Mitigating Object Hallucination in Large Vision-Language Models via Classifier-Free Guidance
----
通过无分类器指导减轻大视觉语言模型中的物体幻觉
摘要
大视觉语言模型(LVLM)的进步日益凸显了它们容易产生图像中不存在物体的幻觉这一关键问题。为了解决这个问题,以前的工作重点是使用专门策划的数据集或强大的 LLM(例如 GPT-3.5)来纠正 LVLM 的输出。然而,这些方法需要昂贵的培训/微调或 API 访问高级 LLM 来纠正模型的输出生成后。在本文中,我们通过引入一个名为“Mitigating幻觉通过无分类指导(MARINE)”的框架来应对这一挑战,该框架既无需训练,也无需API,可以有效且高效地减少生成过程中的物体幻觉。具体来说,MARINE 通过集成现有的开源视觉模型来丰富 LVLM 的视觉环境,并采用无分类器引导来合并额外的对象接地功能,以提高 LVLM 各代的精度。通过对 6 个流行的 LVLM 和不同评估指标的综合评估,我们证明了 MARINE 的有效性,它甚至优于现有的基于微调的方法。值得注意的是,根据 GPT-4V 的评估,它不仅减少了幻觉,还提高了 LVLM 生成的细节。
简介
大型语言模型 (LLM) 的出现推动了将其卓越功能扩展到多模式数据方面的进步。基于对齐视觉和文本嵌入空间的预训练视觉语言模型(Radford et al., 2021; Jia et al., 2021; Alayrac et al., 2022)的开发,大视觉语言模型(LVLM)已经获得了实质性的进展。架构开发(Liu et al., 2023d;Zhu et al., 2023;Ye et al., 2023;Dai et al., 2023a;Gao et al., 2023)和基准数据集(Xu et al., 2023)的关注2023;Lu 等人,2024)。然而,与文本 LLM 中的幻觉问题类似(Ji 等人,2023),其中通过输入提示生成不相关的内容,LVLM 面临着称为对象幻觉的特定挑战:为给定图像生成不存在对象的描述( Li等人,2023b;Wang等人,2023b;Zhou等人,2023;Fu等人,2023;Lovenia等人,2023)。这样的问题尤其令人担忧,因为它会损害模型的准确性和可靠性,特别是考虑到 LVLM 越来越多地应用于医学成像等安全关键型下游任务(Chambon 等人,2022 年;Bazi 等人,2023 年)。
为了应对 LVLM 中物体幻觉这一紧迫问题,早期的尝试(Liu et al., 2023a,b;Gunjal et al., 2023;Wang et al., 2023a)侧重于纠正预训练固有的偏差通过整理高质量的数据集进行微调,专门用于减轻物体幻觉。然而,创建如此广泛、高质量的数据集以及随后对 LVLM 进行微调需要在人工注释和计算资源方面付出巨大成本。因此,最近的工作提出了更具成本效益的策略,采用带有最小微调校正器模型(Zhou et al., 2023;Zhai et al., 2023)或高级 GPT API(Yin et al., 2023)的生成后校正方法(Yin et al., 2023)。 ,2023)。虽然后生成方法有效地纠正了生成内容中的错误,但值得注意的是,它们也会覆盖模型的原始输出。这种现象如图 1 所示。特别是,后生成的专门输入(例如,“纠正此描述中的幻觉对象”)可能会对 LVLM 在响应不同类型问题和遵守操作说明。校正器模型,例如 GPT-3.5,也会自行引入固有的幻觉。像 LURE (Zhou et al., 2023) 这样的微调方法可能会进一步导致微调数据集中注释的过度拟合。
