摘要
本文着眼于深度学习模型在各个领域中的编辑问题,从通用的分类器编辑算法切入,展开介绍针对扩散模型的图像编辑问题和针对大语言模型的知识编辑问题,希望能为读者关于“修改模型的行为”这一话题提供一些启发。
引言
当我们训练好一个深度学习模型后,是否可以按照我们的意愿编辑其行为?一般而言,这件事并不困难:我们只需具体化修改的需求,将其反映为对数据集/任务类型/模型结构的修改,再重新或继续训练模型即可。
然而,随着“基座模型”(Foundational Model)这一概念在文本、视觉等模态的广泛应用,上述流程变得并不现实。一来,训练基座模型所需的计算成本很高,为了每个编辑需求重新训练不具备良好的投入产出比;二来,对基座模型的微调会面临“灾难性遗忘”问题,我们需要在通用能力和编辑需求间做出困难的取舍。
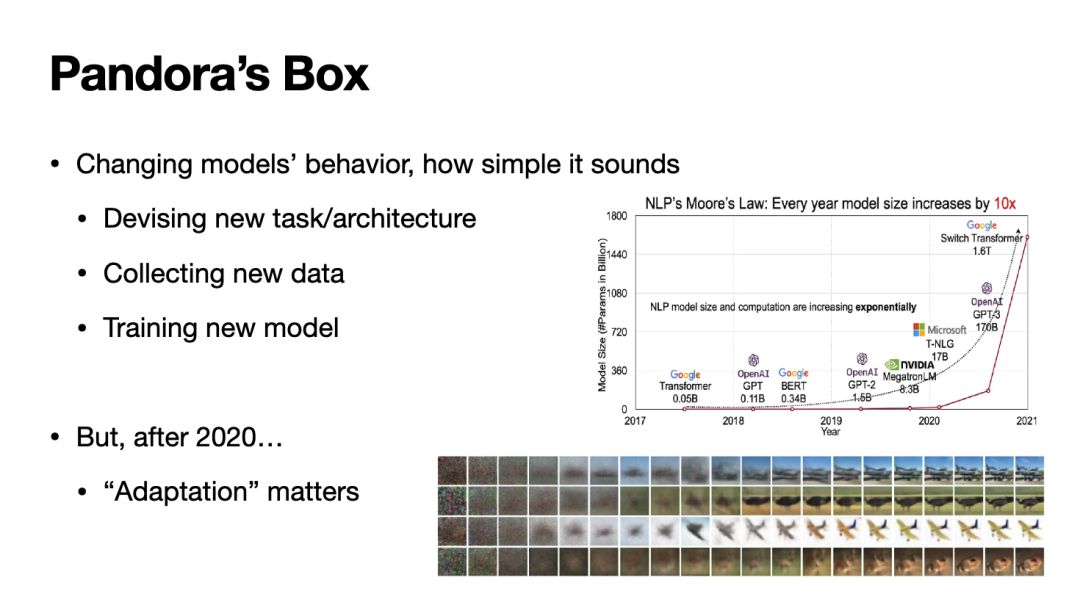
因此,理想的编辑过程应该具有与基座模型适配性强的性质,这一性质既反映在计算开销上(要求较少甚至零额外计算开销),又反映在模型表现上(最小化甚至消除模型针对无关数据的行为变化)。接下来本文将漫谈在不同领域的一些针对“适配性”问题的研究与思考。
编辑一般分类器
一些对模型行为编辑的早期尝试[1]着眼于一般分类模型的编辑。具体而言,[1]将每一条编辑需求表示为一个可被模型计算的损失函数le,并基于此定义了衡量编辑任务的基本指标:1)可靠性(Reliability),即所制定的编辑损失le是否充分小;2)局部性(Locality),即编辑是否对无关数据无影响;3)效率(Efficiency),即编辑所需的计算开销(这里具体化为编辑的反向传播操作执行的次数)是否足够低。

基于这一指标,[1]设计了一套元学习(meta-learning)方法实现模型编辑。具体而言,该工作首先定义一次针对le“编辑操作”为:针对le对模型参数进行一次梯度下降。其次,该工作对模型实施k次编辑操作,得到编辑后的新模型参数,并利用这些参数计算优化目标。
优化目标由三项组成:1)模型原始训练流程的损失函数;2)经过k次编辑操作后的新模型在le上的损失;3)在一个无关数据集合上新模型与原模型分类概率分布的KL-散度。将这三者加权求和就得到了总体优化目标,进而实现模型编辑。值得注意的是,利用重参数化技巧,上述流程可对编辑操作中的步长等超参数同样进行优化,这参考了通用元学习工作的思路。

