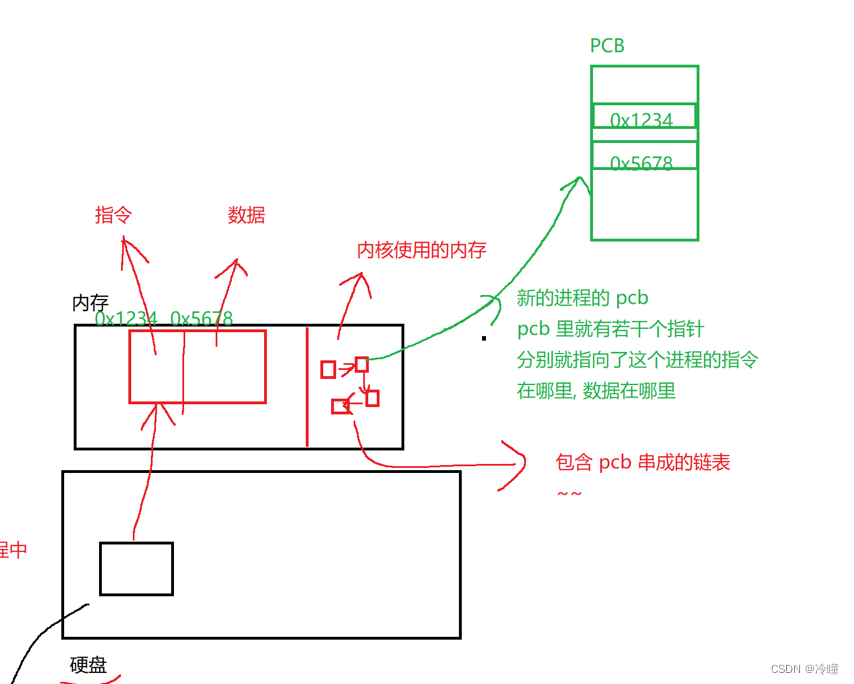
重定向
重定向就是修改对应特定文件描述符数组下标对应的内容
比如改变了2号下标,即标准输出,这样的话对2号下标进行调用就不是输出到显示器了,而是可以通过函数调用来输出到指定的文件中,一般情况下这个文件可以进行内容的输出
dup2函数
dup2() 函数用于复制文件描述符并将其复制到指定的文件描述符号上。
int dup2(int oldfd, int newfd);
- oldfd 参数是待复制的文件描述符。
- newfd 参数是目标文件描述符,即要将 oldfd 复制到的文件描述符号。
dup2() 函数的作用是将 oldfd 复制到 newfd 上,并且如果 newfd 已经打开,则先关闭 newfd。这样就可以将一个文件描述符重定向到另一个文件描述符,常用于文件描述符的重定向,如重定向标准输入、输出等。
例如:
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main() {
int fd = open("file.txt", O_WRONLY | O_CREAT, 0644); // 打开或创建一个文件
int newfd = dup2(fd, STDOUT_FILENO); // 将文件描述符 fd 复制到标准输出文件描述符上
if (newfd == -1) {
perror("dup2"); // 如果出错,打印错误信息
return 1;
}
// 现在标准输出指向了文件 "file.txt",因此下面的内容会写入到文件中
printf("This will be written to the file.\n");
close(fd); // 关闭文件描述符 fd
return 0;
}
在上面的例子中,dup2() 函数将文件描述符 fd 复制到了标准输出文件描述符 STDOUT_FILENO 上,因此 printf() 输出的内容会被重定向到文件 “file.txt” 中。
重定向符号
在Linux中,有一些符号可以实现重定向功能,使得我们在日常编辑中会更加方便:
- "> "符号:输出重定向,将命令的标准输出重定向到指定的文件,如果文件不存在则创建,如果文件已存在则覆盖原有内容。
示例:
echo "Hello, World!" > output.txt
该命令将字符串 “Hello, World!” 输出到文件 output.txt。
- “>>” 符号:输出追加重定向,将命令的标准输出追加到指定的文件末尾,如果文件不存在则创建。
示例:
echo "Hello, World!" >> output.txt
该命令将字符串 “Hello, World!” 追加输出到文件 output.txt 的末尾。
- “<” 符号:输入重定向,将命令的标准输入从文件中读取内容,而不是从键盘输入。
示例:
wc -l < input.txt
该命令统计文件 input.txt 中的行数,并输出结果。
- “2>” 符号:错误输出重定向,将命令的标准错误输出重定向到指定的文件,如果文件不存在则创建,如果文件已存在则覆盖原有内容。
示例:
command_not_exist 2> error.txt
该命令执行一个不存在的命令,并将错误信息输出到文件 error.txt。
- ‘‘2>>’’ 符号:错误输出追加重定向,将命令的标准错误输出追加到指定的文件末尾,如果文件不存在则创建。
示例:
command_not_exist 2>> error.txt