图 1:对图像-问题对的响应示例。经过 LURE 校正的输出偏离了原始问题,提供了不相关的描述,而没有直接解决查询。 Woodpecker 同样会覆盖原始输出,引入可能不是用户查询的边界框。它还幻觉有两张床的存在,而图中只有一张床。相比之下,MARINE 保持了原始答案的风格并遵循用户的指令,同时消除了幻觉。

为了在减少物体幻觉、计算效率、有限/无法访问高级 LLM 和保留 LLM 原创性之间取得平衡,我们引入了通过无分类 guIdaNcE (MARINE) 减轻幻觉,这是一个无需训练、无需 API 的框架,可以执行校正在生成过程中。如图 2 所示,我们的框架采用了预先训练的对象感知视觉编码器,以丰富 LVLM 的视觉上下文,并通过无分类器引导 (CFG) 控制文本生成(Ho 和 Salimans,2021),专为多目标设计模态设置。从视觉对象感知编码器中提取视觉特征并将其作为软提示投影到 LVLM,我们利用 CFG 生成引导输出,这更加重视来自对象感知编码器的丰富视觉特征。需要强调的是,我们的框架与任何视觉模型和投影功能兼容。在我们的论文中,我们提出了基于 DEtection TRansformer (DETR) (Carion et al., 2020) 的结果,表示为 MARINE-DETR,以及基于真实对象感知预言机的理想结果,表示为 MARINE-Truth。
使用 MSCOCO 数据集对六种广泛认可的 LVLM 进行了实证评估(Lin 等人,2014)。我们的实验结果表明,与最先进的算法相比,MARINE 表现出进一步减少的幻觉,根据现有的幻觉指标(例如 CHAIR(Rohrbach 等人,2018)和 POPE(Li 等人,2023b))进行测量,以及本研究中考虑的其他指标,包括召回率和对响应详细程度的 GPT-4V 评估。这些有希望的结果证实,MARINE 可以有效减轻物体幻觉,而无需额外的培训资源或获得高级法学硕士。此外,我们的消融研究阐明了不同级别的指导强度对性能的影响。我们还提供了具体示例来说明指南如何影响 LVLM 的输出 logits。
符号。我们分别使用小写字母、小写粗体字母和大写粗体字母分别表示标量、向量和矩阵。我们使用符号 p 来表示 LLM 响应的条件概率。我们将第 t 个标记之前生成的标记序列表示为 y<t = [y1,…。 。 。 , yt−1] 对于 t > 1。
图 2:MARINE 框架的图示,该框架添加了一个具有直接对齐功能的对象感知编码器,以丰富原始 LVLM 的视觉上下文。控制输出逻辑以更加重视具有引导强度γ的该对象接地软提示。

2 相关工作
2.1 大视觉语言模型中的幻觉
自从最近引入大视觉语言模型(LVLM)(Liu et al., 2023d;Zhu et al., 2023;Ye et al., 2023;Dai et al., 2023a;Gao et al., 2023),这些模型中的幻觉现象引起了研究界的广泛关注。李等人首先强调了这个问题。 (2023b) 和随后的研究 (Wang et al., 2023b; Zhou et al., 2023; Fu et al., 2023; Lovenia et al., 2023) 表明,LVLM 表现出与文本 LLM 类似的幻觉问题。值得注意的是,与文本LLM不同,LVLM 容易产生一种独特的幻觉,称为“物体幻觉”(Rohrbach et al., 2018),其中模型错误地感知图像中不存在的物体的存在。
