Stochastic Gradient Descent
The purpose of this notebook is to practice implementing the stochastic gradient descent (SGD) optimisation algorithm from scratch.
import numpy as np
import matplotlib.pyplot as plt
# Imports used for testing.
import numpy.testing as npt
We consider a linear regression problem of the form
y = β 0 + x β 1 + ϵ , ϵ ∼ N ( 0 , σ 2 ) y = \beta_0 + x \beta_1 + \epsilon\,,\quad \epsilon \sim \mathcal N(0, \sigma^2) y=β0+xβ1+ϵ,ϵ∼N(0,σ2)
where x ∈ R x\in\mathbb{R} x∈R are inputs and y ∈ R y\in\mathbb{R} y∈R are noisy observations. The bias β 0 ∈ R \beta_0\in\mathbb{R} β0∈R and coefficient β 1 ∈ R \beta_1\in\mathbb{R} β1∈R parametrize the function.
In this tutorial, we assume that we are able to sample data inputs and outputs ( x n , y n ) (\boldsymbol x_n, y_n) (xn,yn), n = 1 , … , K n=1,\ldots, K n=1,…,K, and we are interested in finding parameters β 0 \beta_0 β0 and β 1 \beta_1 β1 that map the inputs well to the ouputs.
From our lectures, we know that the parameters β 0 \beta_0 β0 and β 1 \beta_1 β1 can be calculated analytically. However, here we are interested in computing a numerical solution using the stochastic gradient descent algorithm (SGD).
We will start by setting up a generator of synthetic data inputs and outputs, see: https://realpython.com/introduction-to-python-generators/.
# define parameters for synthetic data
true_beta0 = 3.7
true_beta1 = -1.8
sigma = 0.5
xlim = [-3, 3]
def data_generator(batch_size, seed=0):
"""Generator function for synthetic data.
Parameters:
batch_size (int): Batch size for generated data
seed (float): Seed for random numbers epsilon
Returns:
x (np.array): Synthetic feature data
y (np.array): Synthetic target data following y=true_beta0 + x^T true_beta + epsilon
"""
# fix seed for random numbers
np.random.seed(seed)
while True:
# generate random input data
x = np.random.uniform(*xlim, (batch_size, 1))
# generate noise
noise = np.random.randn(batch_size, 1) * sigma
# compute noisy targets
y = true_beta0 + x * true_beta1 + noise
yield x, y
# Create generator for batch size 16
train_data = data_generator(batch_size=16)
print(train_data)
<generator object data_generator at 0x7f5599713530>
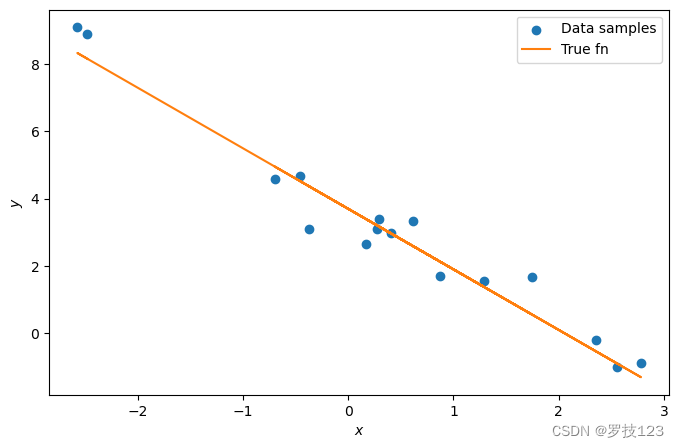
We can visualise the first batch of synthetic data along with the true underlying function.
# Pull a batch of training data
x_sample, y_sample = next(train_data)
# Plot training data along true underlying function
plt.figure(figsize=(8, 5))
plt.scatter(x_sample, y_sample, label='Data samples')
plt.plot(x_sample, true_beta0 + x_sample * true_beta1, color='C1', label='True fn')
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.legend()
plt.show()
The loss that we wish to minimise is the expected mean squared error (MSE) loss computed on the training data:
L ( β 0 , β 1 ) : = E ( x , y ) ∼ p d a t a [ ( y − β 0 − x β 1 ) 2 ] \mathcal{L}(\beta_0, \beta_1) := \mathbb{E}_{(x, y)\sim p_{data}} \left[(y - \beta_0 - x\beta_1)^2\right] L(β0,β1):=E(x,y)∼pdata[(y−β0−xβ1)2]
We first compute the mean squared error loss on a single batch of input and output data.
## EDIT THIS FUNCTION
def mse_loss(x, y, beta0, beta1):
"""Computed expected MSE loss for a single batch.
