一、本文介绍
本文给大家带来的改进机制是由全新SOTA分割模型(Real-Time Image Segmentation via Hybrid Convolutional-TransformerArchitecture Search)HyCTAS提出的一种SelfAttention注意力机制,论文中叫该机制应用于检测头当中(论文中的分割效果展现目前是最好的)。我将其和我们YOLOv8的检测头集成在一起形成一个自注意力的分割检测头,当然本文的检测头同样适用于Pose和目标检测,本文中均有添加方法,本文内容为我独家创新。
欢迎大家订阅我的专栏一起学习YOLO!

目录
二、基本原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转


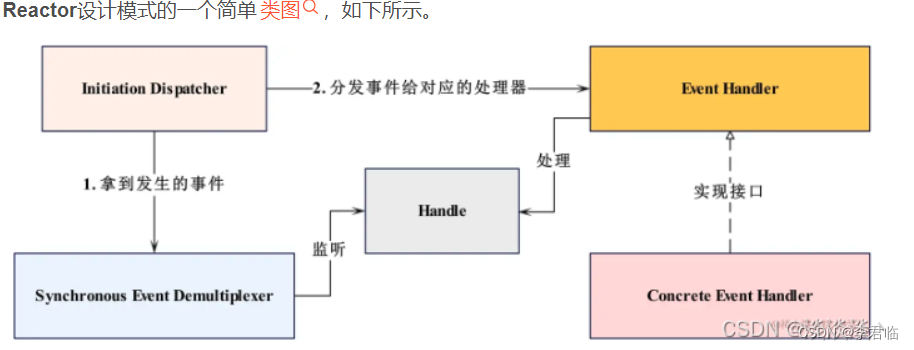
这张图片展示了两种神经网络模块的结构:自注意力模块(Self-Attention Module)和卷积模块(Convolution Module)。这两个模块被设计用于搜索最佳组合,以在保持记忆效率的同时实现特征提取。
自注意力模块包含以下部分:
- 一个1x1的卷积层,用于降低特征维度(c1->c2),减少自注意力的计算负荷。
- 多头自注意力层(MHSA),能够捕获特征间的长距离依赖关系。
- 另一个1x1的卷积层,用于恢复特征维度(c2->c1)。
- 批量归一化层(BN),用于网络训练中的规范化处理。
- 加法操作,将自注意力模块的输出与初始输入相加,形成残差连接。
- ReLu激活函数。
卷积模块包含以下部分:
- 一个降采样步骤,通过0.5倍的降频和3x3的卷积来降低空间分辨率,减少计算量。
- 一个1x1的卷积层,用于特征转换。
- 一个上采样步骤,通过2倍的增频恢复空间分辨率。
- 批量归一化层(BN)。
- 加法操作,将上采样后的输出与降采样之前的输入相加,实现跳跃连接。
- ReLu激活函数。
总结:
图中所示的模块是为了在高分辨率特征提取中寻找高效的结构。自注意力模块旨在捕获更广泛的上下文信息,而卷积模块则专注于保留局部信息和减少计算复杂度。这两种模块的结合旨在通过架构搜索找到一个既能高效提取特征又能保持较低计算成本的最佳网络结构。
三、核心代码
核心代码的使用方式看章节四!
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.tal import dist2bbox, make_anchors
# classes
__all__ = ['Segment_SA', 'Pose_SA', 'Detect_SA']
def dist2rbox(pred_dist, pred_angle, anchor_points, dim=-1):
"""
Decode predicted object bounding box coordinates from anchor points and distribution.
Args:
pred_dist (torch.Tensor): Predicted rotated distance, (bs, h*w, 4).
pred_angle (torch.Tensor): Predicted angle, (bs, h*w, 1).
anchor_points (torch.Tensor): Anchor points, (h*w, 2).
Returns:
(torch.Tensor): Predicted rotated bounding boxes, (bs, h*w, 4).
"""
lt, rb = pred_dist.split(2, dim=dim)
cos, sin = torch.cos(pred_angle), torch.sin(pred_angle)
# (bs, h*w, 1)
xf, yf = ((rb - lt) / 2).split(1, dim=dim)
x, y = xf * cos - yf * sin, xf * sin + yf * cos
xy = torch.cat([x, y], dim=dim) + anchor_points
return torch.cat([xy, lt + rb], dim=dim)
class Proto(nn.Module):
"""YOLOv8 mask Proto module for segmentation models."""
def __init__(self, c1, c_=256, c2=32):
"""
Initializes the YOLOv8 mask Proto module with specified number of protos and masks.
Input arguments are ch_in, number of protos, number of masks.
"""
super().__init__()
self.cv1 = Conv(c1, c_, k=3)
self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True) # nn.Upsample(scale_factor=2, mode='nearest')
self.cv2 = Conv(c_, c_, k=3)
self.cv3 = Conv(c_, c2)
def forward(self, x):
"""Performs a forward pass through layers using an upsampled input image."""
return self.cv3(self.cv2(self.upsample(self.cv1(x))))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
"""
def __init__(self, c1=16):
"""Initialize a convolutional layer with a given number of input channels."""
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
class Self_Attn(nn.Module):
def __init__(
self,
dim,
downsample = False,
activation=nn.ReLU(inplace=True)
):
super().__init__()
dim_out = dim
# shortcut
proj_factor = 1
self.stride = 2 if downsample else 1
if dim != dim_out or downsample:
kernel_size, stride, padding = (3, 2, 1) if downsample else (1, 1, 0)
self.shortcut = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size, stride=stride, padding=padding, bias=False),
nn.BatchNorm2d(dim_out),
activation
)
else:
self.shortcut = nn.Identity()
# contraction and expansion
attn_dim_in = dim_out // proj_factor
# attn_dim_out = heads * dim_head
attn_dim_out = attn_dim_in
self.net = nn.Sequential(
nn.Conv2d(dim, attn_dim_in, 1, bias=False),
nn.BatchNorm2d(attn_dim_in),
activation,
ATT(attn_dim_in),
nn.AvgPool2d((2, 2)) if downsample else nn.Identity(),
nn.BatchNorm2d(attn_dim_out),
activation,
nn.Conv2d(attn_dim_out, dim_out, 1, bias=False),
nn.BatchNorm2d(dim_out)
)
# init last batch norm gamma to zero
nn.init.zeros_(self.net[-1].weight)
# final activation
self.activation = activation
def forward(self, x):
shortcut = self.shortcut(x)
out = F.interpolate(x, size=(int(x.size(2)) // 2, int(x.size(3)) // 2), mode='bilinear', align_corners=True)
out = self.net(out)
if self.stride == 1:
out = F.interpolate(out, size=(int(x.size(2)), int(x.size(3))), mode='bilinear', align_corners=True)
out += shortcut
return self.activation(out)
class ATT(nn.Module):
""" Self attention Layer"""
def __init__(self, in_dim):
super(ATT, self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize, C, width, height = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B X C x (*W*H)
energy = torch.bmm(proj_query, proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # B X C X N
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, width, height)
out = self.gamma * out + x
return out
class Detect_SA(nn.Module):
"""YOLOv8 Detect head for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()):
"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Self_Attn(c2), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Self_Attn(c3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
if self.export and self.format in ('tflite', 'edgetpu'):
# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:
# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309
# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695
img_h = shape[2] * self.stride[0]
img_w = shape[3] * self.stride[0]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
dbox /= img_size
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
class Segment_SA(Detect_SA):
"""YOLOv8 Segment head for segmentation models."""
def __init__(self, nc=80, nm=32, npr=256, ch=()):
"""Initialize the YOLO model attributes such as the number of masks, prototypes, and the convolution layers."""
super().__init__(nc, ch)
self.nm = nm # number of masks
self.npr = npr # number of protos
self.proto = Proto(ch[0], self.npr, self.nm) # protos
self.detect = Detect_SA.forward
c4 = max(ch[0] // 4, self.nm)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)
def forward(self, x):
"""Return model outputs and mask coefficients if training, otherwise return outputs and mask coefficients."""
p = self.proto(x[0]) # mask protos
bs = p.shape[0] # batch size
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
x = self.detect(self, x)
if self.training:
return x, mc, p
return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
class Pose_SA(Detect_SA):
"""YOLOv8 Pose head for keypoints models."""
def __init__(self, nc=80, kpt_shape=(17, 3), ch=()):
"""Initialize YOLO network with default parameters and Convolutional Layers."""
super().__init__(nc, ch)
self.kpt_shape = kpt_shape # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
self.nk = kpt_shape[0] * kpt_shape[1] # number of keypoints total
self.detect = Detect_SA.forward
c4 = max(ch[0] // 4, self.nk)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nk, 1)) for x in ch)
def forward(self, x):
"""Perform forward pass through YOLO model and return predictions."""
bs = x[0].shape[0] # batch size
kpt = torch.cat([self.cv4[i](x[i]).view(bs, self.nk, -1) for i in range(self.nl)], -1) # (bs, 17*3, h*w)
x = self.detect(self, x)
if self.training:
return x, kpt
pred_kpt = self.kpts_decode(bs, kpt)
return torch.cat([x, pred_kpt], 1) if self.export else (torch.cat([x[0], pred_kpt], 1), (x[1], kpt))
def kpts_decode(self, bs, kpts):
"""Decodes keypoints."""
ndim = self.kpt_shape[1]
if self.export: # required for TFLite export to avoid 'PLACEHOLDER_FOR_GREATER_OP_CODES' bug
y = kpts.view(bs, *self.kpt_shape, -1)
a = (y[:, :, :2] * 2.0 + (self.anchors - 0.5)) * self.strides
if ndim == 3:
a = torch.cat((a, y[:, :, 2:3].sigmoid()), 2)
return a.view(bs, self.nk, -1)
else:
y = kpts.clone()
if ndim == 3:
y[:, 2::3] = y[:, 2::3].sigmoid() # sigmoid (WARNING: inplace .sigmoid_() Apple MPS bug)
y[:, 0::ndim] = (y[:, 0::ndim] * 2.0 + (self.anchors[0] - 0.5)) * self.strides
y[:, 1::ndim] = (y[:, 1::ndim] * 2.0 + (self.anchors[1] - 0.5)) * self.strides
return y
if __name__ == "__main__":
# Generating Sample image
image1 = (1, 64, 32, 32)
image2 = (1, 128, 16, 16)
image3 = (1, 256, 8, 8)
image1 = torch.rand(image1)
image2 = torch.rand(image2)
image3 = torch.rand(image3)
image = [image1, image2, image3]
channel = (64, 128, 256)
# Model
mobilenet_v1 = Detect_SA(nc=80, ch=channel)
out = mobilenet_v1(image)
print(out)
四、手把手教你添加检测头
这个添加方式和之前的变了一下,以后的添加方法都按照这个来了,是为了和群内的文件适配。
本文只介绍Pose关键点检测头的添加方法,分割和检测的检测头修改教程大家可以参考下面的两篇文章,其中添加方法一模一样,只是名字变成了本文的对应检测头而已。
目标检测头教程:YOLOv8改进 | 二次创新篇 | 升级版本Dyhead检测头替换DCNv3 实现完美升级(全网独家首发)
分割检测头教程:YOLOv8改进 | 检测头篇 | 利用DySnakeConv改进检测头专用于分割的检测头(全网独家首发,Seg)
4.1 修改一
关键点检测头的第一步还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可,这里面就集成了三个检测头检测、分割、关键点检测。

4.2 修改二
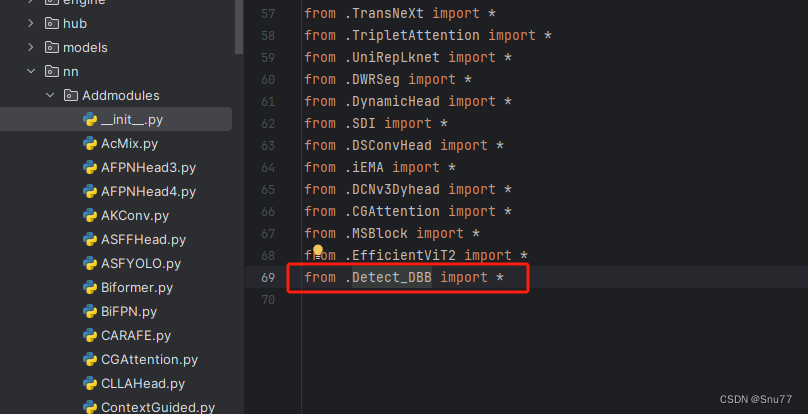
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
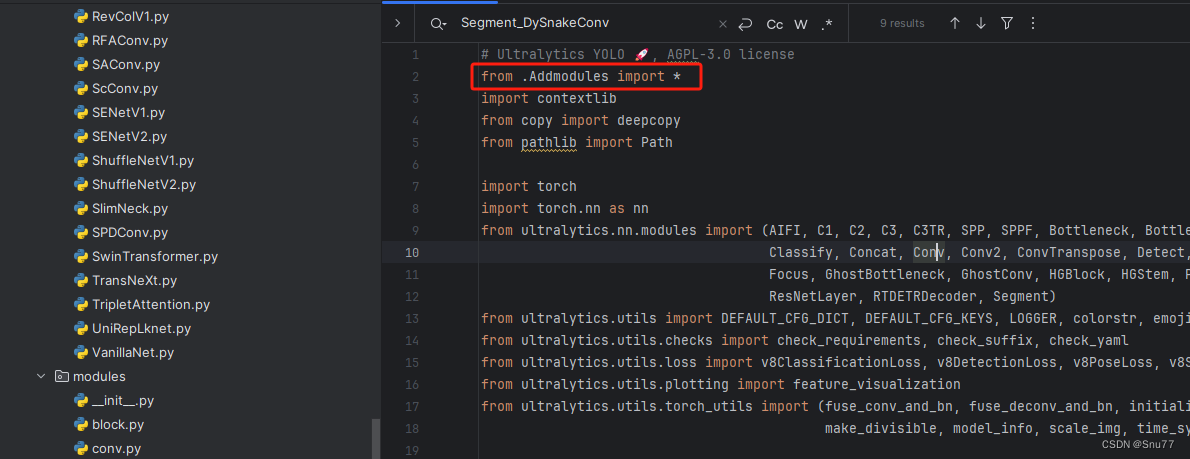
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
4.4 修改四
按照我的进行添加即可,当然其中有些检测头你们的文件中可能没有,无需理会,主要看其周围的代码一直来寻找即可!

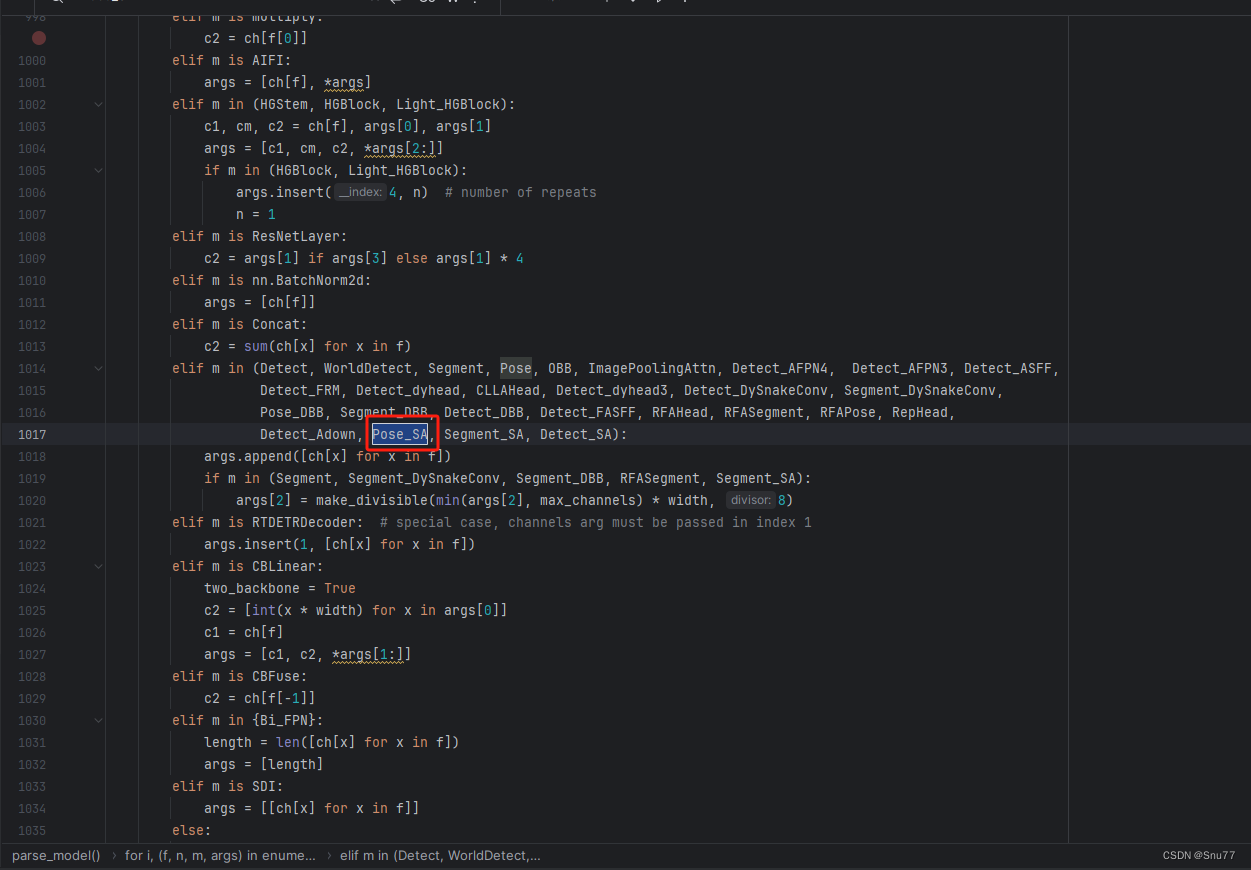
4.5 修改五
按照我下面的添加!
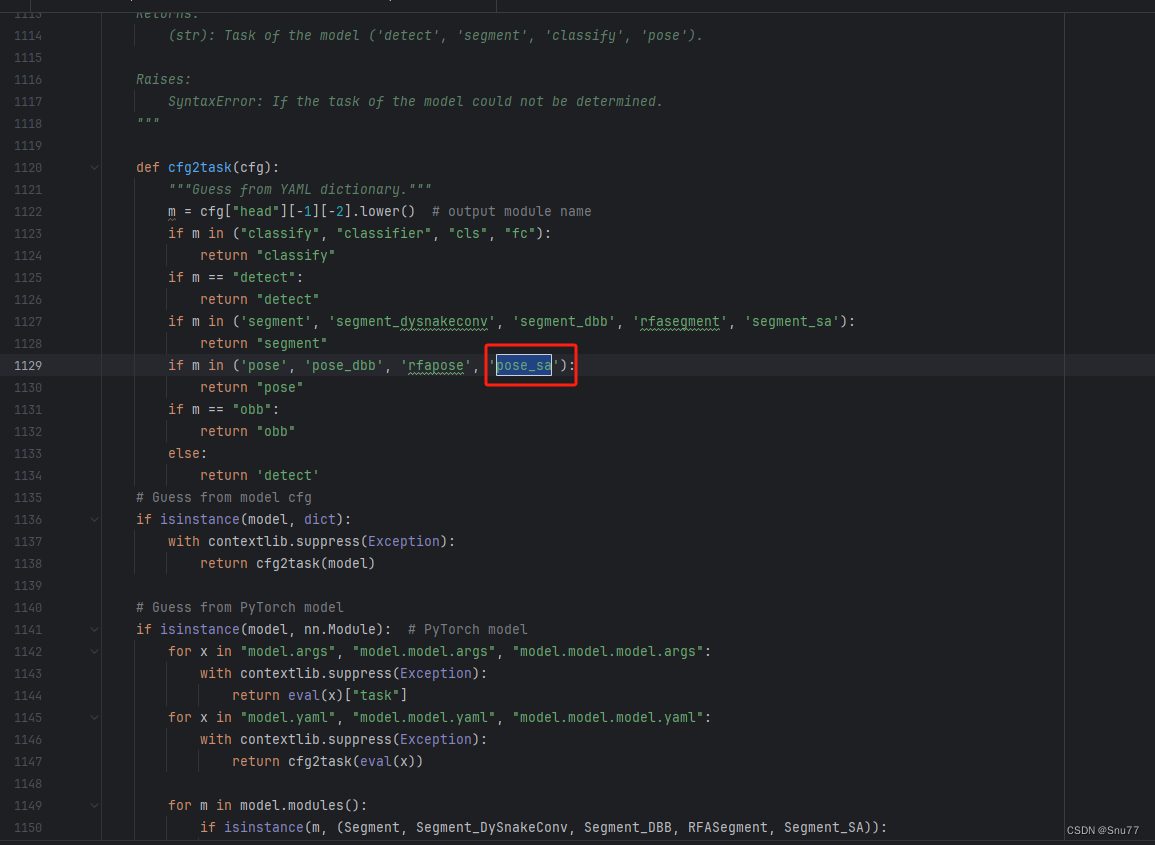
4.6 修改六
此处需要格外注意,因为这里的m系统会穿过的全是小写,比如本文的Pose_OBB,那么你这里需要添加括号的同时还要将Pose_OBB改写成pose_obb。
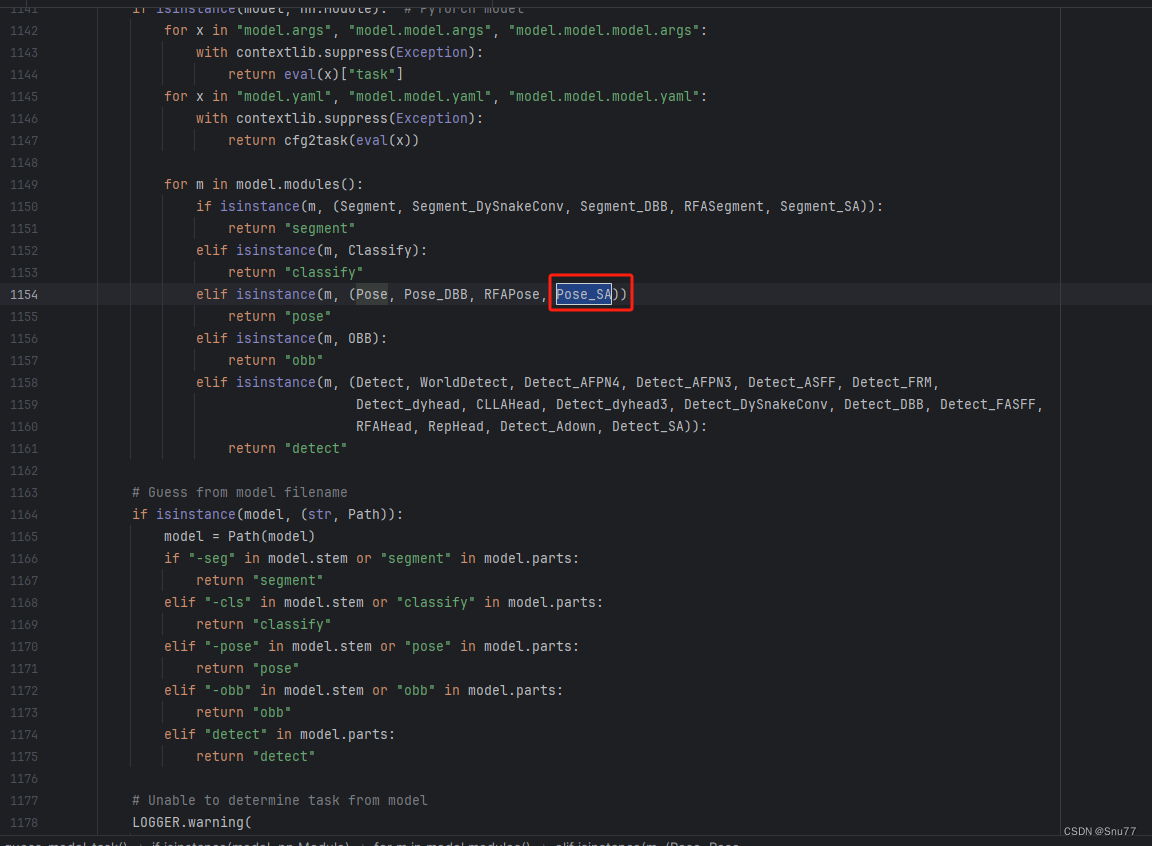
4.7 修改七
此处无需修改大小写直接添加括号之后,添加检测头进去即可。
五、 yaml文件
5.1 关键点检测yaml文件
本文的关键点检测头yaml文件如下(复制yaml文件通过群内的代码或者自己习惯的方式即可运行)->
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-pose keypoints/pose estimation model. For Usage examples see https://docs.ultralytics.com/tasks/pose
# Parameters
nc: 1 # number of classes
kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
