堆排序在优先队列的应用及其C代码示例
一、引言
堆排序(Heap Sort)是一种基于比较的排序算法,它利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序通过建堆和不断调整堆的过程,达到排序的目的。而优先队列(Priority Queue)是一种抽象数据类型,它类似于普通的队列或栈数据结构,但每一个元素都有一个相关的值,称之为“优先级”。优先队列中的元素根据其优先级进行处理,优先级最高的元素最先得到处理。堆排序在优先队列的实现中发挥着重要作用,尤其是在需要频繁进行插入和删除最大(或最小)元素的操作时。
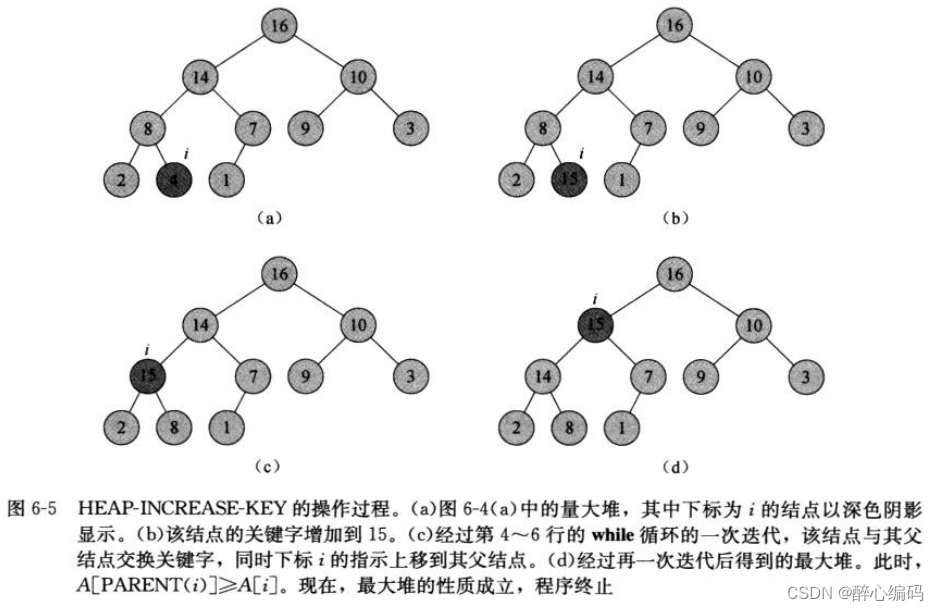
二、堆排序的基本思想
堆排序的基本思想是将待排序的序列构造成一个大顶堆或小顶堆。此时,整个序列的最大值(或最小值)就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个序列重新构造成一个堆,这样会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列了。
三、优先队列的实现
优先队列可以通过堆来实现,因为堆具有一种特性:父节点的值总是大于或等于(大顶堆)或小于或等于(小顶堆)其子节点的值。这使得堆顶元素总是具有最高(或最低)的优先级。优先队列的主要操作包括插入元素、删除最高(或最低)优先级元素以及调整堆。
插入元素:将新元素插入到堆的末尾,然后通过不断地与父节点比较和交换(上浮操作),直到满足堆的性质。
删除最高(或最低)优先级元素:将堆顶元素与堆的最后一个元素交换,然后删除堆的最后一个元素。接着,通过不断地与子节点比较和交换(下沉操作),重新调整堆以满足堆的性质。
调整堆:在插入或删除元素后,可能需要通过上浮或下沉操作来重新调整堆以满足堆的性质。
优先队列的一个典型应用是作业调度。在共享计算机系统中,有多个作业需要被执行,而每个作业都有其优先级。优先队列可以记录这些作业以及它们的优先级,当需要执行作业时,可以从优先队列中选择优先级最高的作业来执行。
堆排序在优先队列中的应用主要体现在两个方面:一是构建初始的优先队列(即建堆),二是维护优先队列的性质(即插入和删除操作)。通过堆排序,我们可以高效地实现优先队列的插入、删除和查找最高(或最低)优先级元素的操作。
四、最大优先队列的实现
最大优先队列是一种特殊的优先队列,它总是返回并删除具有最大优先级的元素。基于最大堆实现最大优先队列是一种常见的方法。
最大优先队列的主要操作包括:
插入元素:将新元素插入到最大堆中,并重新调整堆结构以保持堆属性。
删除最大元素:删除堆顶元素(即最大元素),并将堆的最后一个元素移动到堆顶,然后重新调整堆结构。
获取最大元素:返回堆顶元素的值,但不删除它。
在实现过程中,我们可以使用数组来存储堆的元素,并维护一个变量来记录堆的大小。插入元素时,将新元素添加到数组的末尾,并通过上浮操作(percolate up)调整堆结构。删除最大元素时,将数组的最后一个元素移动到堆顶,并通过下沉操作(percolate down)调整堆结构。获取最大元素时,直接返回堆顶元素的值即可。
五、最小优先队列的实现
最小优先队列与最大优先队列类似,它总是返回并删除具有最小优先级的元素。基于最小堆实现最小优先队列是一种常见的方法。
最小优先队列的主要操作与最大优先队列类似,包括插入元素、删除最小元素和获取最小元素。在实现过程中,我们只需要将最大堆替换为最小堆即可。具体来说,插入元素时,将新元素添加到数组的末尾,并通过上浮操作调整堆结构以保持最小堆属性;删除最小元素时,将数组的最后一个元素移动到堆顶,并通过下沉操作调整堆结构;获取最小元素时,直接返回堆顶元素的值。
六、性能分析
堆排序在优先队列中的应用具有优异的性能表现。由于堆的插入、删除和查找操作的时间复杂度均为O(log n),因此最大优先队列和最小优先队列的主要操作也具有相同的时间复杂度。这使得堆排序在处理大量数据时能够保持高效的性能。
此外,堆排序还具有空间复杂度低的优势。由于堆排序主要使用数组来存储元素,因此其空间复杂度为O(n),其中n为待排序元素的数量。这使得堆排序在空间效率上也表现出色。
然而,需要注意的是,虽然堆排序在优先队列中表现出色,但它并不适用于所有场景。在某些特定情况下,其他排序算法可能具有更好的性能。因此,在选择排序算法时,我们需要根据具体的应用场景和需求进行权衡和选择。
七、C代码示例