上述工作在视觉和文本领域的典型分类任务中进行了实验以验证其有效性。不过不难发现,该工作所涉及的编辑过程仍然无法与原始训练过程分离,这让其针对基座模型的“适配性”不佳。因此,我们继续看一看其他具体领域内,针对基座模型的一些编辑方法。
编辑图像生成模型
图像生成中的扩散模型
提到图像生成,就绕不开该领域的基座结构:扩散模型(Diffusion Model),这里我们首先简介一下扩散模型的一些基本背景与原理。
扩散模型受热力学中的分子扩散现象启发,将分子向熵增方向的扩散行为类比到图像中出现随机噪声的现象。基于此,我们可以通过不断的“正向扩散”,即不断向图片添加噪声,得到一系列含噪声程度不同的图片,最终得到一个近似纯随机噪声的图片。而图像的生成过程可被视为“反向扩散”,即给定随机噪声,图像生成模型不断从中去除噪声,最终生成无噪声图片。

如何训练上述去噪模型以实现反向扩散?下图给出了一个示例训练流程。简而言之,通过固定的噪声尺度ai采样T次随机高斯噪声,并让模型对于每次加入噪声后的图片预测所加的噪声(即正向扩散中两个相邻图片的残差),以此作为目标即可训练去噪模型。而图像的生成则更加直观,只需从一个纯随机噪声出发不断运行模型按照适当的噪声尺度去噪,即可生成无噪声的图片。

上述图像去噪模型的结构可以采用早期常用的基于CNN的U-Net,也可利用近期比较热门的Transformer(即DiT)。同时,模型的输入也可以不仅是图片和时序步数编码,还可以包括图片分类器特征(实现Classifier Guidance)、文本编码(实现基于文本指令的图片生成)等。
上述扩散模型使图片生成模型同时具备了不俗的真实性和多样性,因此取得了广泛的研究兴趣。近来,一些公司也推出了基于扩散模型的多模态图像生成基座模型,例如OpenAI的DALL-E 2、Google的Imagen等,它们都通过预训练具有了一定的通用语义理解与图像生成能力。
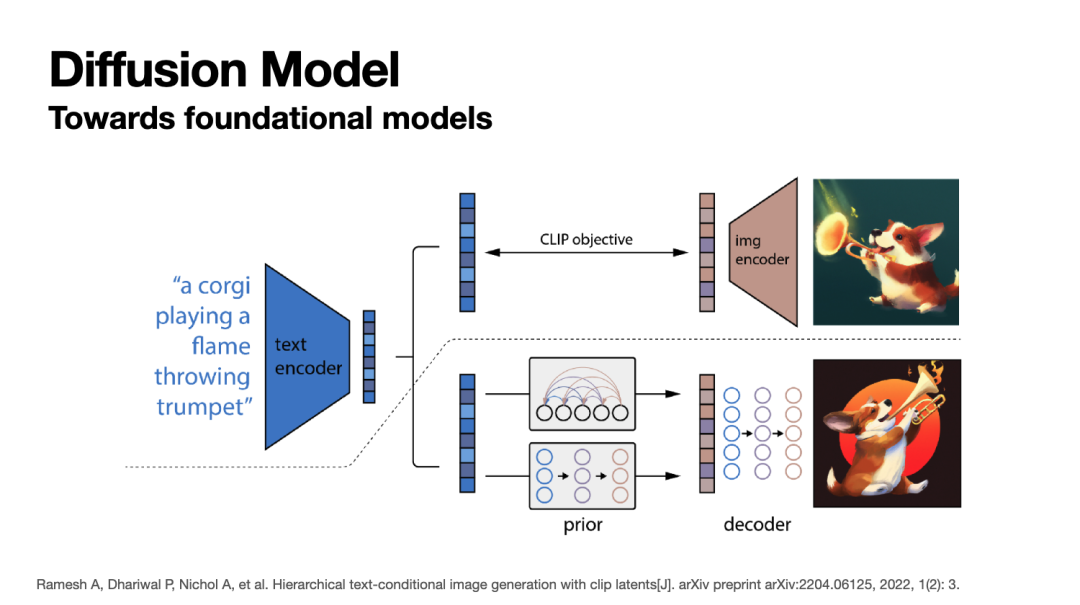
图像生成模型的编辑任务
下图展现了一个典型的图像生成编辑任务:给定一段编辑需求,图像生成模型对原始图像做出修改。值得注意的是,图像生成具有很强的自由度,因此与上述分类模型不同,在编辑图像生成模型时,我们很难定义编辑后的图片具体“应该”是什么样。相反,我们通常只能对编辑后的图片提出判定性要求:1)在语义上实现编辑请求;2)最小化对无关部分的修改。因此对图像生成模型的编辑通常都是严格的zero-shot任务,我们必须利用基座扩散模型通用理解能力实现编辑。下文将介绍两个关于图像生成编辑的相关工作。

通过带mask的扩散过程实现图像编辑
[2]提出了一种即插即用(plug-and-play)、无需模型重训练的图像编辑方法。具体而言,该工作要求一个额外的输入:手动标注图中需要做编辑的区域。有了这一输入,该工作直接应用训练好的扩散模型进行带mask的图像生成。具体而言,每部逆向扩散过程中,扩散模型都只对需要做编辑的区域进行去噪,而图片的其余部分都由原图加入适当尺度的噪声产生;换言之,图像的生成是仅发生在手动标定的mask内的。

总之,这一方法具有对原图无需编辑区域没有影响、无需重训练的优势。但与此同时,它只能在限定区域内编辑图片,且要求的额外人工介入(标注编辑区域),这些不足也许是未来的改进方向。
通过隐向量投影与插值实现图像编辑
[3]提出了一种更通用的图像编辑方法,给定一则自然语言指令,它可以直接对图片做出相应修改。该方法源于下述观察和推理:现在我们有原始图片和编辑指令,希望生成编辑图片;相应的,也应该存在一条原始指令与原始图片对应。假如我们能找到一条原始指令和一个适当的扩散模型,使得该模型可根据原始指令准确地生成原始图片,纳闷我们同样可以用编辑指令通过相同的扩散模型生成编辑图片,进而完成图像编辑任务。

因此,我们只需要获得两部分内容:1)原始指令;2)能根据原始指令准确生成原始图片的扩散模型。显然,直接找到一条自然语言描述原始指令是困难的,因此[3]采取了基于隐向量的方法,固定预训练扩散模型参数不变,只调整文本隐向量使扩散模型输出原始图片(下图A过程)。这一过程相当于得到了原始指令的隐向量。此后,该工作固定原始指令的隐向量不变,只微调扩散模型使之生成原始图片(下图B过程),这相当于找到了我们所需的扩散模型。最后,该工作将原始指令与编辑指令的隐向量内插(interpolate),作为混合语义向量输入给微调后的扩散模型,输出编辑后的图片(下图C过程)。
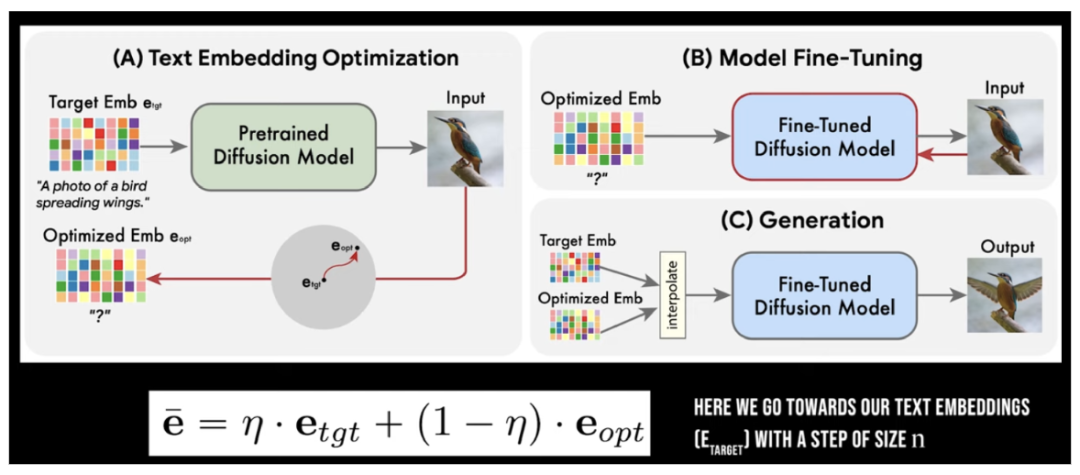