scales: # model compound scaling constants, i.e. 'model=yolov8n-pose.yaml' will call yolov8-pose.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Pose_SA, [nc, kpt_shape]] # Pose(P3, P4, P5)
5.2 目标检测yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect_SA, [nc]] # Detect(P3, P4, P5)
5.3 分割的yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Segment_SA, [nc, 32, 256]] # Segment(P3, P4, P5)
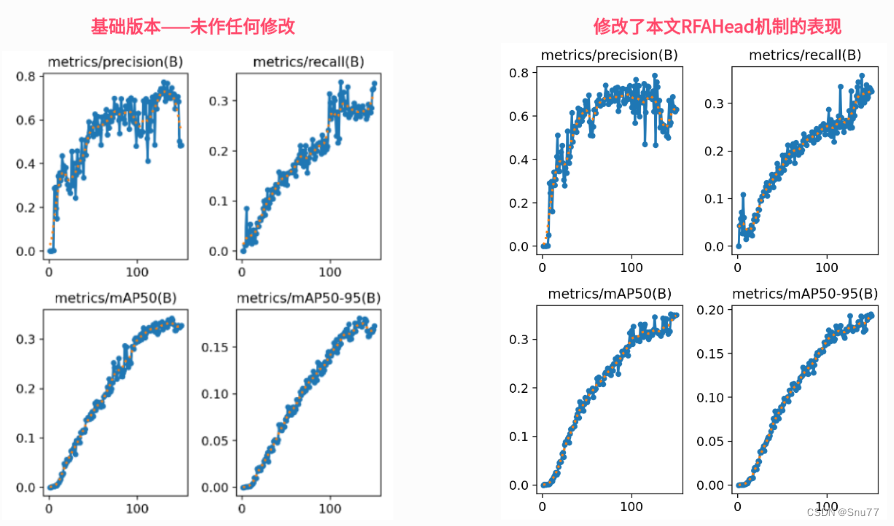
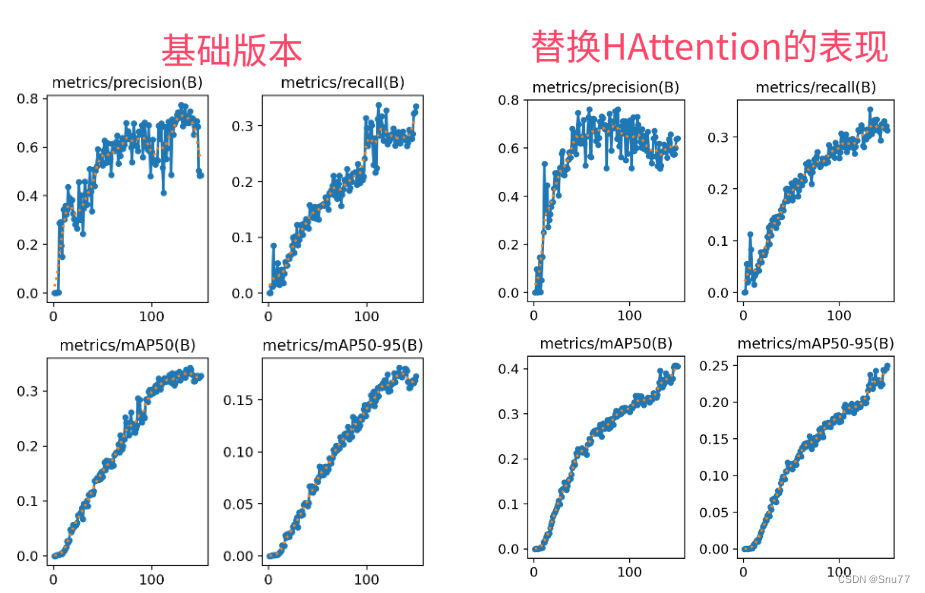
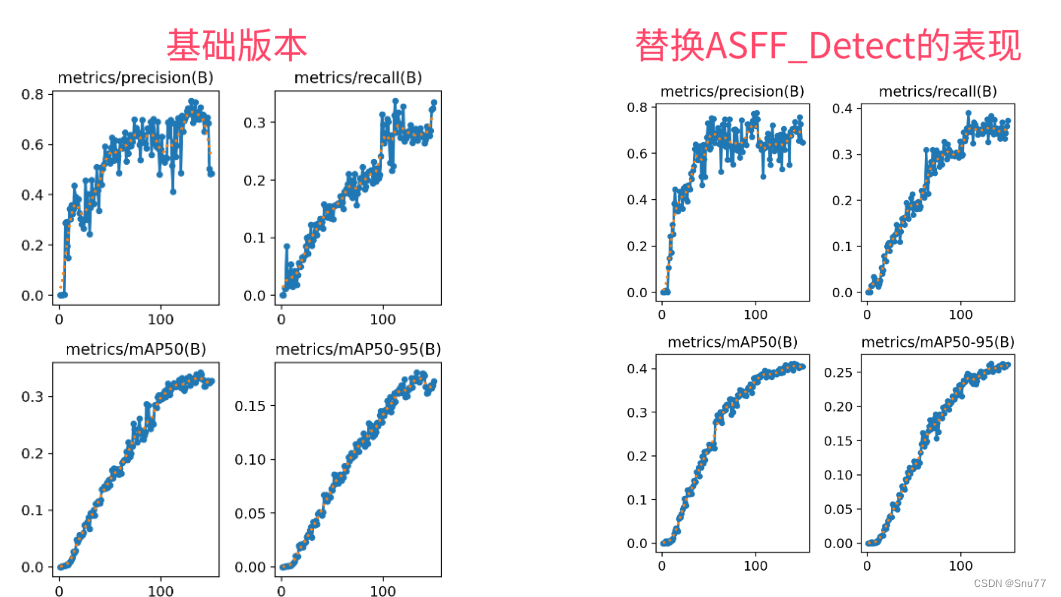
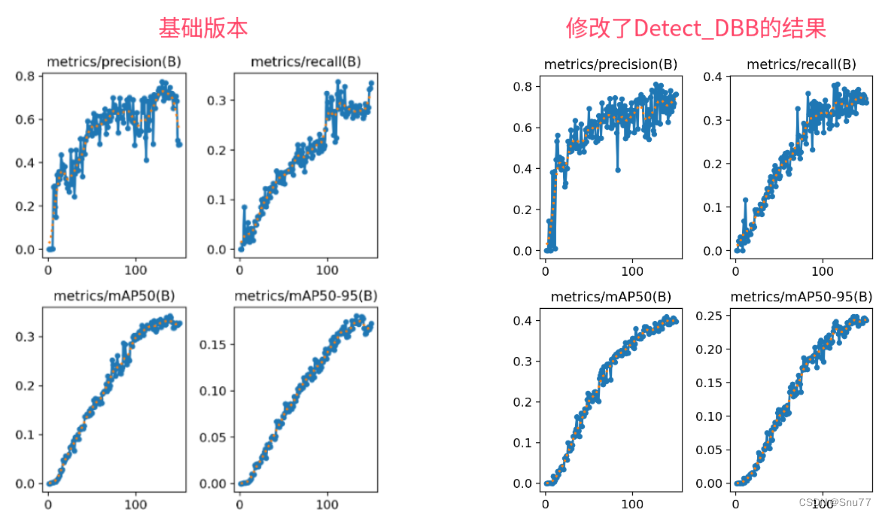
5.4 成功训练截图

六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~