【MySQL】基本查询(2)
作者:爱写代码的刚子
时间:2024.3.27
前言:本篇博客将会介绍Update,Delete,插入查询结果,聚合函数以及group by子句的使用
Update
语法:
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
对查询到的结果进行列值更新
案例:
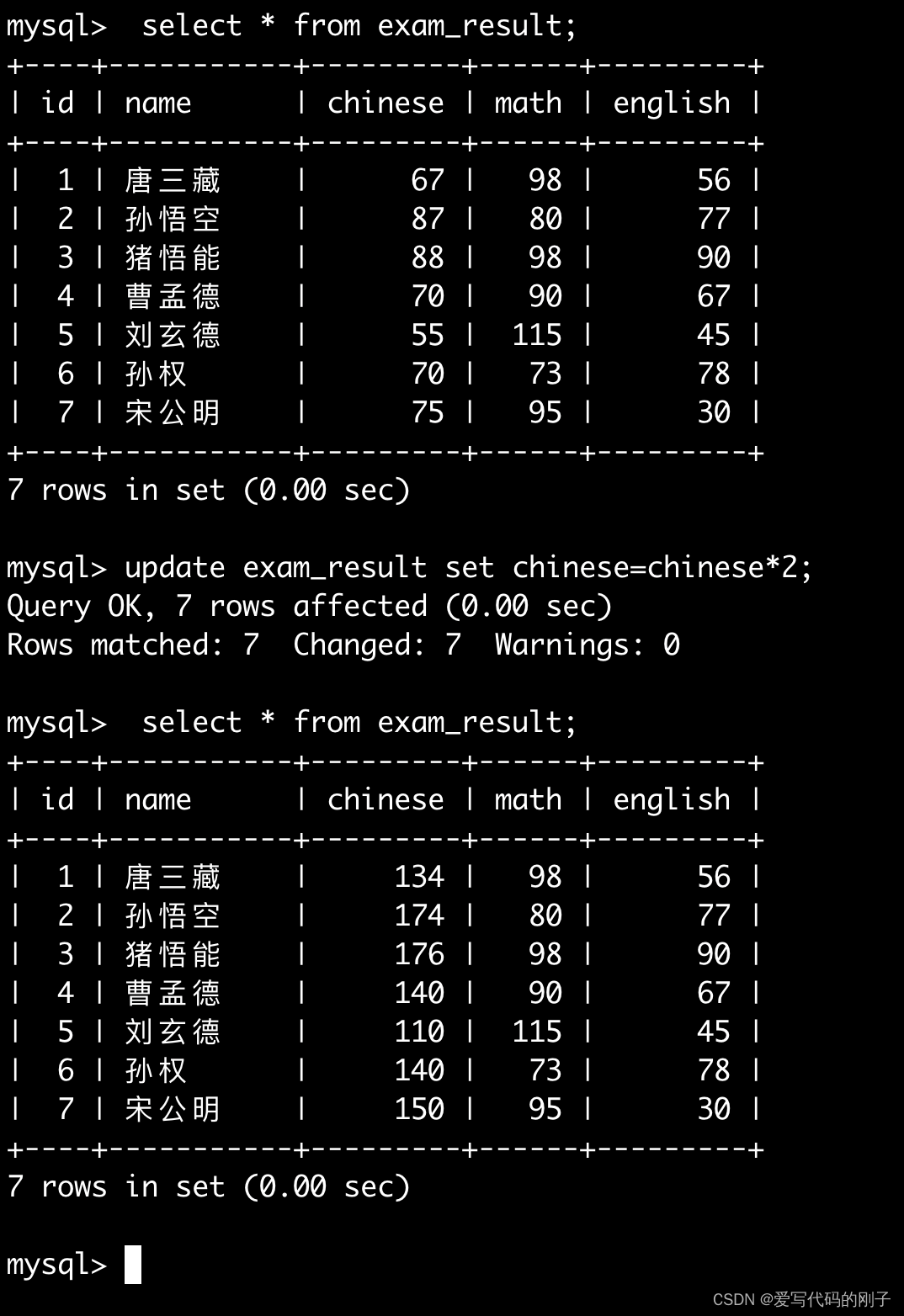
将孙悟空同学的数学成绩变更为 80 分
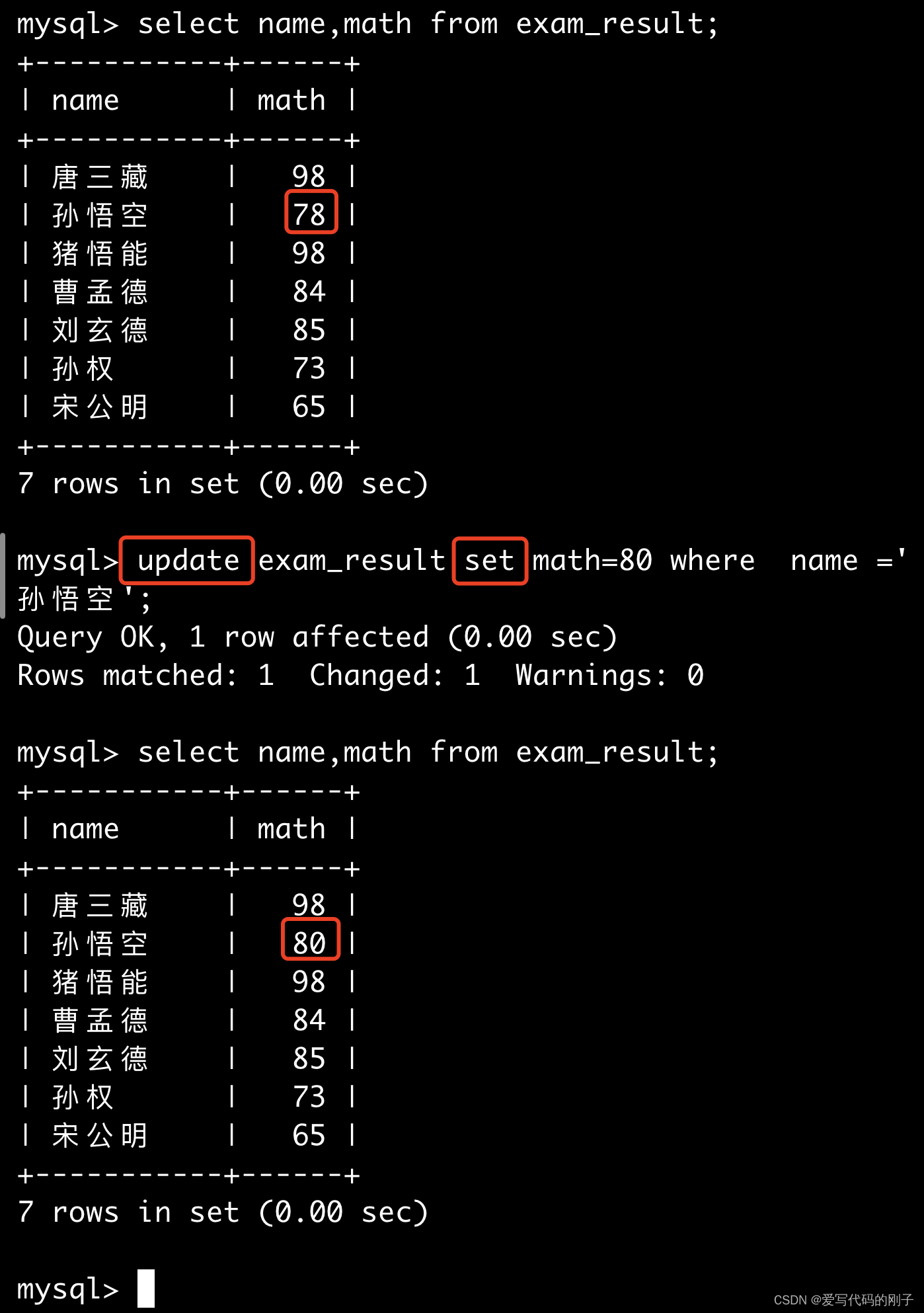
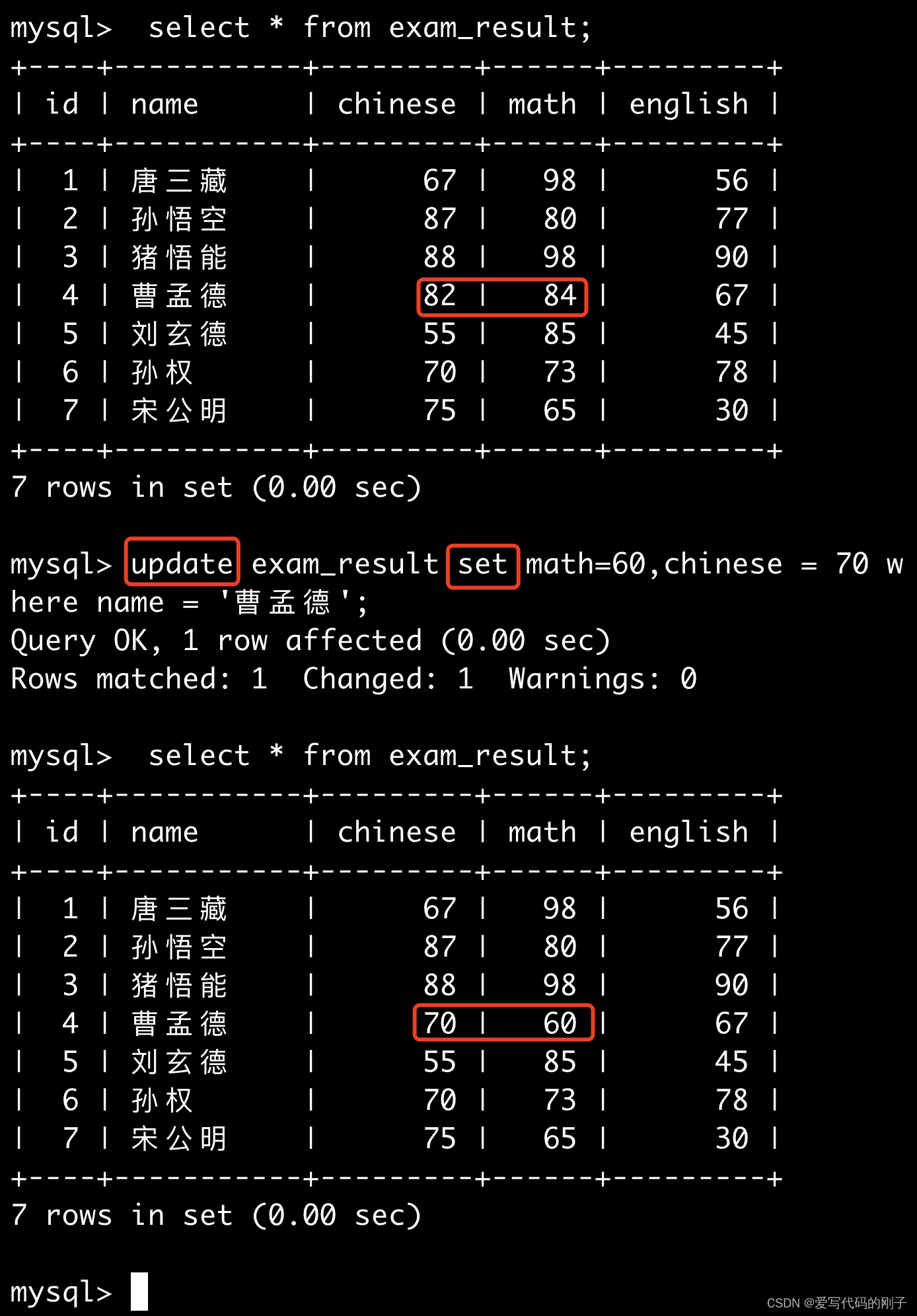