以下是一个基于堆排序实现的优先队列的C代码示例:
c
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int size;
} PriorityQueue;
// 交换两个元素
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 上浮操作,调整堆
void heapify(PriorityQueue *pq, int i) {
int largest = i; // 初始化largest为根节点
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
// 如果左子节点大于根节点
if (left < pq->size && pq->data[left] > pq->data[largest]) {
largest = left;
}
// 如果右子节点大于目前已知的最大节点
if (right < pq->size && pq->data[right] > pq->data[largest]) {
largest = right;
}
// 如果最大节点不是根节点
if (largest != i) {
swap(&pq->data[i], &pq->data[largest]);
// 递归调整受影响的子堆
heapify(pq, largest);
}
}
// 插入元素到优先队列
void insert(PriorityQueue *pq, int key) {
if (pq->size == MAX_SIZE) {
printf("Priority queue is full\n");
return;
}
pq->data[pq->size] = key;
pq->size++;
// 从新插入的节点开始上浮,调整堆
int i = pq->size - 1;
while (i && pq->data[(i - 1) / 2] <pq->data[i]) {
swap(&pq->data[i], &pq->data[(i - 1) / 2]);
i = (i - 1) / 2;
}
}
// 删除最高优先级元素(堆顶元素)
int deleteTop(PriorityQueue *pq) {
if (pq->size == 0) {
printf("Priority queue is empty\n");
return -1;
}int root = pq->data[0];
// 将最后一个元素替换为根节点
pq->data[0] = pq->data[pq->size - 1];
pq->size--;
// 从根节点开始下沉,调整堆
heapify(pq, 0);
return root;
}
// 构建优先队列(建堆)
void buildHeap(PriorityQueue *pq) {
// 从最后一个非叶子节点开始,依次对每个非叶子节点进行下沉操作
for (int i = pq->size / 2 - 1; i >= 0; i--) {
heapify(pq, i);
}
}
// 打印优先队列
void printPriorityQueue(PriorityQueue *pq) {
printf("Priority Queue: ");
for (int i = 0; i < pq->size; i++) {
printf("%d ", pq->data[i]);
}
printf("\n");
}
int main() {
PriorityQueue pq;
pq.size = 0;// 插入元素到优先队列
insert(&pq, 5);
insert(&pq, 2);
insert(&pq, 10);
insert(&pq, 1);
insert(&pq, 8);
// 构建优先队列
buildHeap(&pq);
// 打印优先队列
printPriorityQueue(&pq);
// 删除最高优先级元素并打印
printf("Deleted element: %d\n", deleteTop(&pq));
printPriorityQueue(&pq);
return 0;
}