Parameters:
x (np.array): K x 1 array of inputs
y (np.array): K x 1 array of outputs
beta0 (float): Bias parameter
beta (float): Coefficient
Returns:
MSE (float): computed on this batch of inputs and outputs; K x 1 array
"""
# compute expected MSE loss
loss = np.mean(((y - beta0 - x * beta1)**2)) ## <-- SOLUTION
return loss
To check your implementation you can run this test:
# This line verifies the correctness of the mse_loss implementation
npt.assert_allclose(mse_loss(x_sample,y_sample,1.0,-0.5), 9.311906)
Before we can minimze the MSE loss we need to initialise the parameters β 0 \beta_0 β0 and β 1 \beta_1 β1.
# Initialise the parameters
beta0 = 1.0
beta1 = -0.5
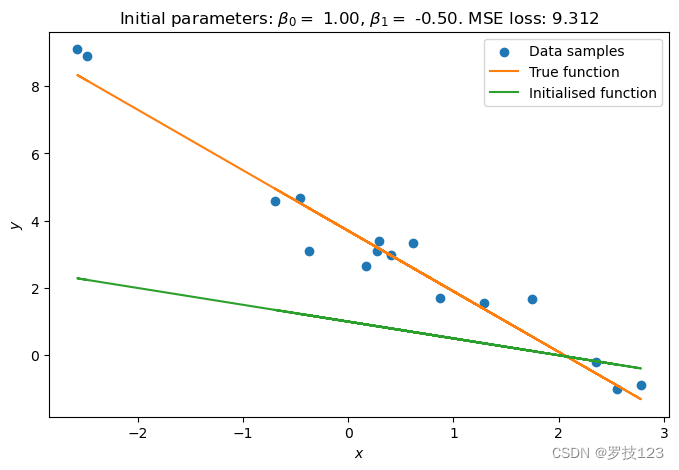
# Plot the initialised regression function
plt.figure(figsize=(8, 5))
plt.scatter(x_sample, y_sample, label='Data samples')
plt.plot(x_sample, true_beta0 + x_sample * true_beta1, color='C1', label='True function')
plt.plot(x_sample, beta0 + x_sample * beta1, color='C2', label='Initialised function')
plt.title(r'Initial parameters: $\beta_0=$ {:.2f}, $\beta_1=$ {:.2f}. MSE loss: {:.3f}'.format(
np.squeeze(beta0), np.squeeze(beta1), mse_loss(x_sample, y_sample, beta0, beta1))
)
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.legend()
plt.show()
Stochastic gradient descent samples a batch of K K K input and output samples, and makes a parameter update by computing the gradient of the loss function
∇ ( β 0 , β 1 ) L ( β 0 ( i ) , β 1 ( i ) ∣ X ( i ) , Y ( i ) ) , \nabla_{(\beta_0, \beta_1)}\mathcal{L}(\beta_0^{(i)}, \beta_1^{(i)} \mid \mathcal{X}^{(i)}, \mathcal{Y}^{(i)}), ∇(β0,β1)L(β0(i),β1(i)∣X(i),Y(i)),
where β 0 ( i ) , β 1 ( i ) \beta_0^{(i)}, \beta_1^{(i)} β0(i),β1(i) are the values of the parameters at the i i i-th iteration of the algorithm, and X ( i ) , Y ( i ) \mathcal{X}^{(i)}, \mathcal{Y}^{(i)} X(i),Y(i) are the i i i-th batch of inputs and outputs.
The following function should compute the gradient of the MSE loss for a given batch of data, and current parameter values.
## EDIT THIS FUNCTION
def mse_grad(x, y, beta0, beta1):
"""Compute gradient of MSE loss w.r.t. beta0 and beta1 averaged over batch.
Parametes:
x (np.array): K x 1 array of inputs
y (np.array): K x 1 array of outputs
beta0 (float): Bias parameter
beta1 (float): Coefficient
Returns:
delta_beta0 (float): Partial derivative w.r.t. beta_0 averaged over batch
delta_beta1 (float): Partial derivative w.r.t. beta_1 averaged over batch
"""
# compute partial derivative w.r.t. beta_0
delta_beta0 = - 2 * np.mean(y - beta0 - x * beta1) ## <-- SOLUTION
# compute partial derivative w.r.t. beta_1
delta_beta1 = - 2 * np.mean((y - beta0 - x * beta1) * x) ## <-- SOLUTION
return delta_beta0, delta_beta1
To check your implementation you can run this cell:
# These lines verify that the derivatives delta_beta0 and delta_beta1 are computed correctled
delta_beta0, delta_beta1 = mse_grad(x_sample, y_sample, 1.0, -0.5)
npt.assert_allclose(delta_beta0, -4.51219)
npt.assert_allclose(delta_beta1, 4.047721)
We have now established all ingredients needed to implement the SGD algorithm for our problem task.
