参考资料:python统计分析【托马斯】
在起初,数据的统计分析通常仅限于假设检验:你制定一个假设,收集你的数据,然后接受或拒绝这个假设。由此产生的假设检验构成了迄今为止医学和生命科学中大多数分析的基本框架。
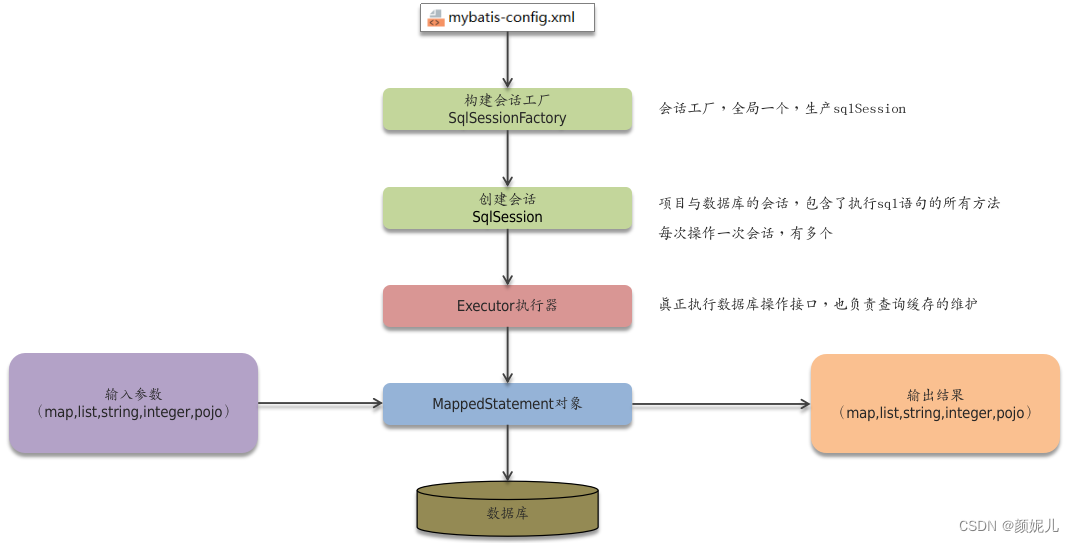
而计算机的出现改变了游戏规则。现在,对统计数据的分析是(或者至少应该是)一个高度交互化的过程:你查看数据,并生成可以解释你数据的模型。然后确定这些模型的最佳拟合参数,并通过查看残差来检查这些模型。如果你对结果不满意,你可以修改模型来改进模型和数据之间的对应关系;当你满意了,就可以计算模型参数的置信区间,并根据这些值形成解释。
无论哪种情况,你都应该从下列步骤开始:
①视觉上检查数据;
②找到极端的样本,并仔细检查它们;
③确定这些值的数据类型;
④如果数据是连续的,检查它们是否是正态分布;
⑤选择并进行合适的检验,或用基于模型的数据分析方法开始分析。
1、数据筛选和离群值
数据分析的第一步是对数据进行目视检查。我们的视觉系统是非常强大的,如果数据被正确地显示,数据特征的趋势可以清晰可见。此外,还要检查第一个和最后一个数据值是否正确读入,并推荐检查缺失值和离群值。
离群值没有一个唯一的定义。然而,对于正态分布的样本,它们通常被定义为数据在离样本均值超过1.5×IQR(四分位距),或两个以上标准偏差之外的数据。离群值常常由下列两种情况中的一种造成的:它们要么是由于记录中的错误造成的,在这种情况下,它们应该被排除在外;要么他们构成了非常重要和有价值的数据点,在这种情况下,它们必须包含在数据分析中。要决定情况属于这两种情况中的哪一种,我们必须检查底层的原始数据(用于饱和或无效的数据值),以及我们的试验计划(可能是在记录过程中发生的错误)。如果检测到潜在的问题,那么只有在这种情况下可以删除分析的异常值。在其他情况下,数据都必须保留!