为了应对物体幻觉问题,人们已经努力在较小的图像字幕模型中减轻物体幻觉(Biten 等人,2022;Dai 等人,2023b)。关于 LVLM 的最新发展,一些作品(Liu 等人,2023b;Gunjal 等人,2023)提出了旨在提高鲁棒性的视觉语言微调数据集。王等人。 (2023a)利用视觉语言模型生成更多样化的指令调整数据并迭代纠正数据中的不准确性。翟等人。 (2023) 引入了 GPT-4 辅助评估方法以及使用 MSCOCO 数据集的微调策略。这种微调方法在线性投影层内结合了二进制切换参数 ε ε {±1},根据对象检测器的输出与地面真实值之间的差异进行训练。与我们的环境最相关的是,Yin 等人。 (2023) 提出了 Woodepecker,这是一种五阶段免训练方法,最终利用 GPT-3.5 API 进行幻觉校正。同时,Leng 等人。 (2023) 提出了视觉对比解码 (VCD),其中涉及用噪声扭曲图像输入并对这些损坏图像的 logit 输出施加惩罚。我们的方法引入了额外的视觉特征来指导生成,而不是破坏图像并增加惩罚。
2.2 可控生成
可控文本生成(Prabhumoye et al.,2020;Hu and Li,2021;Zhang et al.,2023a)已成为一个重要的研究领域,重点关注具有可控属性(如人物角色)的自然句子的生成(Prabhumoye et al.,2023a)。 ,2020;Hu 和 Li,2021;Zhang 等,2023a)、礼貌(Niu 和 Bansal,2018;Madaan 等,2020)和故事结局(Peng 等,2018)。在各种方法中,微调被认为是最直接的方法,可以通过调整模型参数来实现(Li和Liang,2021;Ouyang等人,2022;Carlsson等人,2022)或集成可调谐适配器模块(Lin 等人,2021;Ribeiro 等人,2021)。虽然微调在广泛的应用中非常有效,但随着LLM规模的巨大增长,它的计算成本也很高。最近,扩散模型的可控生成取得了进展(Li et al., 2022;Lin et al., 2023),并扩展到可控文本到图像的生成(Yang et al., 2023)。特别是,分类器指导(Dhariwal 和 Nichol,2021)和无分类器指导(Ho 和 Salimans,2021)的使用在提高生成输出的质量方面已变得突出。而分类器指导则采用辅助分类器模型来评估和改进 Kawar 等人的生成。 (2022);金等人。 (2022);施等人。 (2023),无分类器指导将控制直接集成到生成模型中,为具有计算约束的实时应用程序提供了一种有效的方法(Saharia 等人,2022;Lin 等人,2024)。最近,桑切斯等人。 (2023) 将无分类器指导应用于单模态设置中的语言模型,以提高其在推理时的性能。受这些最新发展的启发,我们在多模式环境中引入了一种新颖的方法,旨在通过对 LVLM 生成文本的无分类器指导来减少幻觉。
3 预先知识
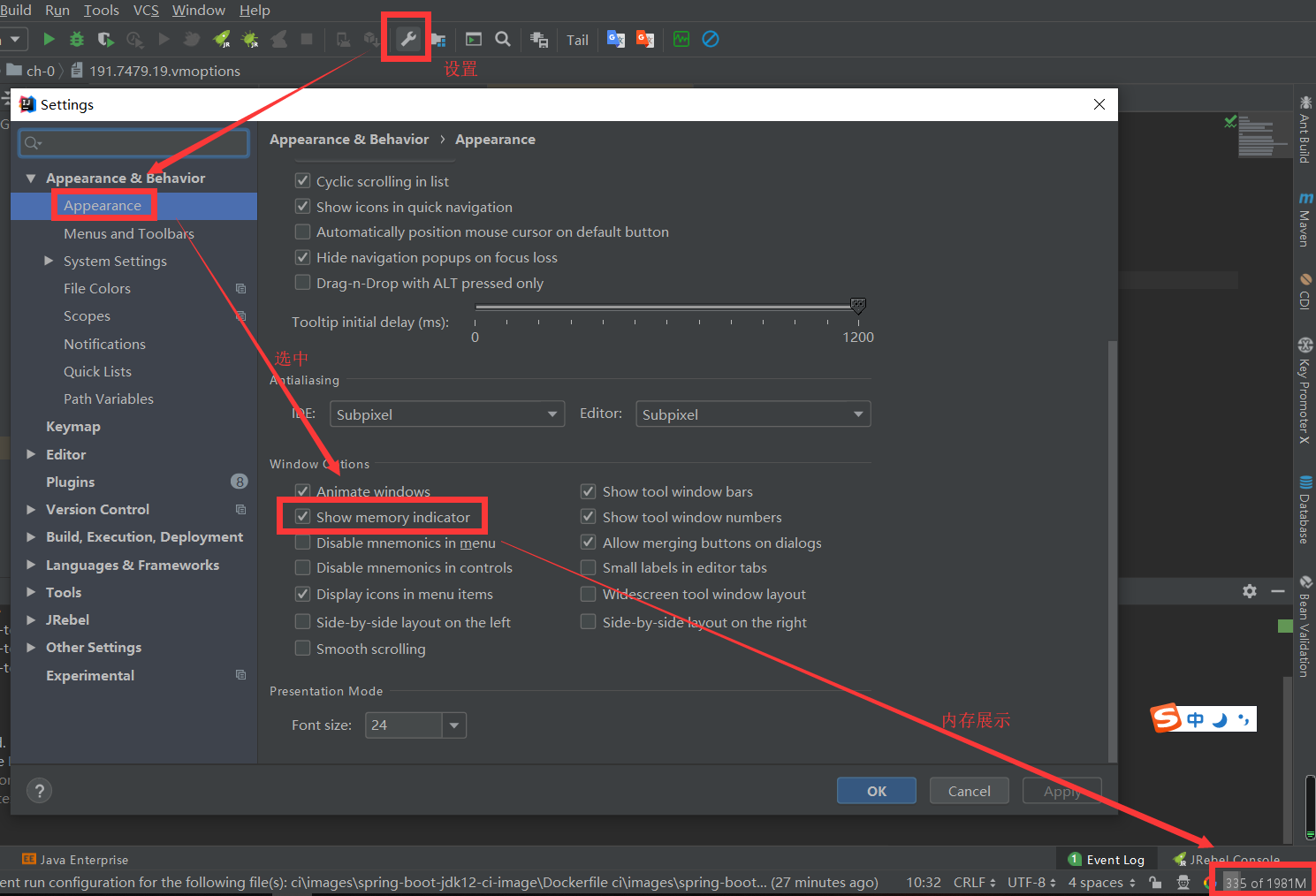