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
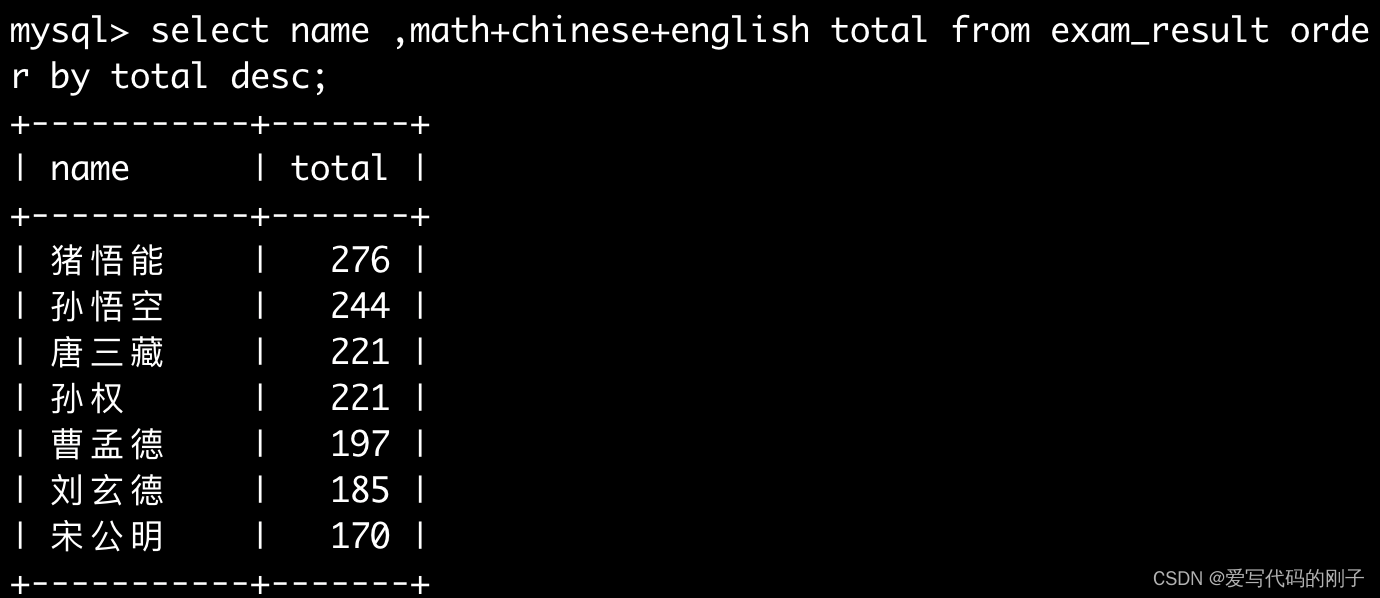
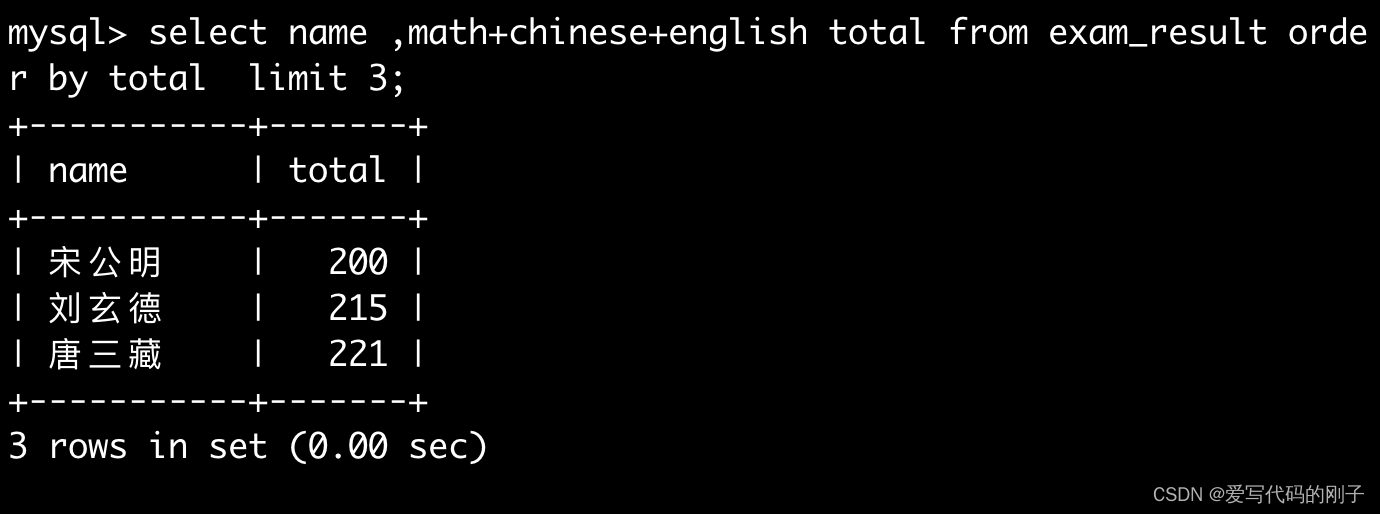
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分

将所有同学的语文成绩更新为原来的 2 倍
Delete
删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
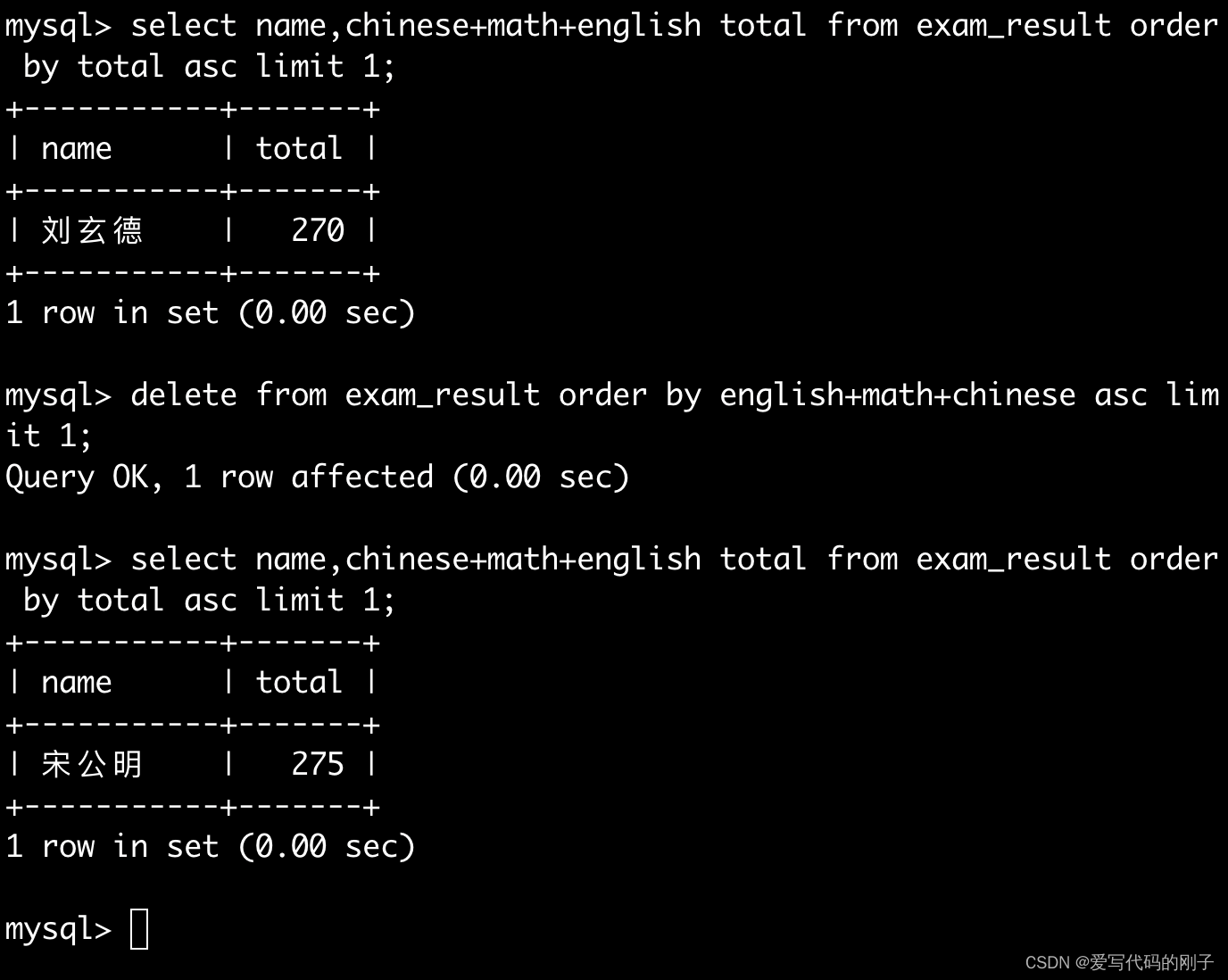
删除孙悟空同学的考试成绩

删除倒数第一名同学
