集的图片,对图片的某些区域进行随机的裁剪,DropBlock 则是最卷积之后输出的 feature map 进行区域的随机裁剪,来达到正则化的效果。
总结
YOLOv4 相关的 trick 太多了,网上很多实现的 YOLOv4 的网路都只是实现了基础的部分。
参考文章: