文章目录
4.5 VGGNet
4.5.1 模型介绍
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group,VGG)提出的一种深层卷积网络结构,它们以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军(冠军由GoogLeNet以6.65%的错误率夺得)和25.32%的错误率夺得定位任务(Localization)的第一名(GooleNet错误率为26.44%)[5],网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的$3\times3$卷积核的思想是后来许多模型的基础,该模型发表在2015年国际学习表征会议(International Conference On Learning Representations, ICLR)后至今被引用的次数已经超过1万4千余次。
4.5.2 模型结构
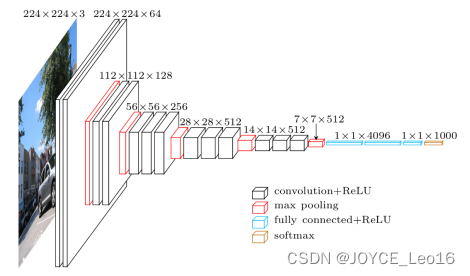
图 4.7 VGG16网络结构图
在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用核尺寸为,相应的VGG16-3表示卷积核尺寸为
),本节介绍的VGG16为VGG16-3。图4.7中的VGG16体现了VGGNet的核心思路,使用
的卷积组合替代大尺寸的卷积(2个
卷积即可与
卷积拥有相同的感受视野),网络参数设置如表4.5所示。
表4.5 VGG16网络参数配置
| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
|---|---|---|---|---|
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 全连接层 |
||||
| 全连接层 |
||||
| 全连接层 |
4.5.3 模型特性
- 整个网络都使用了同样大小的卷积核尺寸
和最大池化尺寸
。
卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
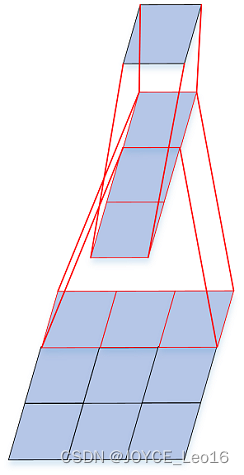
- 两个
的卷积层,感受野大小为
的卷积层。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。
- VGGNet在训练时有一个小技巧,先训练浅层的简单网络VGG11,再复用VGG11的权重来出初始化VGG13,如此反复训练并初始化VGG19.能够使训练时收敛的速度更快。
- 在训练过程中使用多尺度的变换对原始数据做数据增强,使得模型不易过拟合。
4.6 GoogLeNet
4.6.1 模型介绍
GooLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去两届冠军ZFNet和AlexNet都有很大的提升。从名字GoogLeNet可以知道这是来自谷歌工程师所设计的网络结构,而名字中的GoogLeNet更是致敬了LeNet[0]。GoogLeNet中最核心的部分是其内部子网络结构Inception,该结构灵感来源于NIN,至今已经经历了四次版本迭代()。

图 4.8 Inception性能比较图
4.6.2 模型结构
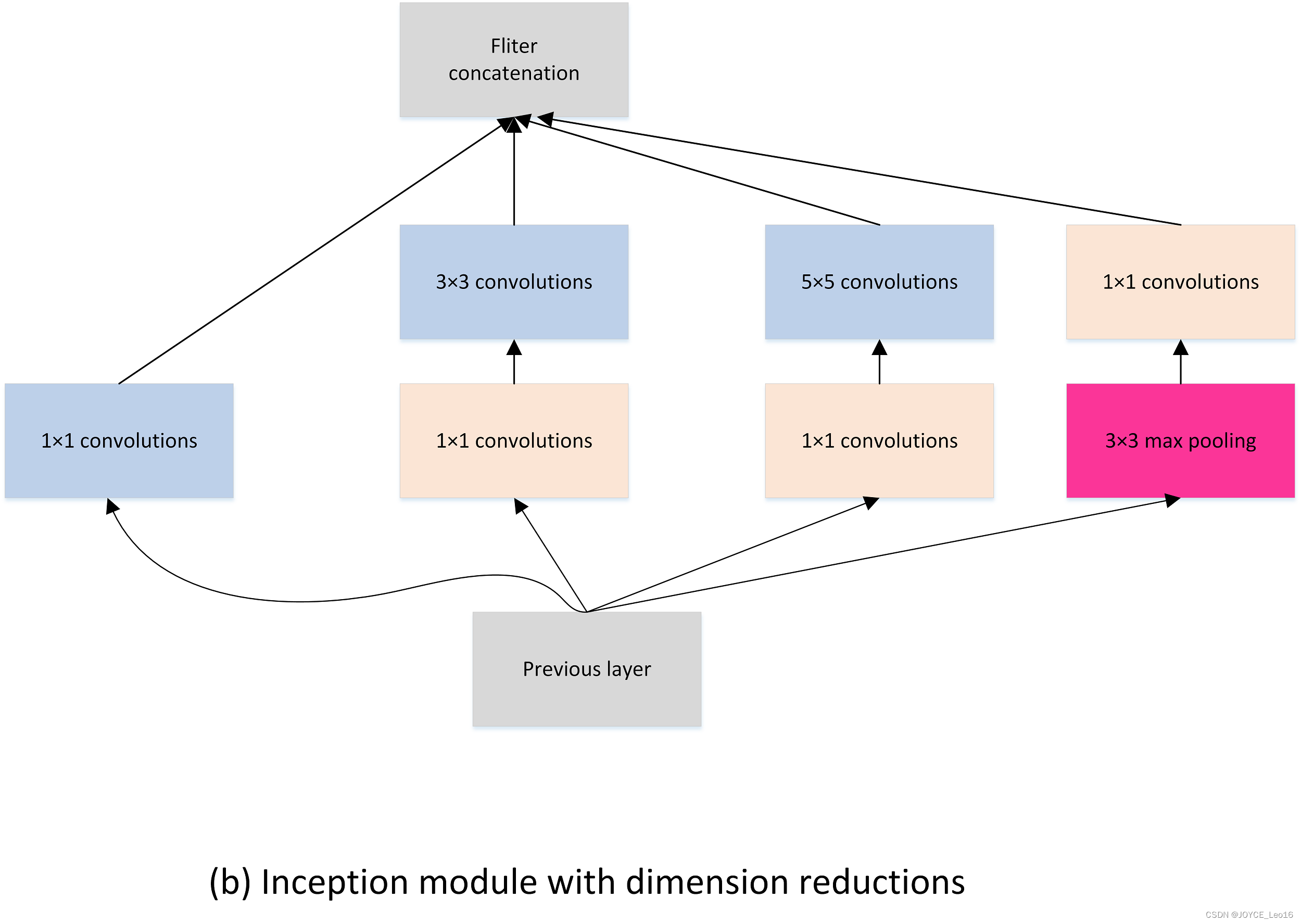
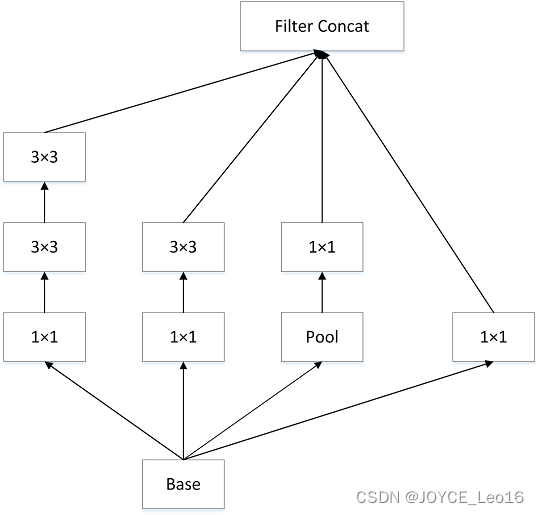
图4.9 GoogLeNet网络结构图如图4.9所示,GoogLeNet相比于以为的卷积神经网络结构,除了在深度上进行了延伸,还对网络的宽度进行了扩展,整个网络由许多块状子网络的堆叠而成,这个子网络构成了Inception结构。图4.9为Inception的四个版本:在同一层中采用不同的卷积核,并对卷积结果进行合并;
组合不同卷积核的堆叠形式,并对卷积结果进行合并;
则在
基础上进行深度组合的尝试;
结构相比于前面的版本更加复杂,子网络中嵌套者子网络。
:
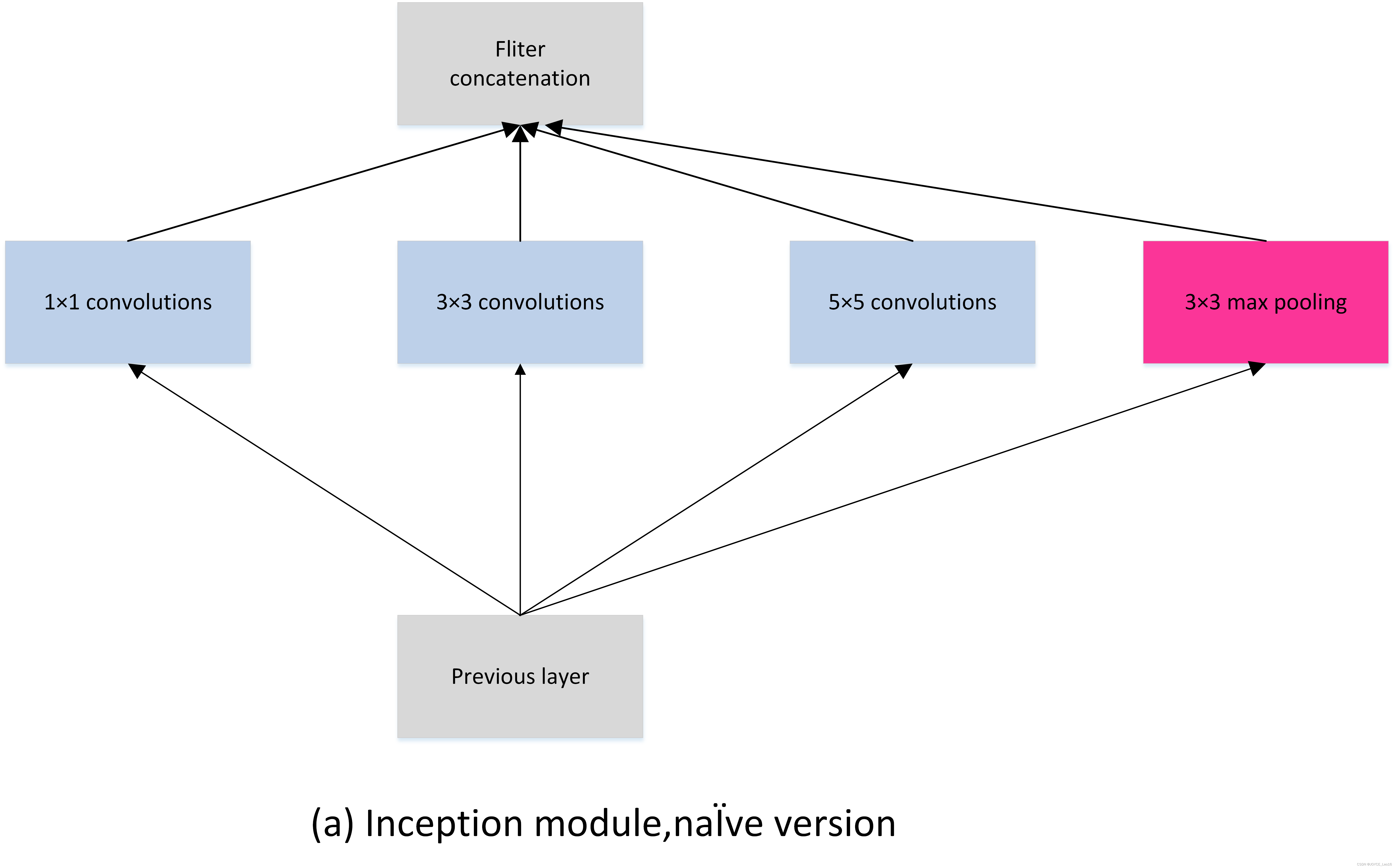
:


:
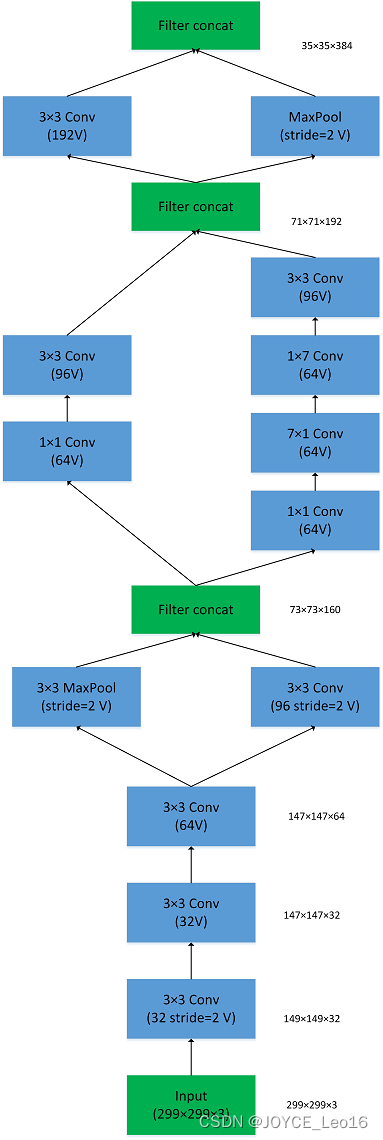

图 4.10 结构图
表 4.6 GoogLeNet中网络参数配置
| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
|---|---|---|---|---|
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 卷积层 |
||||
| 下采样层 |
||||
| 卷积层 |
||||
| 合并层 |
拼接 |
4.6.3 模型特性
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
4.7 为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的
- 评测对比:为了让自己的结果更有说服力,在发表自己成果的时候会同一个标准的baseline及在baseline上改进而进行比较,常见的比如各种检测分割的问题都会基于VGG或者Resnet101这样的基础网络。
- 时间和精力有限:在科研压力和工作压力中,时间和精力只允许大家在有限的范围探索。
- 模型创新难度大:进行基本模型的改进需要大量的实验和尝试,并且需要大量的实验积累和强大灵感,很有可能投入产出比比较小。
- 资源限制:创造一个新的模型需要大量的时间和计算资源,往往在学校和小型商业团队不可行。
- 在实际的应用场景中,其实是有大量的非标准模型的配置。
参考文献
[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
[2] A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 25. Curran Associates, Inc. 1097–1105.
[3] LSVRC-2013. ImageNet Large Scale Visual Recognition Competition 2013 (ILSVRC2013)
[4] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks. European Conference on Computer Vision.
[5] M. Lin, Q. Chen, and S. Yan. Network in network. Computing Research Repository, abs/1312.4400, 2013.
[6] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. International Conference on Machine Learning, 2015.
[7] Bharath Raj. a-simple-guide-to-the-versions-of-the-inception-network, 2018.
[8] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 2016.
[9] Sik-Ho Tsang. review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification, 2018.
[10] Zbigniew Wojna, Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens. Rethinking the Inception Architecture for Computer Vision, 2015.
[11] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Going deeper with convolutions, 2014.