生成语言模型。设 pθ 表示由 θ 参数化的 LLM。考虑一个序列 x = [x1, . 。 。 , xn] 作为输入提示,其中每个 xi 是来自预定义词汇表的标记。然后 LLM 生成响应序列 y = [y1, . 。 。 , ym] 通过从条件概率分布 pθ(·|x) 中采样,其中 yt 表示 1 ≤ t ≤ m 的单个标记。因此,条件分布 pθ(y|x) 可以表示为 pθ(y|x) = Qm t=1 pθ(yt|x, y<t),其中 y<t = [y1, . 。 。 , yt−1] 对于 t > 1,对于 t = 1 为空。对于 LVLM,视觉标记 v = [v1,... 。 。 , vk] 也被另外包括在内。这些标记是由预先训练的视觉编码器生成的,并通过线性投影映射到标记空间。给定视觉标记 v 和文本提示 x 的输出 y 的条件分布表示为:
其中 pθ 由 LVLM 近似。
生成模型的指导。引导生成的过程涉及以输入 x 为条件获取输出 y,输入 x 对输出 y 的所需属性进行编码。该指导通常可以通过两种不同的方法添加到模型中:分类器指导(Dhariwal 和 Nichol,2021)和无分类器指导(Ho 和 Salimans,2021)。作为顶层视图,两种方法都将以指导 x 为条件的输出 y 的条件概率分布表述为

其中 pθ(y) 是原始生成模型,p(x|y) 是给定 y 时 x 的后验分布。 γ 是引导强度。在分类器指导中,(3.1)中的后验分布p(x|y)被由参数化的分类器pφ(x|y)代替,这需要额外的训练步骤并计算∇x log pφ(x|y)。另一方面,无分类器指导消除了参数化分类器 fφ 的必要性。相反,根据贝叶斯规则,后验分布可以近似为

其中 pθ(y|x) 是以 x 作为提示输入时的生成模型。将 (5.1) 代入 (3.1) 得到引导分布,可近似为

因此,随着 γ 值的增加,引导式 LLM b pθ 在生成过程中更加重视提示 x,从而生成更符合提示所需行为的文本 (Sanchez et al., 2023)。
4 方法
为了使问题形式化,我们注意到 LVLM 的架构(Liu et al., 2023d; Zhu et al., 2023)通常由视觉编码器、用于对齐视觉和文本域的投影层以及用于根据图像和提示生成响应。因此,物体幻觉可能是由这三个组成部分中任何一个的缺陷引起的:(1)视觉编码器提供的视觉上下文不足,正如Zhang等人所强调的那样。 (2023b)导致很大比例的幻觉,(2)由于对齐训练不足或对齐层的简单化性质,视觉和文本域之间的对齐有缺陷,以及(3)LLM从其预科课程中获得的固有语言先验。 - 训练数据分布(Biten 等人,2022)。针对导致物体幻觉的潜在因素(1)和(2),我们引入了 MARINE,这是一个免训练、无 API 的框架,通过利用额外的物体接地功能来指导 LVLM 的文本生成,无需精细处理,即可减轻 LVLM 幻觉。 -调整。接下来,我们分别介绍 MARINE 的两个主要部分:形成物体接地特征作为无分类指导和控制文本生成以最终减轻物体幻觉。在图 2 中,我们展示了 MARINE 的框架概述。
4.1 提取物体感知特征作为指导