理论上,使用微调后的扩散模型直接基于编辑指令的隐向量即可生成编辑后的图片;而[3]采用进一步内插的原因在于权衡图像对编辑指令的遵循程度(类比于编辑的可靠性)和图像中无关背景的受影响程度(类比于编辑的局部性),他们发现使用内插往往能平衡两个要素,达到较好的综合性能。

编辑大语言模型中的知识
虽然都是针对模型输出结果的编辑,对语言模型的编辑与对图像生成模型的编辑具有截然不同的任务定义,下文将简单谈谈语言模型中的知识编辑任务。具体而言,语言模型中可能存储着一些事实类知识(例如“美国总统是特朗普”),而有些时候我们希望这些知识发生改变(例如随着时间的推移,这条知识应该变为“美国总统是拜登”)。这些改变不仅应发生在关于这条事实的陈述本身,而更应该是发生在语言模型内在的;换言之,只要我们与语言模型交互时某些内在逻辑涉及这条知识的修改,语言模型都应考虑这一编辑以修改其逻辑推理的结果。
语言模型的知识编辑任务
上述愿景催生了语言模型上的知识编辑任务。该任务的每条编辑本质上是一个知识图谱三元组的尾实体发生变化的行为,而在文本上被表示为一则编辑陈述(Edit statement)和一则编辑问题(Edit question)。在指标上,与上文各类编辑类似,该任务衡量三方面指标:1)有效性(Efficacy),语言模型是否能正确回答编辑问题;2)泛化性(Generalizability),语言模型是否能正确回答经过同义改写的编辑问题;3)局部性(Specificity),语言模型对无关事实问题的答案是否保持不变。

哪里存储知识?如何编辑知识?
如何实现语言模型的知识编辑?一些工作尝试直接在编辑陈述上通过微调、参数高效性微调等方式继续训练模型,这些方法虽然有效性优秀,但往往泛化性不佳。这一结果提示我们,基于简单微调的方法或许并没有让语言模型内在地理解知识编辑,而只是记住了一些固定的编辑陈述。因此,我们希望理解语言模型的知识理解机制,并针对性的将知识注入其中。
[4]就是这样的一篇研究。首先它通过因果干预分析基于Transformer Decoder的语言模型存储知识的机制。具体而言,他们首先记录对于一则正确的知识陈述,Transformer不同层数、不同token位置的中间状态向量。其次,他们对部分token对输入embedding假如随机噪声以进行污染,这显然会使语言模型的预测结果偏离正确值。最后,他们依次用之前记录的正确向量恢复各层、各token位置的中间状态向量,观察语言模型的预测结果向正确值的恢复程度。显然,若上述恢复程度显著,则说明只要相应位置的语言模型模块输出正确,语言模型就能准确的应用相应知识。换言之,这一实验分析了Transformer Decoder语言模型中哪些token位置和哪些层对知识的应用起支撑性作用。
上述实验结果如下图左上所示,不难发现有两部分模块对知识应用的影响较大:1)右下角深色区域,即最上层最后几个token的位置,由于知识预测被建模为了“预测下一个token”且上层的模块比下层具有更短的因果链路,这一部分的影响是平凡的。2)左中的深色区域,即中间几层描述主体的最后一个token的区域,这一区域的存在并不显然,[4]将其命名为“early site”。Early site的存在提示我们该区域可能被用于存储知识,而每一层Transformer又由自注意力模块和MLP构成,到底是哪一者实际承担知识的存储呢?该工作进一步拓展了因果干预分析,其细节与上述干预方式类似,本文不再赘述。简单而言,该工作发现early site中的MLP模块对于知识的存储具有重要作用。
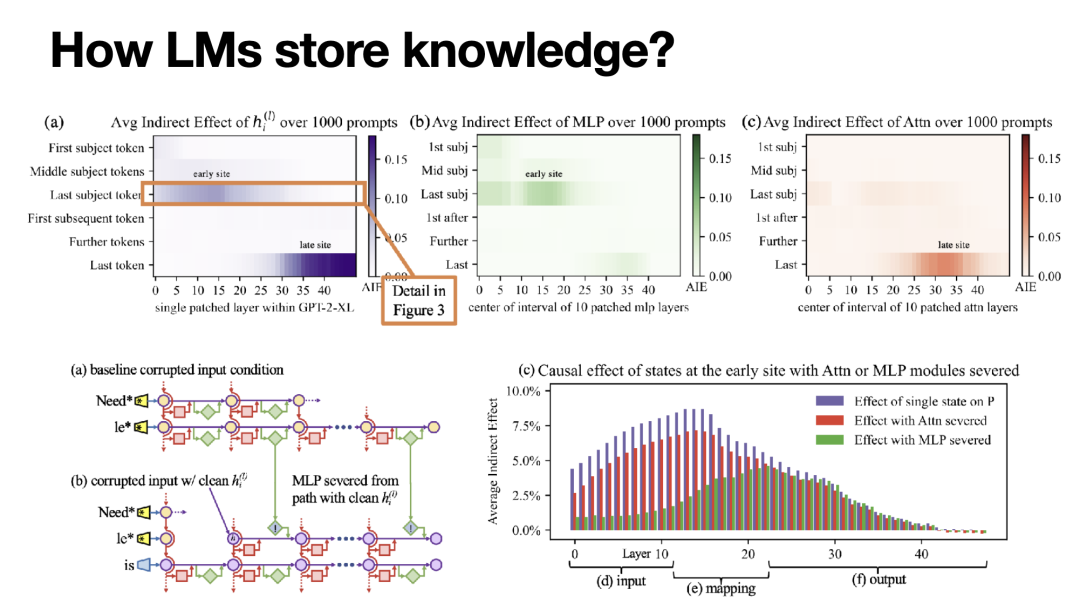
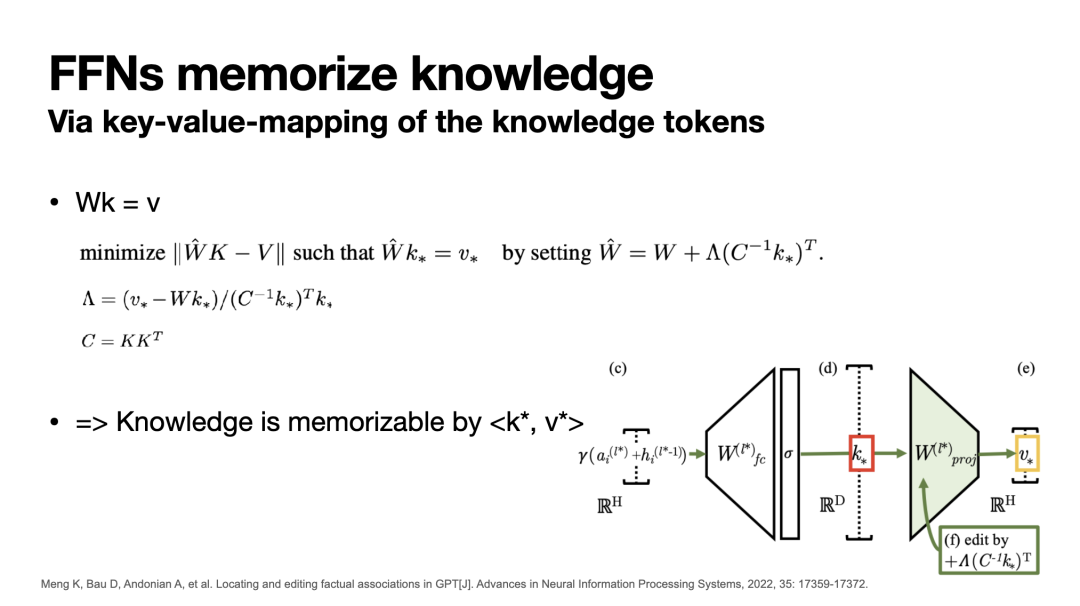
基于这一分析,[4]提出了一种内在的语言模型知识编辑方法:ROME。具体而言,该工作假设MLP模块通过一个联合key-value记忆区存储知识,其中MLP的第一层全连接网络输出关于某一条知识的key向量,第二层全连接网络则将key转换为value,实现知识的召回和应用。因此,第二层全联接网络参数W在形式上满足 W*key = value。
基于此假设,若我们希望插入一条由<k,v>表示的新知识,我们只需更新第二层MLP网络参数W使得W'k=v的前提下,对原先存在的一系列知识<K,V>产生尽可能小的影响,即 min ||W'K-V||。特别的,该工作指出这一约束最优化问题在当前设定下存在闭式解(具体见下图)。因此,我们只需找到新知识对应的<k,v>,并通过闭式解更新W即可完成知识编辑。
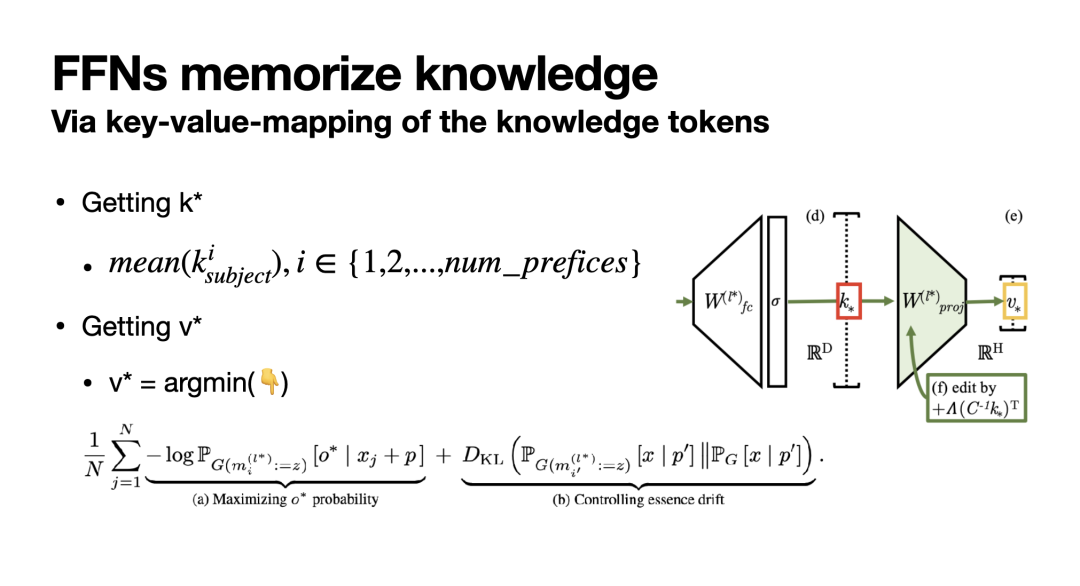
那么如何找到<k,v>呢?简而言之,我们只需通过一些描述新知识的输入,探测需要编辑的模型位置的key和value即可。具体而言,如下图所示,对于k,我们只需对一系列包含主体的prompt中主体的最后一个token处的k向量进行平均即可。对于v,则通过一个优化问题求解:固定语言模型所有参数不变并将v向量的位置(即最后一个主体token处的MLP输出向量)替换为一个可优化的v*向量,并通过梯度下降优化v*使得语言模型针对当前知识陈述能预测出正确的客体、且针对无关知识陈述发生的预测分布偏移最小。这样以来我们就得到了需要编辑的知识所对应的<k,v>,并可通过上文提到的方式实现知识编辑。
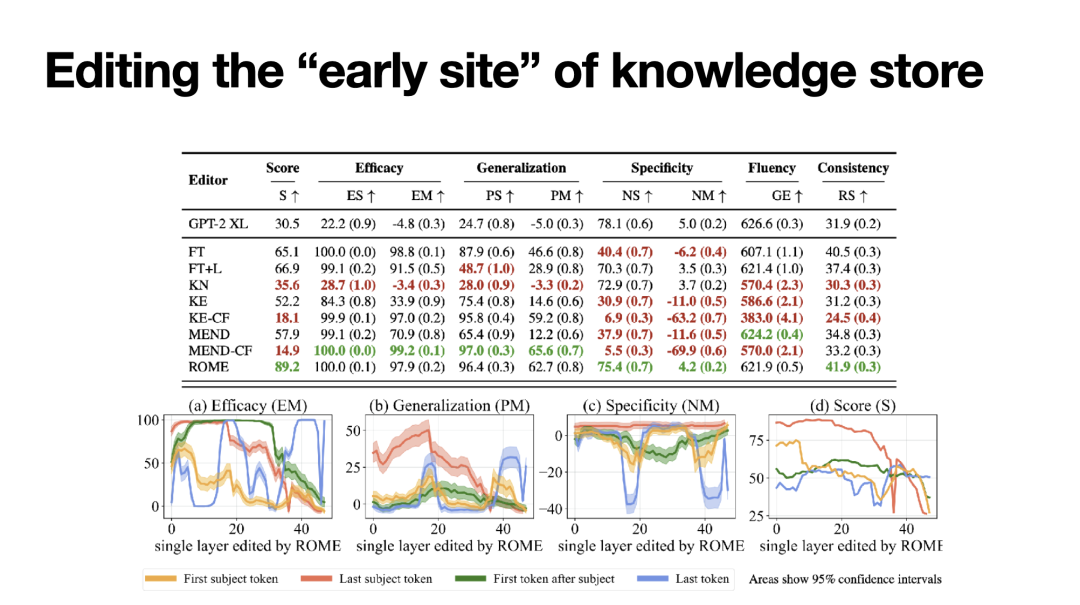
基于上文提出的知识编辑方法,[4]在知识编辑指标COUNTERFACT上进行了实验,展现了相比微调、参数高效性微调、Hyper-Network等方法的优越性,尤其是在泛化性上取得了显著提升。另一个有趣的发现是,作者还分析了在不同层、不同token位置应用上述知识编辑方法的效果,如下图,恰恰也是在early site对应的区域(最后一个主体token、中间层)编辑的各项指标取得了一致最优的效果;这某种程度上或许也印证了语言模型中通过early site存储知识的机制。
知识编辑的下一步
[4]提出的分析与实验并不是语言模型上知识编辑的终点,在此基础上还有许多进一步研究的空间。例如,该工作仍涉及在语言模型计算图上的参数训练,这同样是开销不小的操作;而[5]则在上下文内(in-context)编辑语言模型,避免了训练成本。此外,现有的知识编辑指标都只评估了语言模型对编辑事实本身的理解能力,[6]则提出了一个新指标,评测语言模型在给定一个或多个单跳编辑的前提下,进行准确的多跳问答的能力。通过实验可见,这一指标对现有工作,包括[4],造成了不小的挑战,未来的工作或许可进一步探讨在这一新指标下进行有效知识编辑的方法。
总结
本文围绕深度学习模型的编辑,介绍了针对一般分类器、图像生成模型、语言模型的编辑问题及一些相关方法,还对现有工作的优劣、一些可能的未来研究方向给出了简单的讨论。
参考文献
[1] Sinitsin A, Plokhotnyuk V, Pyrkin D, et al. Editable Neural Networks[C]//International Conference on Learning Representations. 2019.
[2] Lugmayr A, Danelljan M, Romero A, et al. Repaint: Inpainting using denoising diffusion probabilistic models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11461-11471.
[3] Kawar B, Zada S, Lang O, et al. Imagic: Text-based real image editing with diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 6007-6017.
[4] Meng K, Bau D, Andonian A, et al. Locating and editing factual associations in GPT[J]. Advances in Neural Information Processing Systems, 2022, 35: 17359-17372.
[5] Zheng C, Li L, Dong Q, et al. Can We Edit Factual Knowledge by In-Context Learning?[J]. arXiv preprint arXiv:2305.12740, 2023.
[6] Zhong Z, Wu Z, Manning C D, et al. MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions[J]. arXiv preprint arXiv:2305.14795, 2023.




























![[C#]winformYOLO区域检测任意形状区域绘制射线算法实现](https://img-blog.csdnimg.cn/direct/156cdd360787435eb5b95ef38bb5d453.png)