2、正态性检验
统计假设检验可分为参数检验和非参数检验。参数检验假定数据可以由一个或多个参数定义的分布很好地描述,在大多数情况下是通过正态分布来描述的。对于给定的数据集,需要确定并解释该分布的最佳拟合参数和他们的置信区间。
然而,该方法只在给定的数据集实际上能够被选择的分布近似的时候才能工作正常。如果不是这样的话,参数检验的结果会完全错误。这种情况下,我们就需要采用非参数检验,尽管灵敏度不高,但正因如此,它不依赖数据服从特定的分布。
(1)概率图
在统计学中,有许多工具用于视觉评估分布。存在大量的视觉化的方法来比较两个概率分布,比较二者之间的分位数,或紧密相关的参数。
Q-Q图:Q代表quantile(分位数)。将给定数据集的分位数和参考分布的分位数一起绘制,参考分布通常是正态分布。可参考:excel统计分析——Q-Q图_excel q-q图-CSDN博客
P-P图:将给定数据集的CDF(累计分布函数)和参考分布的CDF一起绘制。可参考:excel统计分析——P-P图-CSDN博客
概率图:绘制了给定数据集的有序数值和参考分布的分位数。
在所有这3种情况下,结果都是类似的:如果进行比较的两个分布式类似的,那么数据点会近似地沿着线y=x分布。如果分布是线性相关的,点近似地沿着一条直线分布,但不一定y=x这条线。
python实现代码如下:
# 导入库
import numpy as np
from scipy import stats
from matplotlib import pyplot as plt
# 建立均值为5,标准差为10的正态分布,并抽取100个随机数
nd_data=stats.norm(5,10).rvs(100)
#绘制概率图
stats.probplot(nd_data,plot=plt)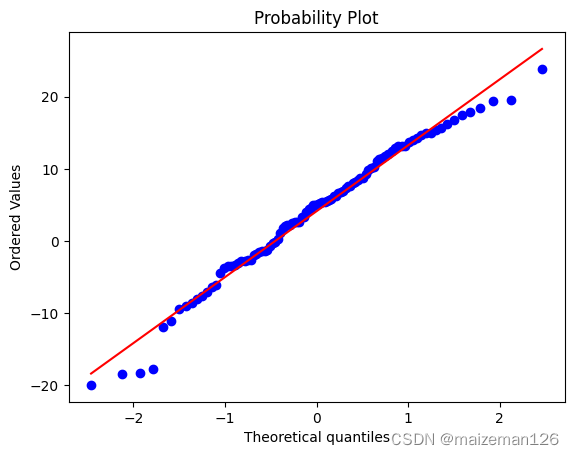
stats.probplot()相关参数解释如下:
①x:为数据源。
②sparams=():理论分布形状参数的设置,如下【注意与上图相比,观察横纵坐标轴的变化】
stats.probplot(nd_data,plot=plt,sparams=(5,10))
③dist='norm',指定理论分布,默认是标准正态分布。
④fit=True,用最小二乘法拟合直线,默认为True,当设置为False时,效果如下:
stats.probplot(nd_data,plot=plt,sparams=(5,10),fit=False)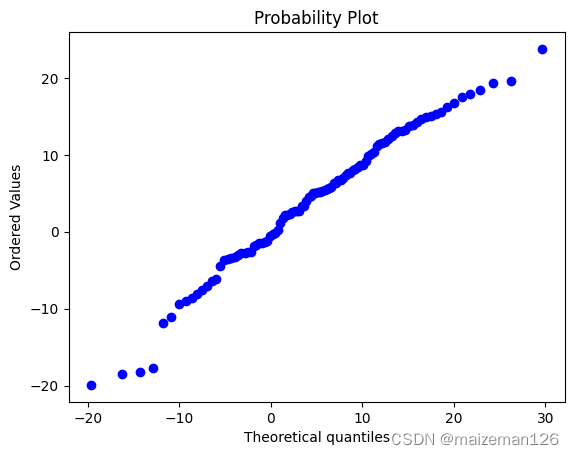
⑤plot=None,指定画布
⑥rvalue=False,是否输出拟合直线的决定系数,当设置为True时,效果如下:
stats.probplot(nd_data,plot=plt,sparams=(5,10),rvalue=True)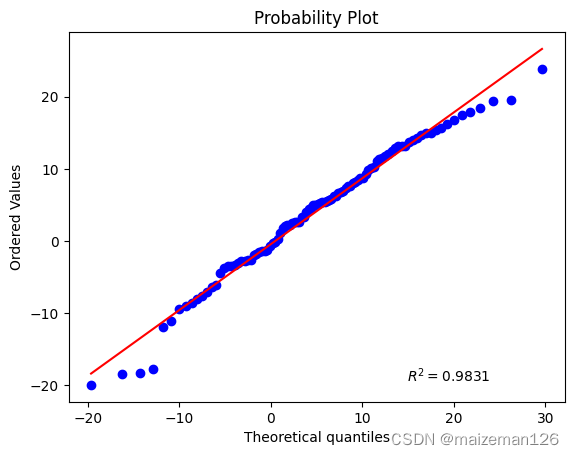
(2)正态性检验