为了引入对象感知功能来减轻幻觉,我们的方法集成了另一种对象检测模型 DEtection TRansformer (DETR)(Carion 等人,2020),该模型与 LVLM 中使用的视觉编码器不同,后者通常是从 CLIP 中预先训练的(Radford 等人)等,2021)。这种集成利用 DETR 从图像中提取预测对象概率,从而提供补充视觉信息。在获取这些额外的视觉特征后,我们对对象基础特征采用“直接对齐”,将 DERT 的输出直接映射到相应的文本对象。直接对齐是有效且高效的。它消除了微调对准层的必要性,同时保留了由物体接地特征编码的完整信息。随后,我们采用一个简单而有效的提示“关注该图像中的可见对象:”并将其与直接对齐生成的软提示连接起来,作为无分类器的引导提示 c。我们避免利用 DETR 模型的隐藏视觉特征,而是直接使用预测的物体概率来防止 DETR 和 LLM 嵌入空间之间不完美的视觉文本对齐引起的物体幻觉,并消除对齐精细的需要。调整。
我们注意到我们的框架与任何视觉模型兼容。出于说明目的,我们利用 DETR 作为代表性控制特征提取器,并将我们的方法与 DETR 组合时称为 MARINE-DETR。 MARINE 的性能随着所使用的控制制导提取器的进步而提高。因此,为了证明 MARINE 性能的潜在上限,我们考虑使用感知实况预言机提取器的版本,我们将其表示为 MARINE-Truth。
4.2 引导文本生成
虽然之前的无分类器引导方法 (Sanchez et al., 2023) 重视文本提示本身,以便在单模态设置中更好地使 LLM 生成与用户意图保持一致,但我们通过专门放置重要性来解决 LVLM 的物体幻觉问题关于我们在多模态设置中引入的对象感知信息。因此,除了从原始LVLM中提取的视觉标记v和文本提示x之外,我们还从DETR模型中提取了辅助视觉标记c。我们的无分类器引导 LVLM pθ 的输出 y 中第 t 个标记的生成表示为

其中c表示我们的控制指导,γ是控制强度。输出生成的采样由下式给出

我们可以进一步查看 logit 空间中的 MARINE,其中第 t 个标记因此是从 logit 空间中采样的:
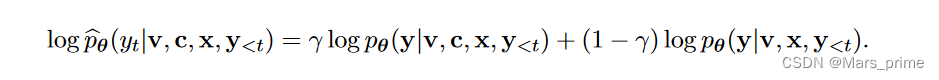
这种对数的线性组合意味着对象感知特征的条件生成充当可控门。采样时,只有两个分支中概率相对较高的对象才会出现在顶部。具体来说,设置 γ = 0 将在没有控制指导的情况下恢复原始 LLM 生成,而设置 γ = 1 则完全基于控制生成 LLM 生成。同时,对于 γ ε (0, 1),MARINE 产生原始生成 pθ(y|v, x) 和以附加对象基础特征 pθ(y|v, c, x) 为条件的生成的组合。这在更好地遵循指令生成高质量答案的能力与提高图像描述的准确性和细节之间取得了平衡。我们在算法 1 中总结了 MARINE。

5 Experiments
在本节中,我们对 MARINE 方法在减轻各种 LVLM 中的物体幻觉方面提供了详细的实证评估。具体来说,我们强调 MARINE 在不同问题格式的既定指标上优于最先进的缓解方法。
5.1 实验设置
模型。为了证明我们的方法在不同 LVLM 架构中的广泛适用性,我们将 MARINE 应用于最近广泛使用的模型,包括 LLaVA (Liu et al., 2023d)、LLaVA-v1.5 (Liu et al., 2023c)、MiniGPT -v2(Chen 等人,2023)、mPLUG-Owl2(Ye 等人,2023)、InstructBLIP(Liu 等人,2023c)和 LLaMA-Adapter-v2(Gao 等人,2023)。为了解决文本生成中的物体幻觉问题,我们将 DEtection TRansformer (DETR) (Carion et al., 2020) 纳入物体感知编码器以丰富视觉特征。