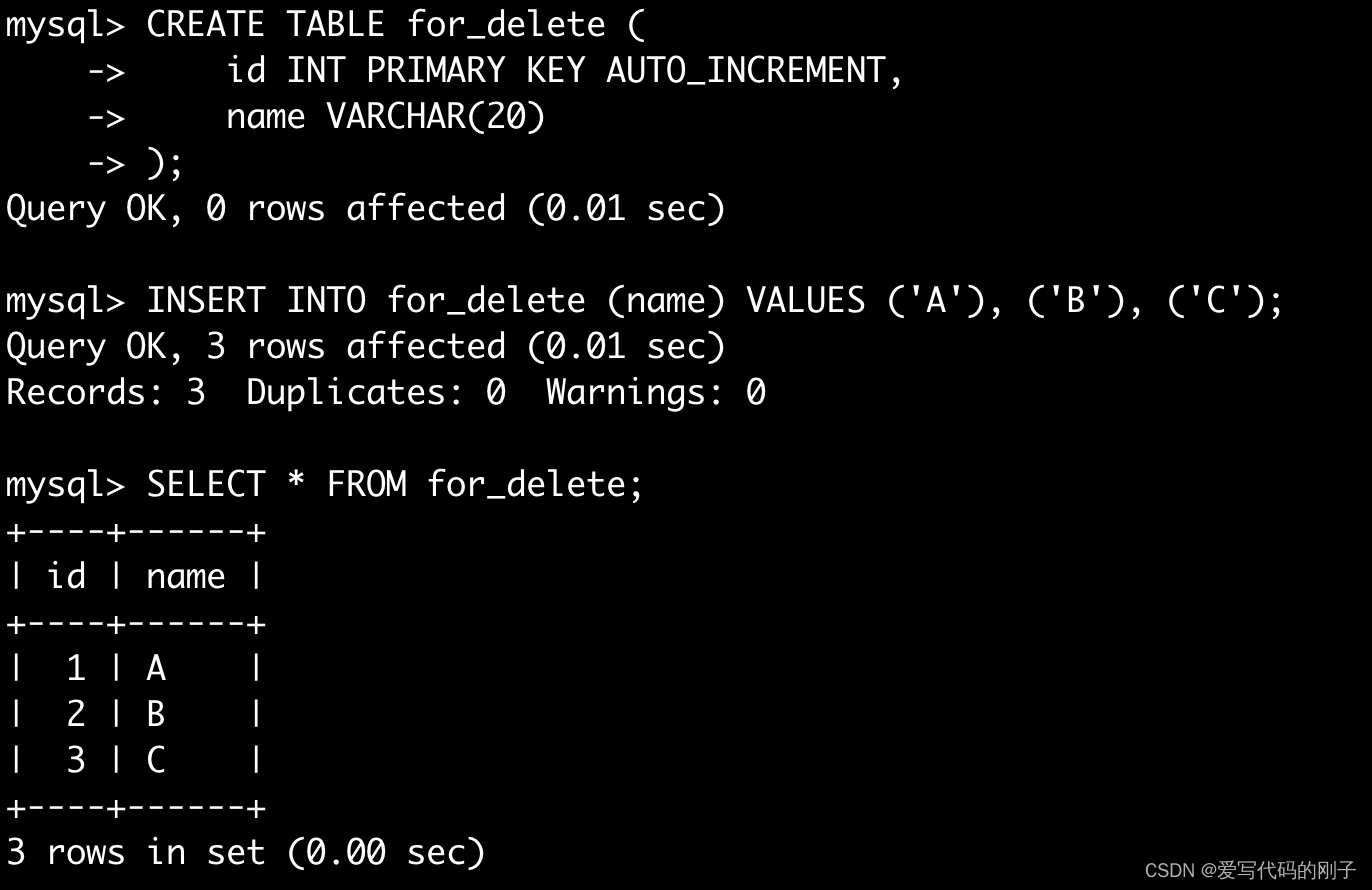
删除整张表数据
注意:删除整表操作要慎用!
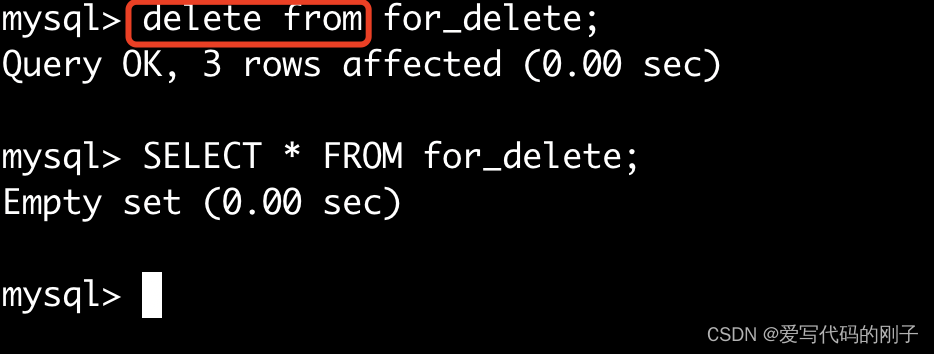
- 会有 AUTO_INCREMENT=n项
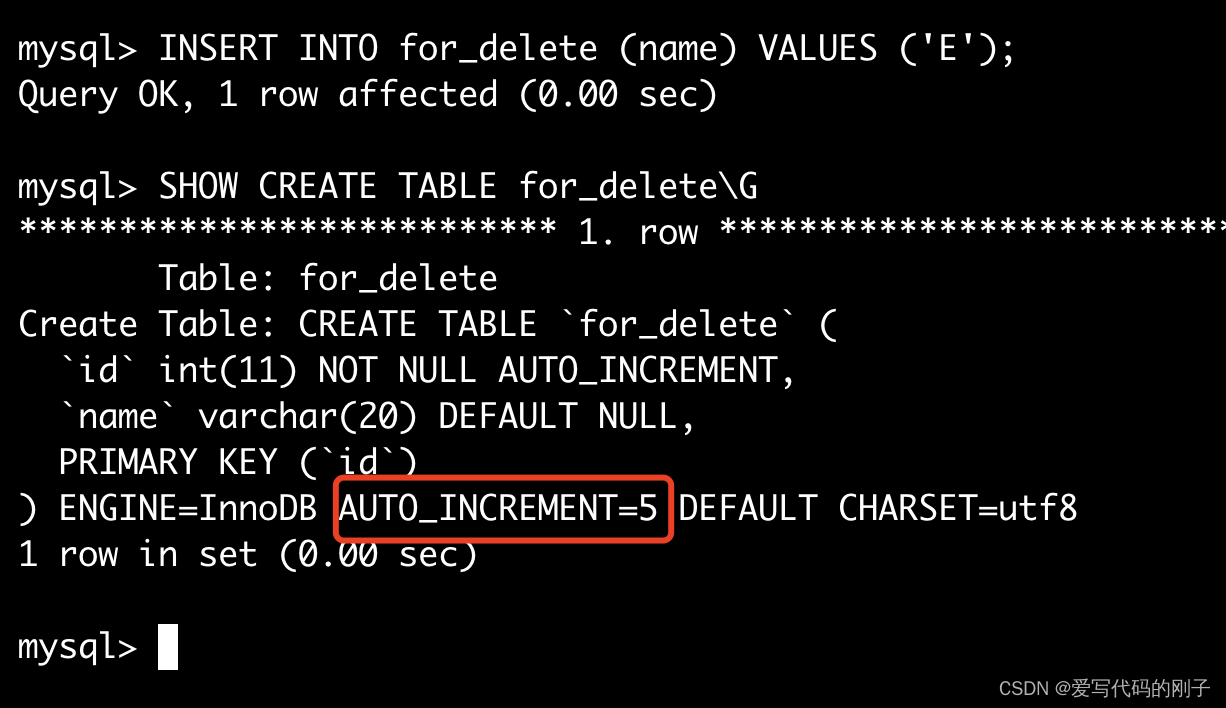
所以delete操作不会将AUTO_INCREMENT清空
截断表
语法:
TRUNCATE [TABLE] table_name
这个关键字直接将表清空,不走事务,delete走事务
TRUNCATE不会将自己的操作记录在日志里!,比delete快
注意:这个操作慎用
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置AUTO_INCREMENT项