Recall that SGD makes the following parameter update at each iteration:
( β 0 ( i + 1 ) , β 1 ( i + 1 ) ) = ( β 0 ( i ) , β 1 ( i ) ) − η ∇ ( β 0 , β 1 ) L ( β 0 ( i ) , β 1 ( i ) ∣ X ( i ) , Y ( i ) ) , (\beta_0^{(i+1)}, \beta_1^{(i+1)}) = (\beta_0^{(i)}, \beta_1^{(i)}) - \eta \nabla_{(\beta_0, \beta_1)}\mathcal{L}(\beta_0^{(i)}, \beta_1^{(i)} \mid \mathcal{X}^{(i)}, \mathcal{Y}^{(i)}), (β0(i+1),β1(i+1))=(β0(i),β1(i))−η∇(β0,β1)L(β0(i),β1(i)∣X(i),Y(i)),
where η > 0 \eta>0 η>0 is the learning rate.
Implement below a training of the parameters β 0 \beta_0 β0 and β 1 \beta_1 β1 using SGD over 2000 iterations and a learning rate η = 0.001 \eta=0.001 η=0.001.
## EDIT THIS CELL
# parameters for SGD
iterations = 2000
losses = []
learning_rate = 0.001
## SOLUTION
for iteration in range(iterations):
# get a new batch of training data at every iteration
x_batch, y_batch = next(train_data)
# compute MSE loss
losses.append(mse_loss(x_batch, y_batch, beta0, beta1))
# compute gradient
delta_beta0, delta_beta1 = mse_grad(x_batch, y_batch, beta0, beta1)
# update parameters
beta0 -= learning_rate * delta_beta0
beta1 -= learning_rate * delta_beta1
# report results
print('Learned parameters:')
print('beta0 =', np.around(beta0,2), "\nbeta1 =", np.around(beta1,2))
print('\nTrue parameters:')
print('beta0 =', true_beta0, "\nbeta1 =", true_beta1)
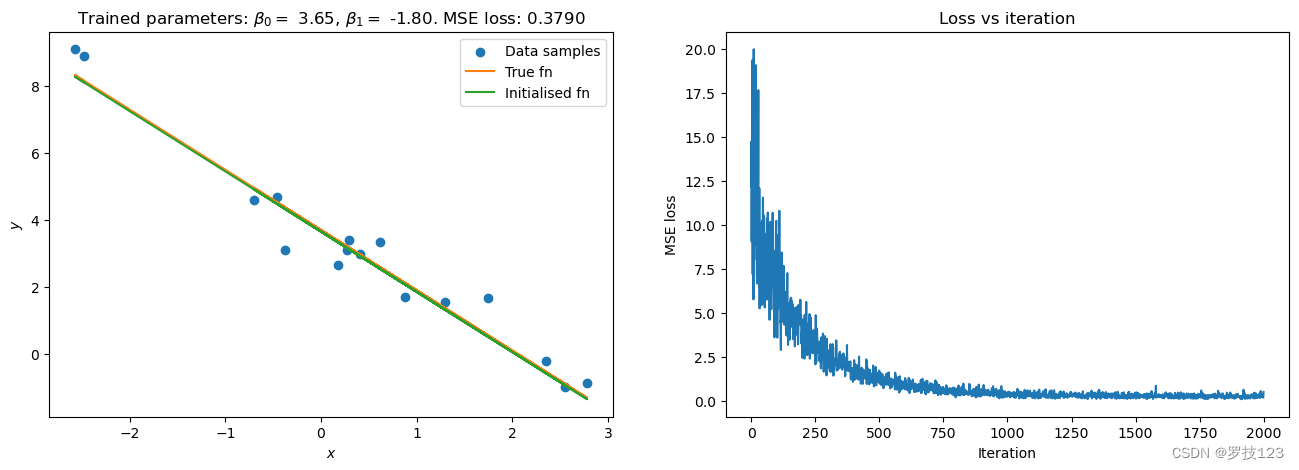
Learned parameters:
beta0 = 3.65
beta1 = -1.8
True parameters:
beta0 = 3.7
beta1 = -1.8
We finally plot the fitted curve and the visualise the training over several iterations.
# Plot the learned regression function and loss values
fig = plt.figure(figsize=(16, 5))
fig.add_subplot(121)
plt.scatter(x_sample, y_sample, label='Data samples')
plt.plot(x_sample, true_beta0 + x_sample * true_beta1, color='C1', label='True fn')
plt.plot(x_sample, beta0 + x_sample * beta1, color='C2', label='Initialised fn')
plt.title(r'Trained parameters: $\beta_0=$ {:.2f}, $\beta_1=$ {:.2f}. MSE loss: {:.4f}'.format(
np.squeeze(beta0), np.squeeze(beta1), mse_loss(x_sample, y_sample, beta0, beta1))
)
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.legend()
fig.add_subplot(122)
plt.plot(losses)
plt.xlabel("Iteration")
plt.ylabel("MSE loss")
plt.title("Loss vs iteration")
plt.show()
Questions
- Does the solution above look reasonable?
- Play around with different values of the learning rate. How is the convergence of the algorithm affected?
- Try using different batch sizes and re-run the algorithm. What changes?