该命令执行一个不存在的命令,并将错误信息追加输出到文件 error.txt 的末尾。
这些重定向符号可以结合使用,以实现更复杂的重定向操作,例如同时将标准输出和标准错误输出重定向到同一个文件,或者将标准输出和标准错误输出分别重定向到不同的文件等。
缓冲区
什么是缓冲区
缓冲区是指一块内存区域,用于临时存放数据。它通常用于解决数据生产者与数据消费者之间速度不匹配的问题。当数据的产生速度远快于处理速度时,可以将数据暂存到缓冲区中,以便消费者按照自己的速度进行处理;反之亦然。
每一个文件在被打开的时候都会先拷贝到内存中,为这些文件提供一个文件缓冲区,用于对文件的读写操作,这个缓冲区实际上就是一部分内存
缓冲区的作用
- 缓冲区的最大作用是
提高使用者的效率
- 平衡生产者和消费者速度:缓冲区可以作为生产者和消费者之间的中间层,平衡两者之间的速度差异,避免数据丢失或阻塞。
- 提高IO效率:在IO操作中,缓冲区可以减少频繁的IO操作,提高IO效率。通过将数据暂存到内存中的缓冲区,可以减少对磁盘或网络的访问次数,从而提高整体系统性能。
- 减少系统调用次数:缓冲区可以减少系统调用的次数。将数据缓存在内存中,可以减少频繁的系统调用,提高系统的响应速度。
缓冲区的刷新
缓冲区因为能够存储数据,因此有一定的刷新方式
- 无缓冲(立即刷新):在无缓冲模式下,数据会立即刷新到输出设备,没有缓冲区的概念。这意味着每次写入数据后都会立即将其发送到输出设备。
示例:
#include <stdio.h>
int main() {
printf("Hello, ");
fflush(stdout); // 立即刷新缓冲区
printf("World!\n");
return 0;
}
在上述示例中,使用fflush(stdout)函数来立即刷新缓冲区,确保在输出"Hello, "后立即将其发送到终端。
- 行缓冲(行刷新):在行缓冲模式下,数据会在换行符(\n)出现时刷新到输出设备。当遇到换行符时,缓冲区中的数据会一次性地发送到输出设备。
示例:
#include <stdio.h>
int main() {
printf("Hello, "); // 行缓冲,不会立即刷新
printf("World!\n"); // 遇到换行符,刷新缓冲区
return 0;
}
在上述示例中,打印"Hello, "时不会立即刷新缓冲区,而当遇到换行符\n时,缓冲区的数据会被刷新到终端。
- 全缓冲(缓冲区满了,再进行刷新):在全缓冲模式下,数据会在缓冲区被填满时才刷新到输出设备。当缓冲区满了之后,数据会一次性地发送到输出设备。
对于磁盘上的文件,一般都是全缓冲
有一些特殊情况的刷新:
- 强制刷新
- 进程退出的时候,对缓冲区进行刷新
- 一般对于显示器文件,进行行刷新(行缓冲)
缓冲区在数据处理和IO操作中扮演着关键的角色。通过合理使用缓冲区,可以提高系统的性能和效率,平衡生产者与消费者之间的速度差异,从而实现更加高效的数据处理和IO操作。




![[<span style='color:red;'>Linux</span>]基础IO(中)---理解<span style='color:red;'>重</span><span style='color:red;'>定向</span><span style='color:red;'>与</span>系统调用dup2的使用、<span style='color:red;'>缓冲区</span>的意义](https://img-blog.csdnimg.cn/direct/e010a4835f524a27ae3ae0449e047b8a.png)