在正态性检验中,会出现不同的挑战:有时候只有很少样本,而其他时候虽然有大量数据,但是有一些极端异常的值。为了应对这些不同的情况,我们需要用不同的正态性检验方法。这些正态性评估的检验整体可分为两类:
①基于和给定分布比较(“最佳拟合”)的检验,常常根据它的CDF来确定。例如:K-S检验、Lilliefors检验、A-D检验、CVM检验、S-W检验等。可参考:
excel统计分析——Lilliefors正态性检验_lilliefors test-CSDN博客
excel统计分析——A-D正态性检验_anderson–darling 或ad检验 excel-CSDN博客
excel统计分析——CVM正态性检验_拟合优度cvm检验-CSDN博客
excel统计分析——K-S正态性检验_k-s检验在excel怎么操作-CSDN博客
excel统计分析——S-W正态性检验_计算w统计量时,n取10,ai取什么值-CSDN博客
②基于样本的描述性统计学检验。如偏度检验、峰度检验、D'Agostino-Pearson omnibus检验或Jarque-Bera检验。可参考:
excel统计分析——偏度、峰度_样本超值峰度-CSDN博客
例如,Lilliefors检验,是基于K-S检验的一个检验,它定量地计算两个样本的经验分布和参考分布的累计分布函数之间的距离,或者是两个样本之间的经验分布函数的距离。
S-W检验,是基于观测值的排序统计量的协方差矩阵的检验,可以被用于小于等于50的样本量下。
python命令stats.normaltest()函数使用的是D'Agostino-Pearson omnibus检验。该检验综合了偏度和峰度检验生成了单一、综合的“omnibus”统计量。
代码操作如下:
import numpy as np
from scipy import stats
nd_data=stats.norm().rvs(1000)
print("p-values for all 1000 data points")
print(stats.normaltest(nd_data))
print("p-values for the first 100 data points")
print(stats.normaltest(nd_data[0:100]))
3、转换
如果数据与正态分布相差很大,有时可以通过转换数据是分布近似正态。例如,数据通常具有只能说正的值,并且又长的拖尾:应用对数变换通常可以使这些数据成这个正态分布。



















![[HGAME 2023 week2]Designer](https://img-blog.csdnimg.cn/direct/a4506526d4f3489fb39b2a3947571c10.png)




![[STM32] 使用 STM32CubeMX 创建 STM32 工程模板](https://img-blog.csdnimg.cn/img_convert/65c9d26b8b5300e5510a513fe7251634.png#pic_center)