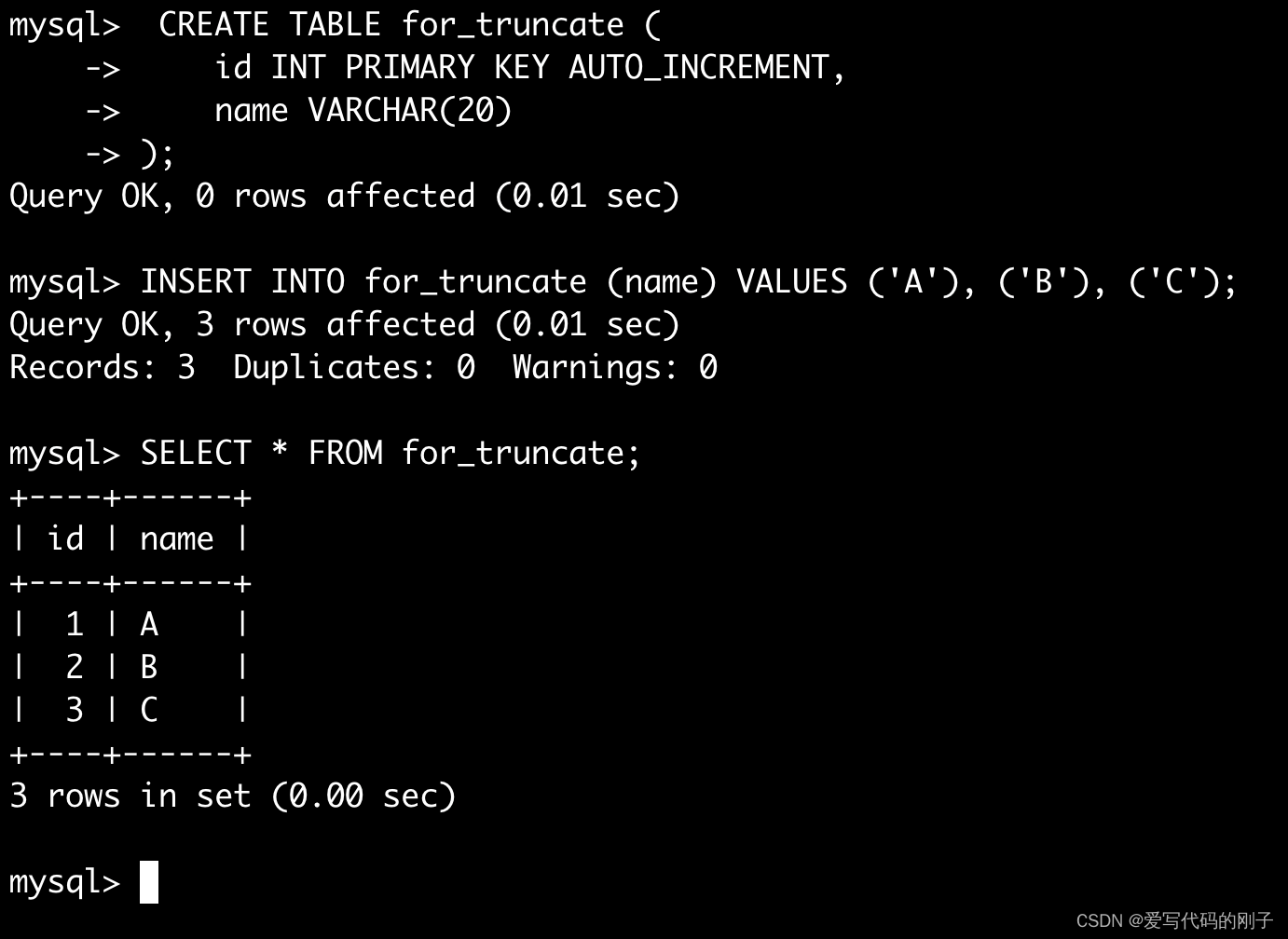
- 表还在只不过内容进行了清空
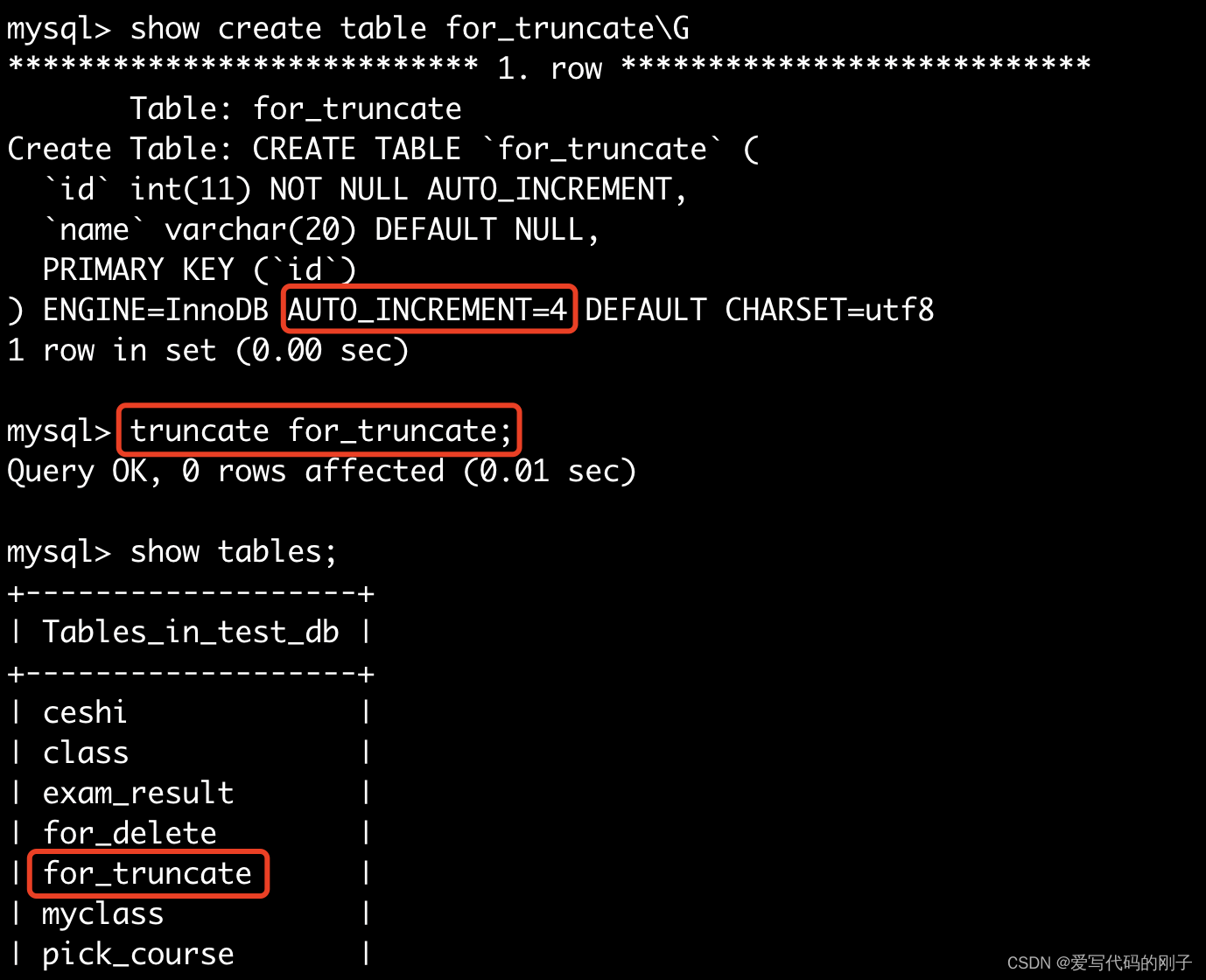
- truncate会清空AUTO_INCREMENT项
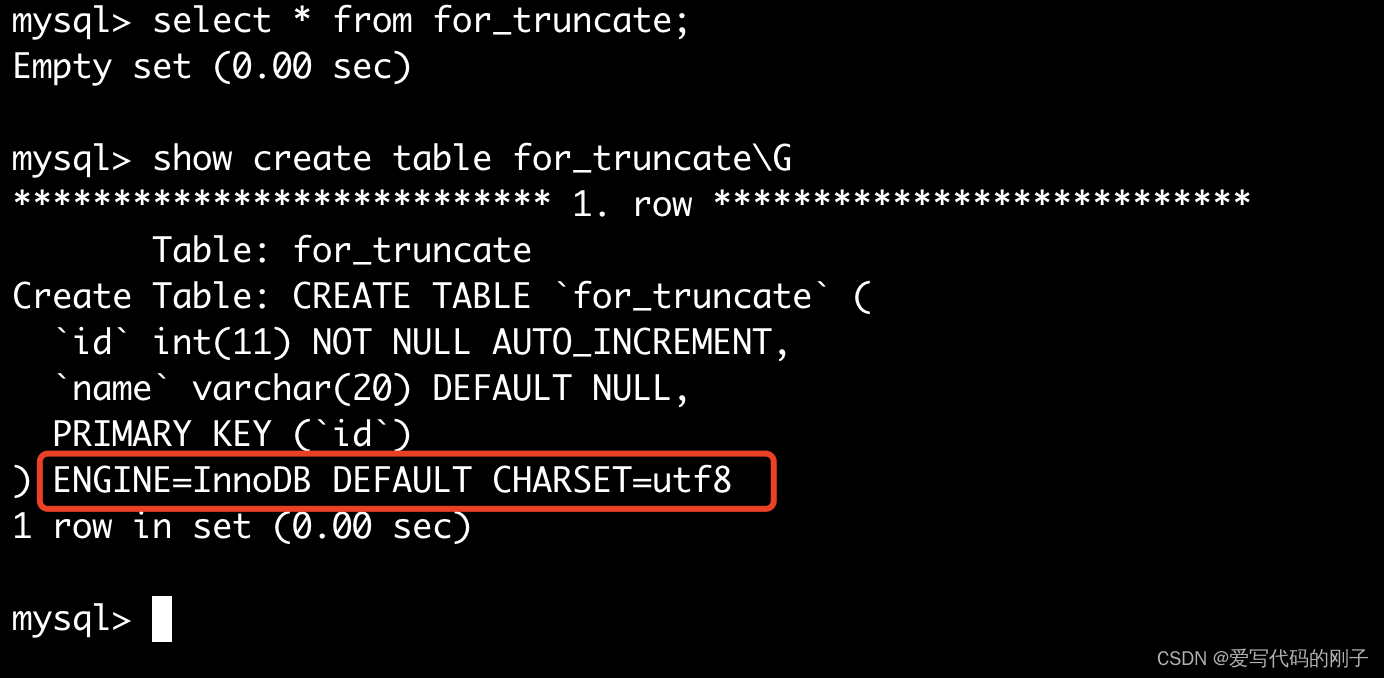
- AUTO_INCREMENT项重新计数

- mysql会有对应的log来记录我们的操作
关于持久化方式:
- 记录历史SQL语句(bin log,实现主从同步,默认情况先bin log是被关闭的(配置问题))
- 记录数据本身
插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中的重复记录,重复的数据只能有一份
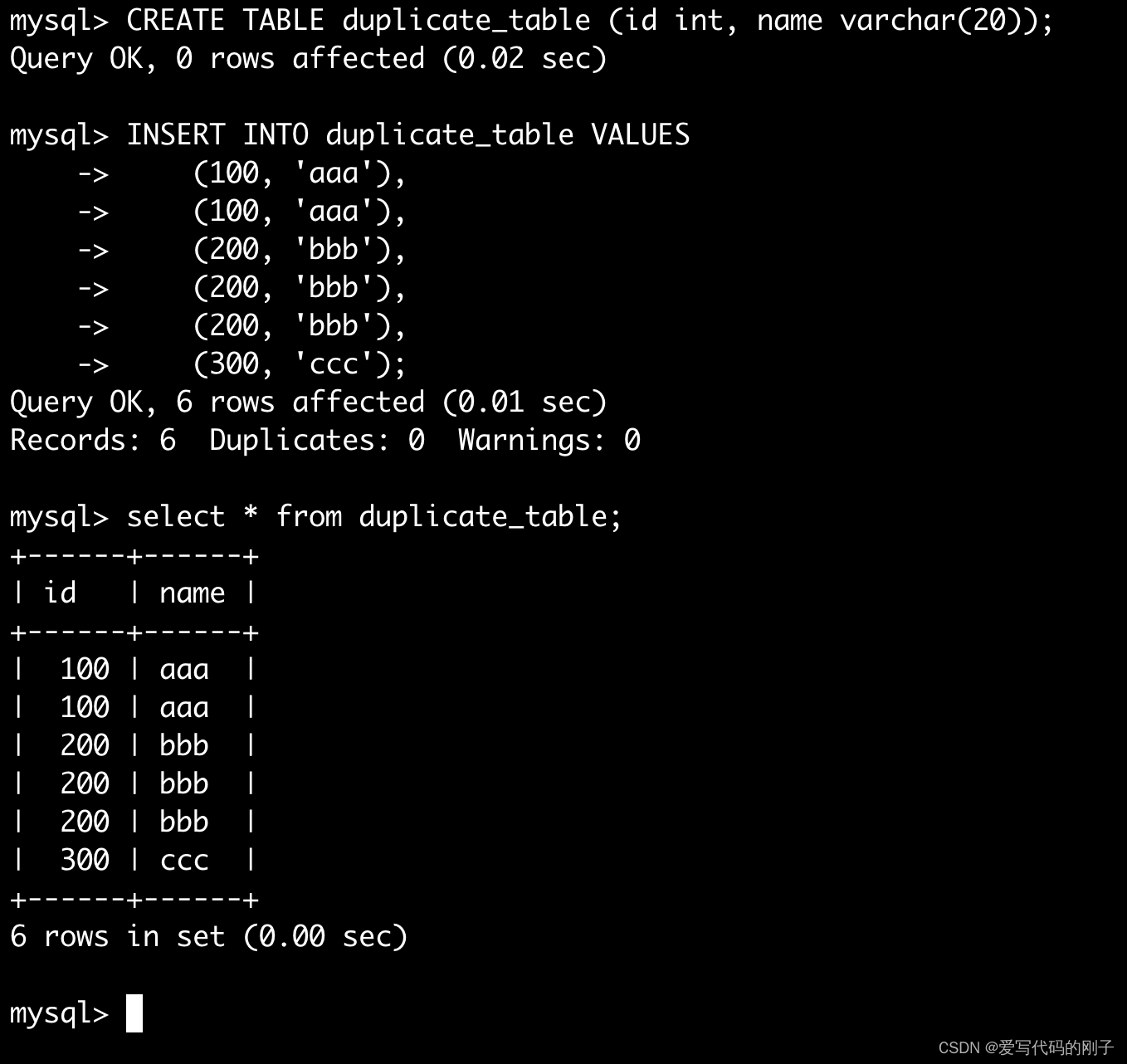
- 我们之前有介绍select也有去重的功能:
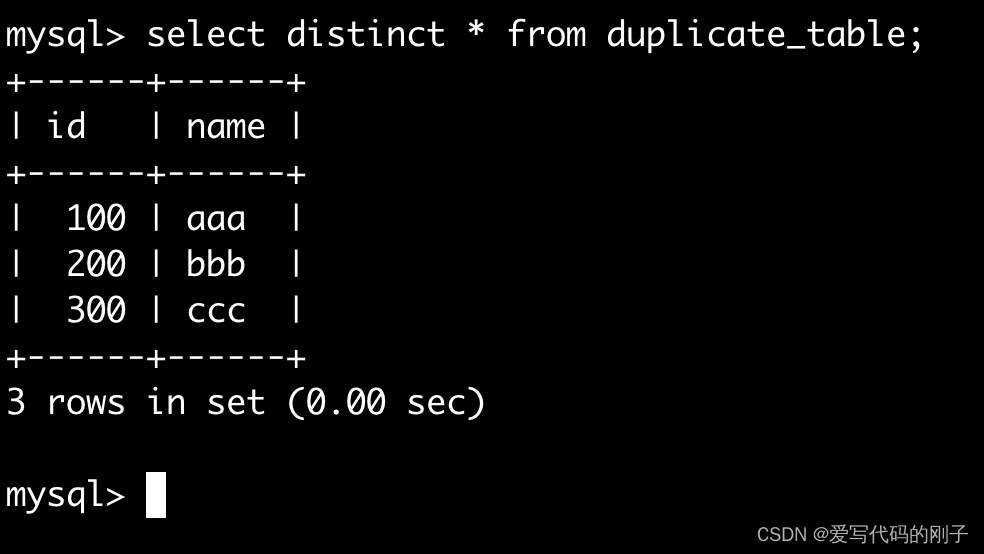
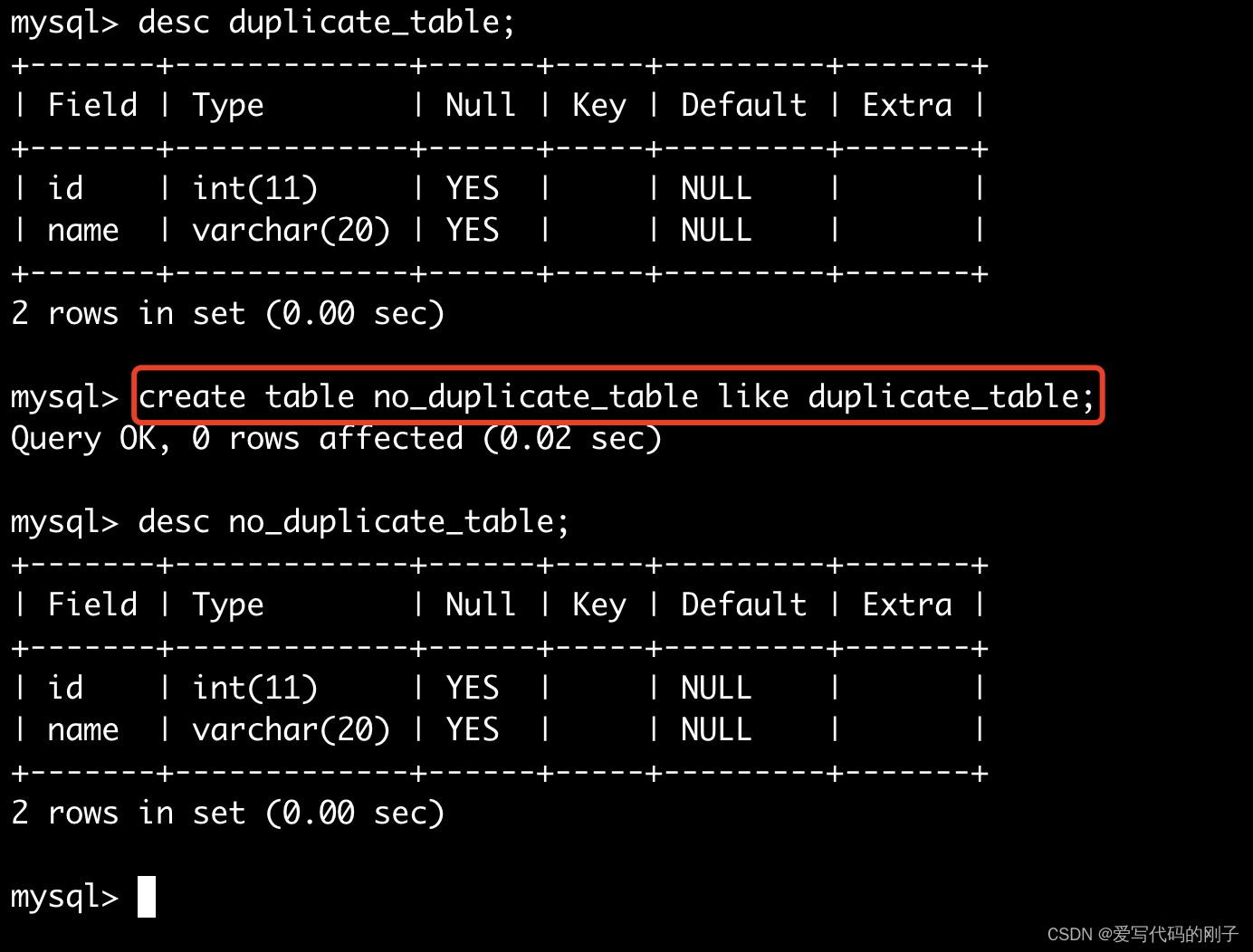
具体实现去重表的操作:
- 创建一张结构一样的空表:
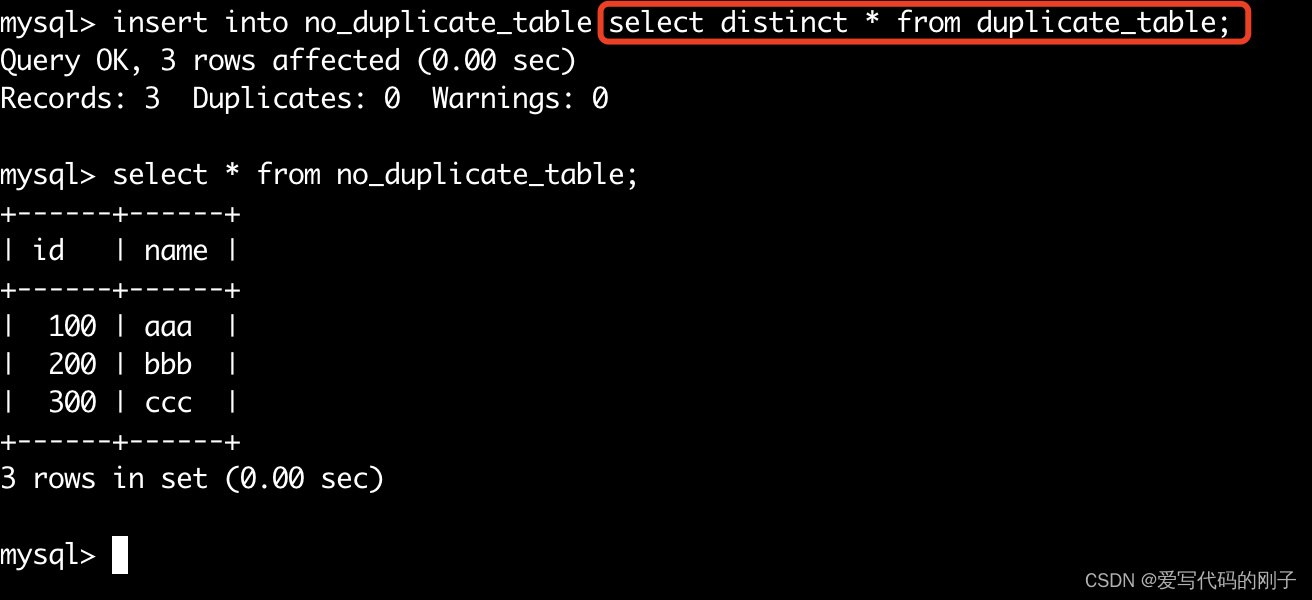
- 使用insert语句和select语句配合使用:
- 将已经去重了的新表进行重命名:

- 这样就得到了一个去重的表:

【问题】:为什么最后是通过rename方式进行的?
就是单纯的想等一切都就绪了,然后统一放入、更新、生效等。(因为有可能有其他用户在访问该数据库)
聚合统计(聚合函数)
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
COUNT:
案例:
统计班级共有多少学生
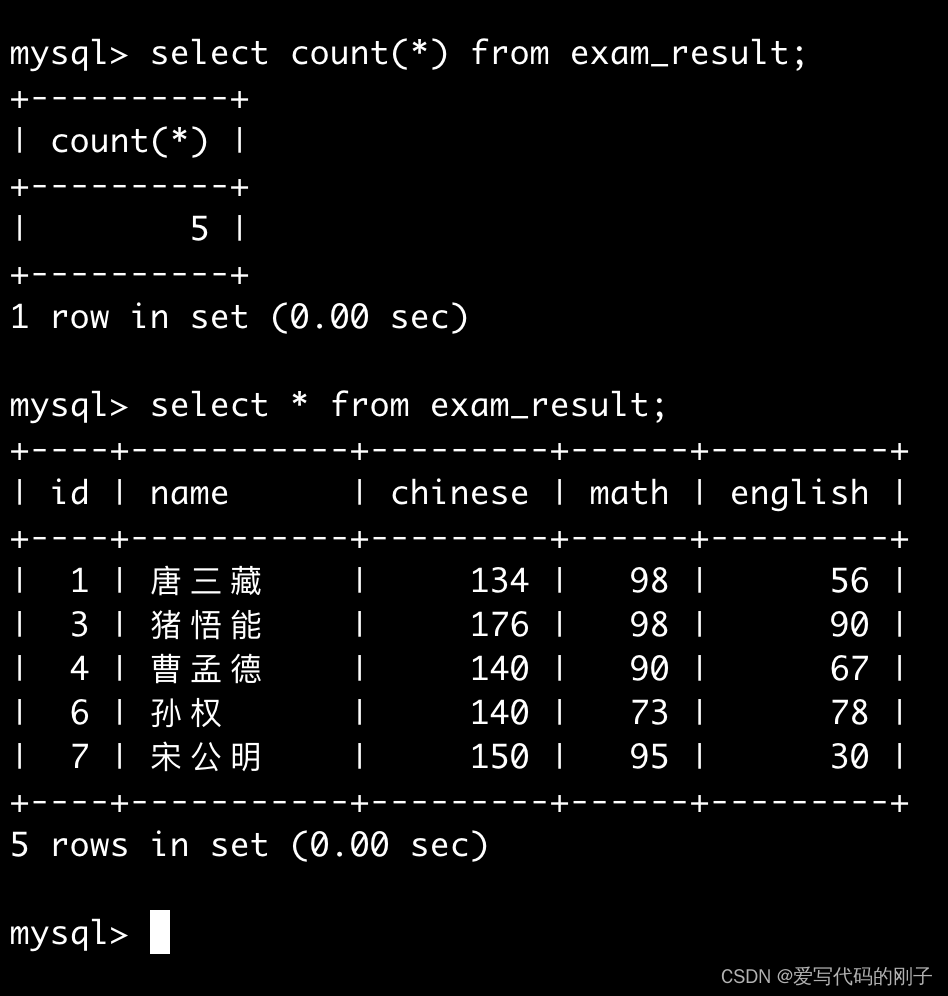
- 另一种写法:
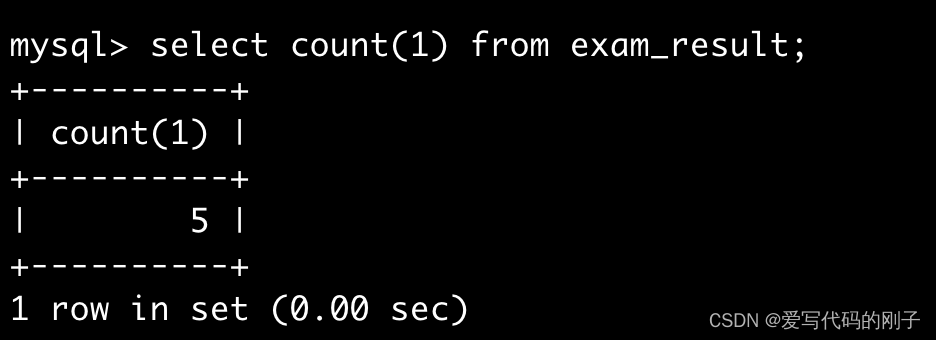
统计本次考试的数学成绩分数个数

- 也可以使用res进行重命名
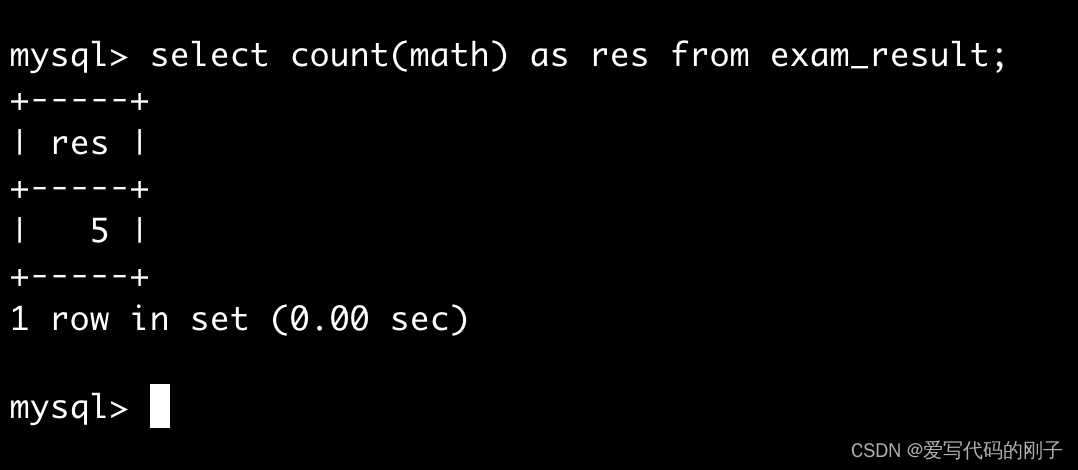
能否对math去重然后再统计?:
- 错误写法:
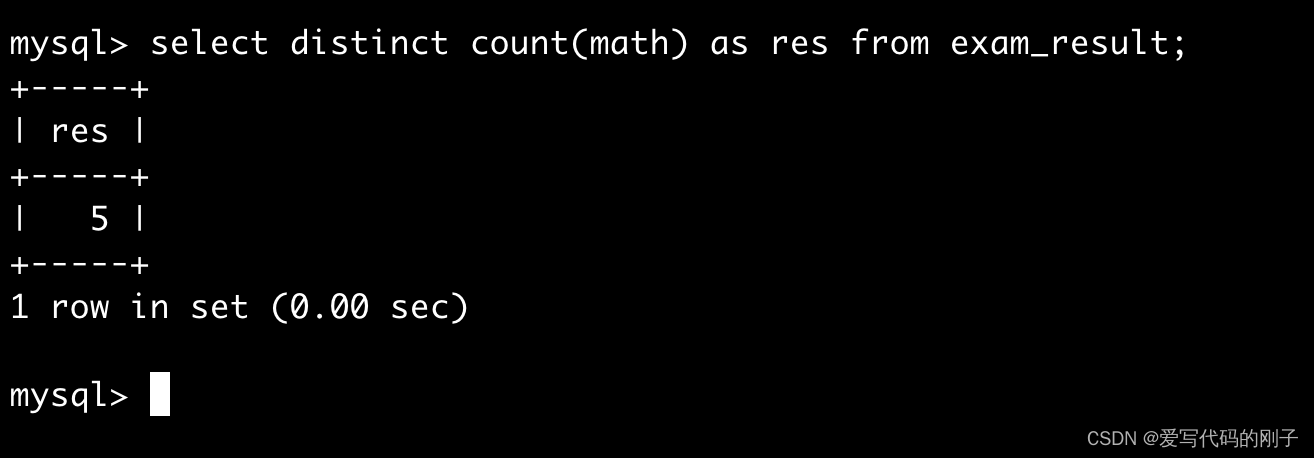
这样写表示对res去重
- 正确写法是先去重再count

SUM
案例:
统计数学成绩的总分
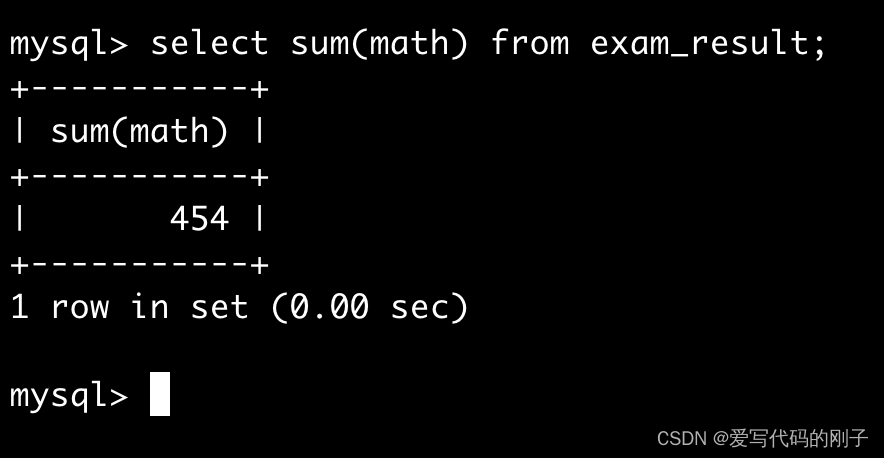
统计数学平均分
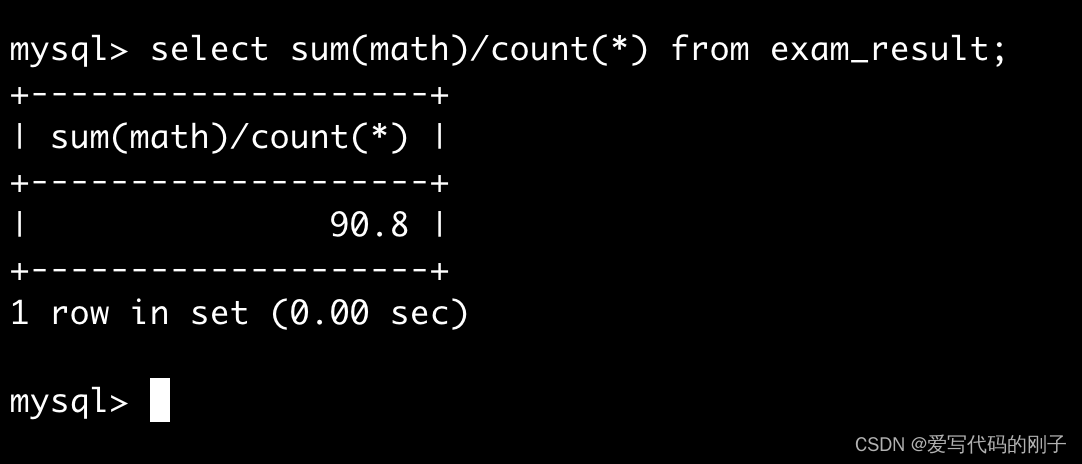
统计英语小于60分的人

AVG
案例:
统计数学平均分

MIN和MAX
案例:
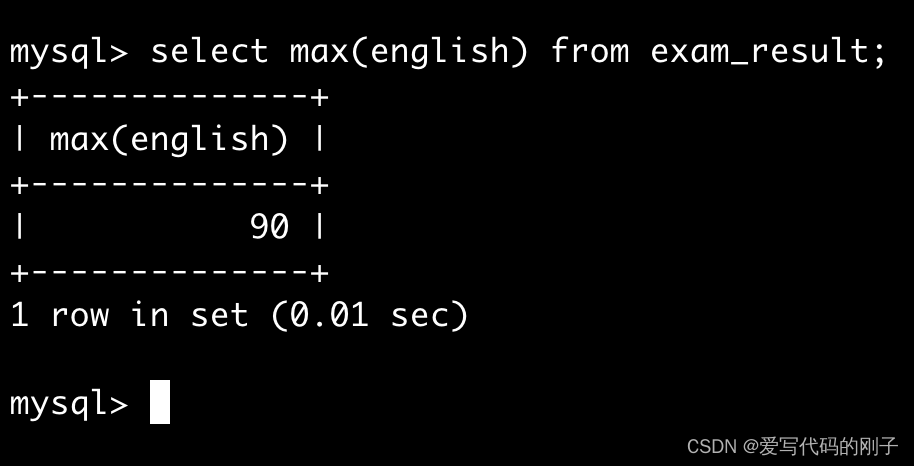
返回英语最高分
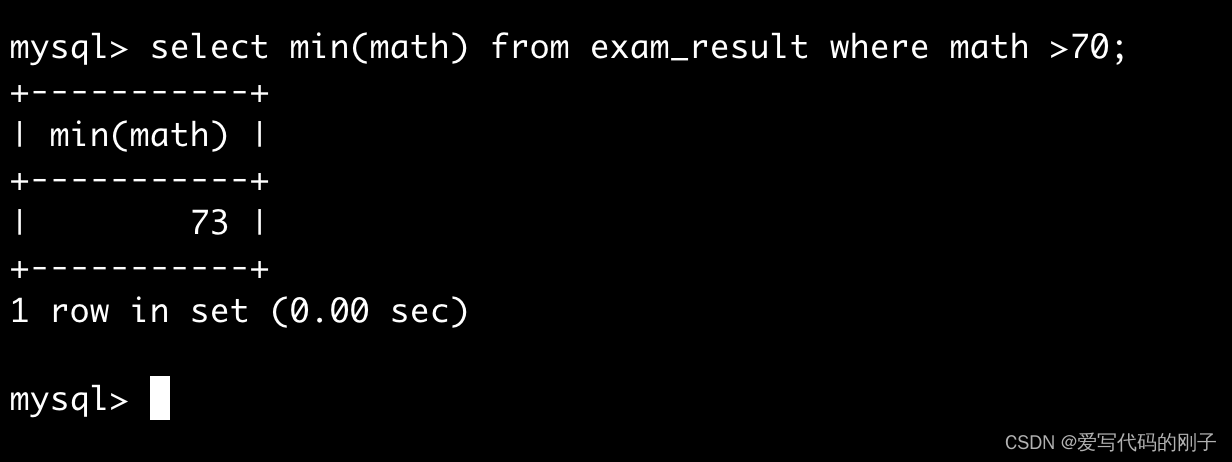
返回 > 70分以上的数学最低分
group by子句的使用(分组聚合统计)
分组的目的是为了进行分组(按需求,指定列名,实际是用该列的不同的行数据进行分组的)之后,方便进行聚合统计
分组,不就是把一组按照条件拆成了多个组,进行各自组内的统计(分组不就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计)
思想:先分组,再聚合
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
案例:
- 准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
- 显示总平均工资:

- 如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;
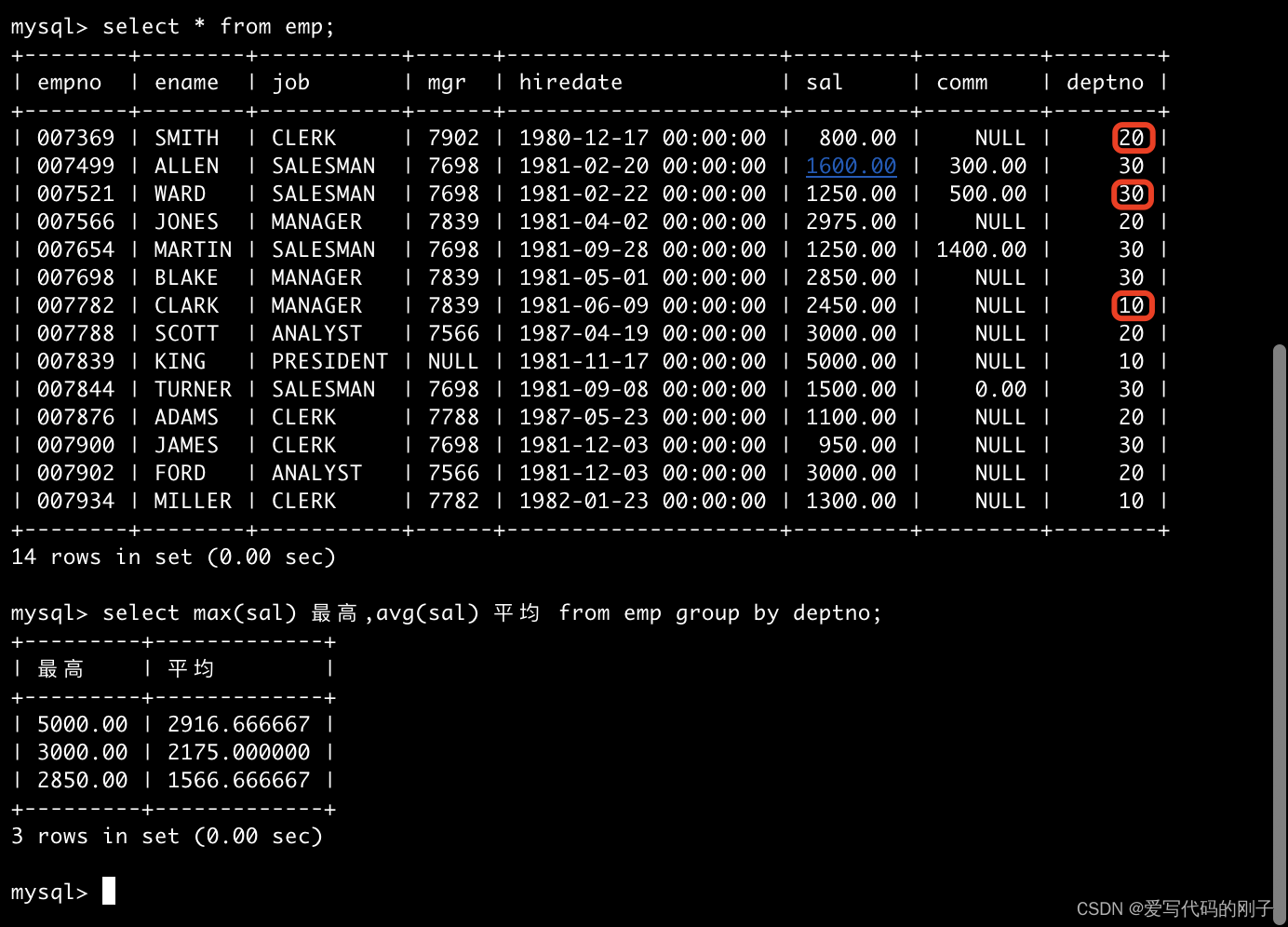
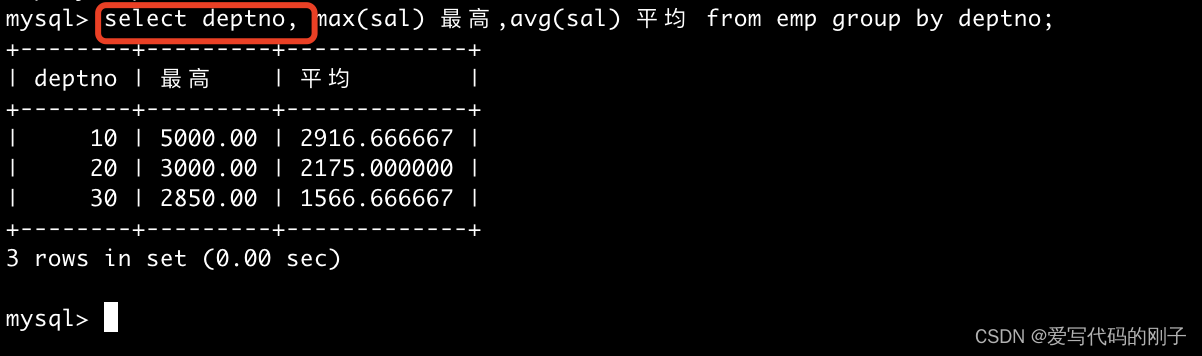
分组的条件deptno,组内一定是相同的!可以被聚合压缩
- 显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;
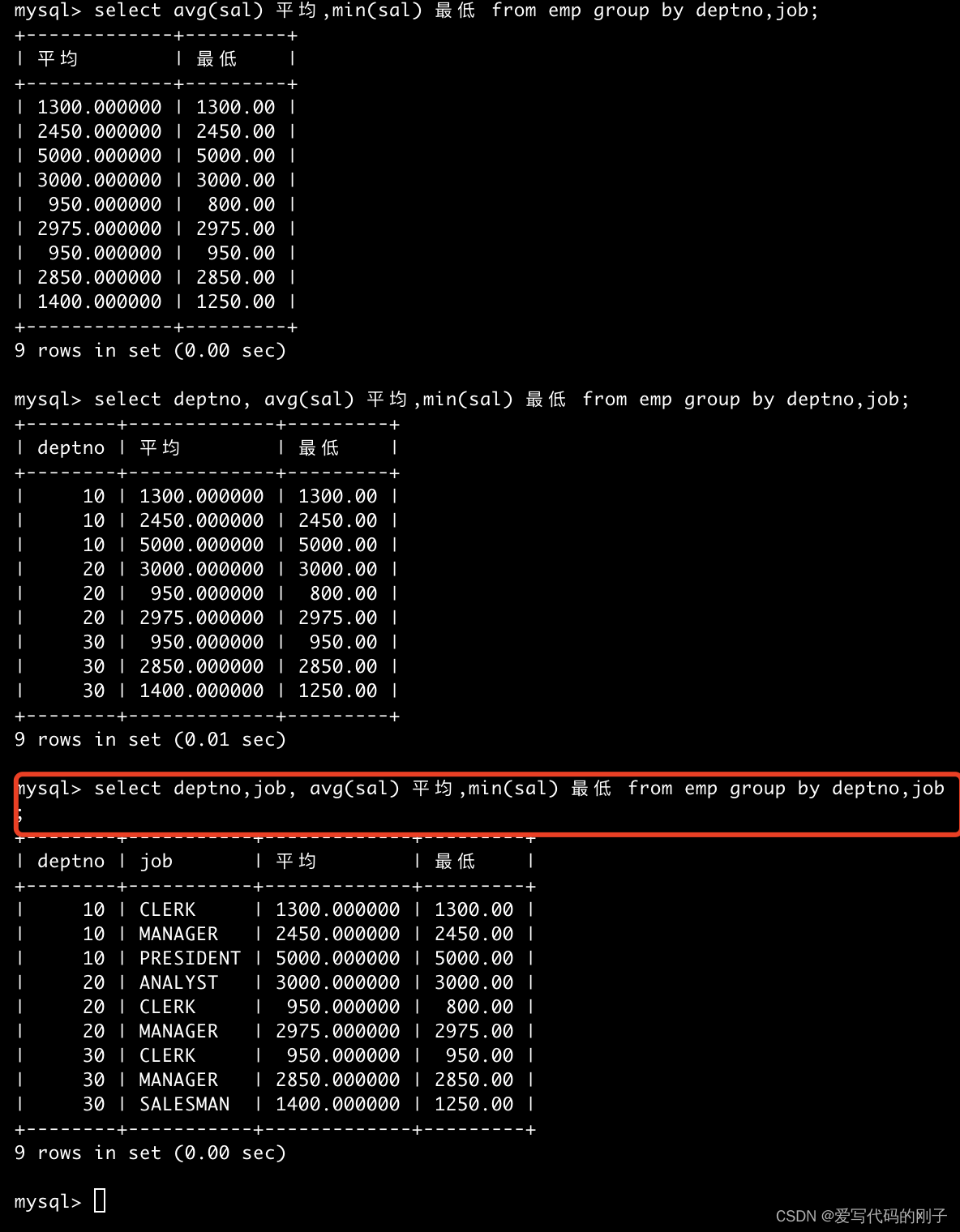
- 分析一个错误:为什么ename会报错:
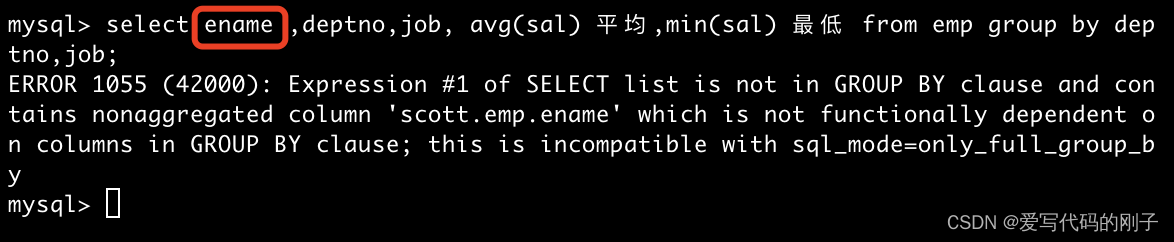
因为ename不在分组条件里面,无法进行分组,无法进行压缩和聚合。
显示平均工资低于2000的部门和它的平均工资
- 统计各个部门的平均工资(先聚合)
select avg(sal) from EMP group by deptno- having和group by配合使用,对group by结果进行过滤(再判断)
select avg(sal) as myavg from EMP group by deptno having myavg<2000; --having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
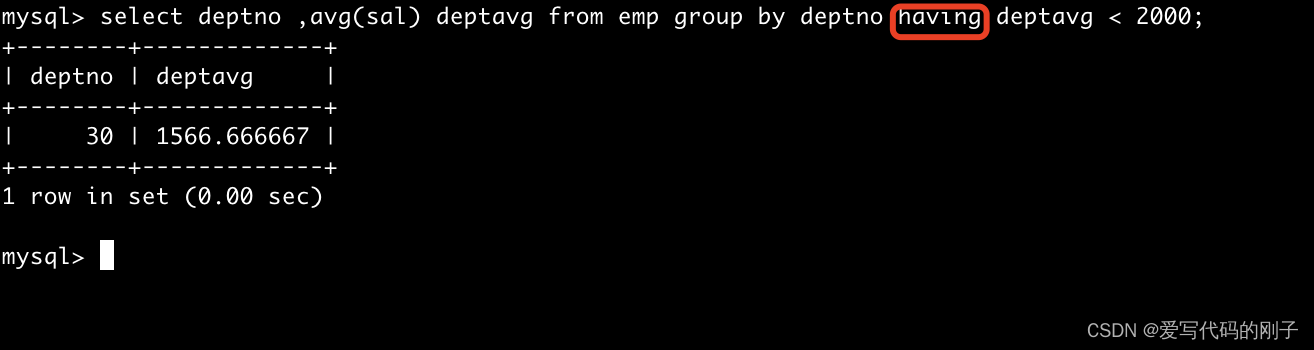
having是对聚合后的统计数据,条件筛选。
having VS where 区别理解
执行顺序,构建对“结果”的理解
- 之前的mysql语句having换成where会报错

- 但是这样却不报错:
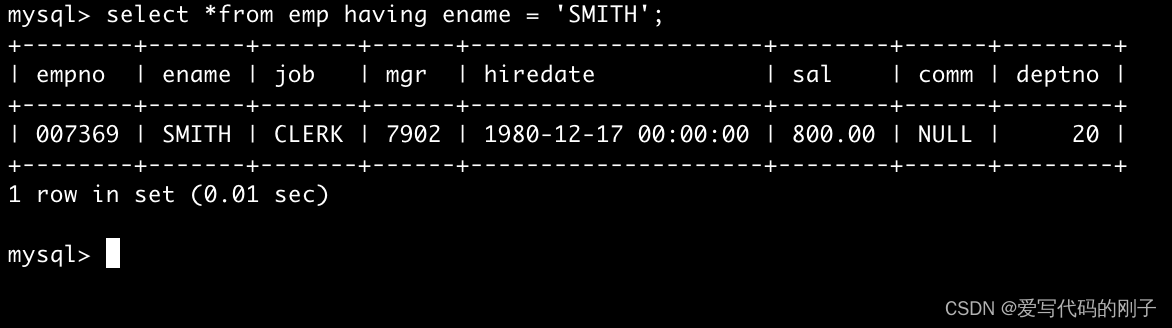
因为:即使没被分组,也可以看成是一组数据(但是我们选择禁止这样使用)
再举例:SMITH员工不参与统计
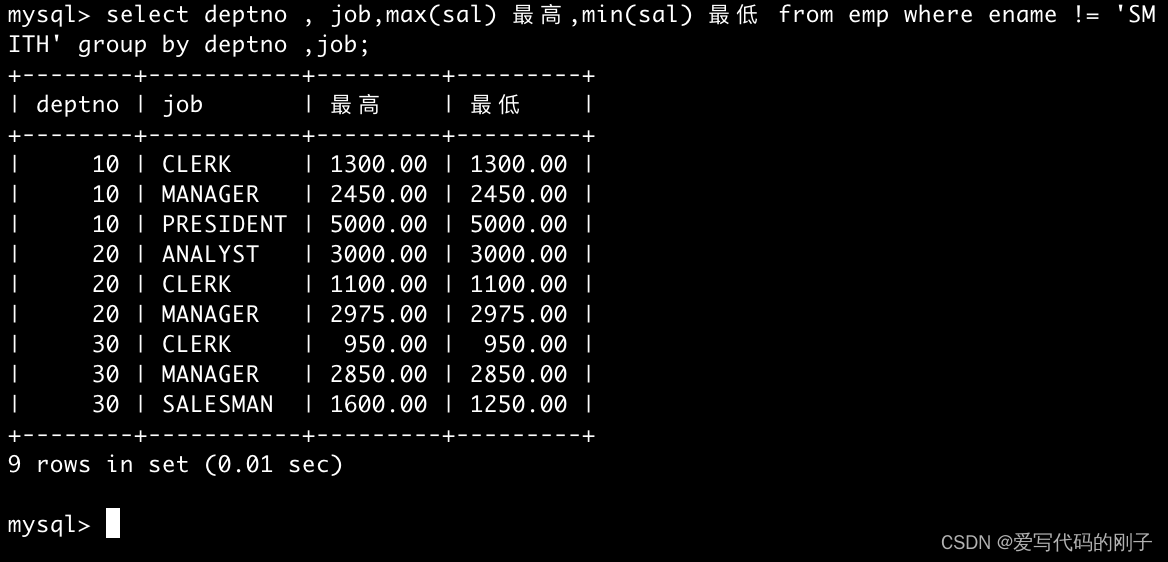
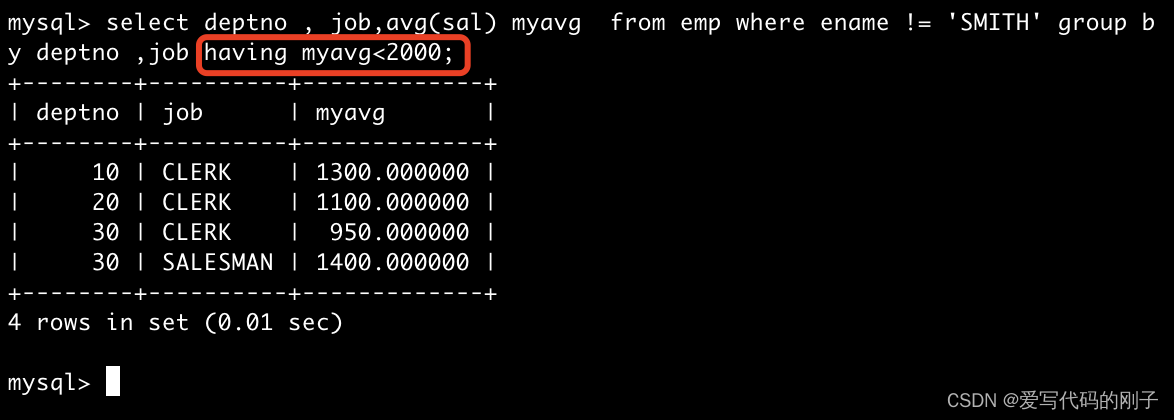
where:对具体的任意列进行条件筛选
having:对分组聚合之后的结果进行条件筛选
执行顺序:
from->where->group->聚合统计+重命名->having
所以where和having的区别在于条件筛选的阶段是不同的!
【附】:
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
- 不要单纯的认为,只有在磁盘上表结构导入到mysql,真实存在的表,才叫做表
- 中间筛选出来的,包括最终结果,全部都是逻辑上的表!“MySQL一切皆表”,未来只要我们能够处理好单表的CURD,所有的sql场景,我们全部都能用统一的方式进行

























![[蓝桥杯 2022 省 A] 求和](https://img-blog.csdnimg.cn/direct/0aebe81402c24df38fa58b8c24bb3e8b.png)