这段代码实现了一个简单的优先队列,使用堆排序来维护队列的性质。PriorityQueue结构体包含一个整数数组data用于存储队列元素,以及一个整数size表示队列的大小。insert函数用于插入元素到优先队列,deleteTop函数用于删除最高优先级元素(即堆顶元素),buildHeap函数用于构建优先队列(即建堆),printPriorityQueue函数用于打印优先队列。
在主函数中,我们创建了一个空的优先队列pq,然后插入了一些元素。接着,我们调用buildHeap函数构建优先队列,然后打印出队列的内容。最后,我们删除最高优先级元素并再次打印队列的内容。
需要注意的是,这段代码中的堆是大顶堆,即父节点的值总是大于或等于其子节点的值。因此,在插入元素时,我们需要通过上浮操作来调整堆;在删除最高优先级元素时,我们需要通过下沉操作来调整堆。这样,我们就能保证优先队列的性质始终得到维护。
八、应用场景与实例
堆排序和优先队列在多种实际应用中都发挥着重要作用。以下是几个典型的应用场景和实例:
任务调度:在操作系统中,任务调度器经常使用优先队列来管理正在运行和等待运行的任务。最大优先队列可以确保优先级最高的任务首先得到执行,而最小优先队列则可以用于实现轮转调度等公平策略。
数据流处理:在处理实时数据流时,优先队列可以用来实现滑动窗口内的最大值或最小值跟踪。例如,在金融市场中,交易系统可能需要实时计算某一时间段内的最高和最低交易价格。
图算法:在图论中,优先队列经常用于实现诸如Dijkstra算法和Prim算法等。在这些算法中,优先队列用于存储待处理的节点,并根据节点的优先级(如距离或权重)进行排序。
网络流量控制:在网络通信中,优先队列可以用来管理不同类型的数据包,确保关键数据(如控制信令或实时音视频流)在拥塞时得到优先传输。
数据压缩:在数据压缩算法中,如哈夫曼编码,优先队列用于构建最优的二叉树,从而实现更高效的压缩。
实例:假设我们有一个实时监测系统,需要实时跟踪并分析一系列传感器的读数。这些读数可能表示温度、压力、湿度等环境参数。我们可以使用最小优先队列来实时获取当前最小的读数(可能是为了检测异常低值),同时使用最大优先队列来跟踪最大值(可能是为了预防过热或过压)。
九、堆排序与优先队列的进一步优化
使用斐波那契堆:传统的二叉堆在插入和删除时的最坏情况时间复杂度为O(log n)。而斐波那契堆是一种更加复杂但效率更高的数据结构,它提供了更优化的摊还时间复杂度。在某些场景下,斐波那契堆可以显著减少操作的平均时间。
懒惰删除:在某些应用中,我们可以采用懒惰删除策略,即不立即从堆中删除元素,而是将其标记为已删除。这样可以避免昂贵的重新堆化操作,直到必须执行这些操作时(例如,当堆的空间不足时)再进行处理。
并行化处理:对于大型数据集,我们可以考虑并行化堆排序和优先队列操作。通过利用多核处理器或分布式计算资源,可以显著提高处理速度。
缓存优化:在实际应用中,数据的局部性原理往往成立。因此,通过优化数据访问模式和使用缓存友好的数据结构,可以进一步提高堆排序和优先队列的性能。
十、结论
堆排序和优先队列是计算机科学中两个重要且相辅相成的概念。它们不仅在理论研究中占有重要地位,而且在各种实际应用中都发挥着关键作用。通过深入了解它们的原理、实现方式和优化策略,我们可以更加有效地解决各种计算问题并开发出更加高效和可靠的软件系统。
本文详细介绍了堆排序在优先队列中的应用,包括最大优先队列和最小优先队列的实现原理、算法步骤以及性能分析。通过掌握堆排序在优先队列中的应用,我们可以更好地理解和应用这两种数据结构,提高程序的性能和效率。
未来,随着计算机技术的不断发展,优先队列和堆排序的应用场景将越来越广泛。我们可以进一步探索和研究如何优化堆排序算法,提高其在处理大规模数据时的性能表现。同时,我们也可以将堆排序与其他数据结构和算法
![[STL]<span style='color:red;'>优先级</span><span style='color:red;'>队</span><span style='color:red;'>列</span><span style='color:red;'>的</span>模拟实现(<span style='color:red;'>堆</span>)](https://img-blog.csdnimg.cn/direct/b1c774ffc5524b53ba252e73f6e53155.png)

























![[蓝桥杯 2022 省 A] 求和](https://img-blog.csdnimg.cn/direct/0aebe81402c24df38fa58b8c24bb3e8b.png)