Transformer模型已经成为当前所有自然语言处理NLP的标配,如GPT,Bert,Sora,LLama,Grok等。假如《Attention Is All You Need》类比为爱因斯坦的侠义相对论,Transformer模型则堪称E=MC^2之等量公式。
看过论文之后,我们按照输入输出顺序重新梳理一遍这个模型:
论文中的6层encoder和decoder
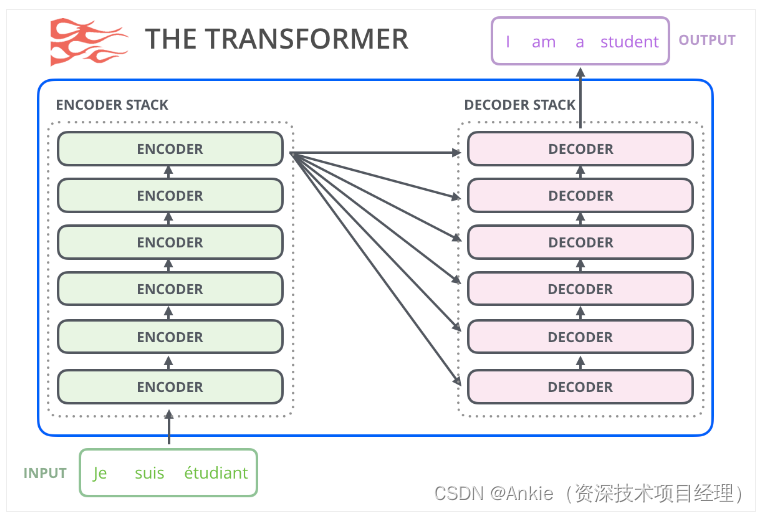
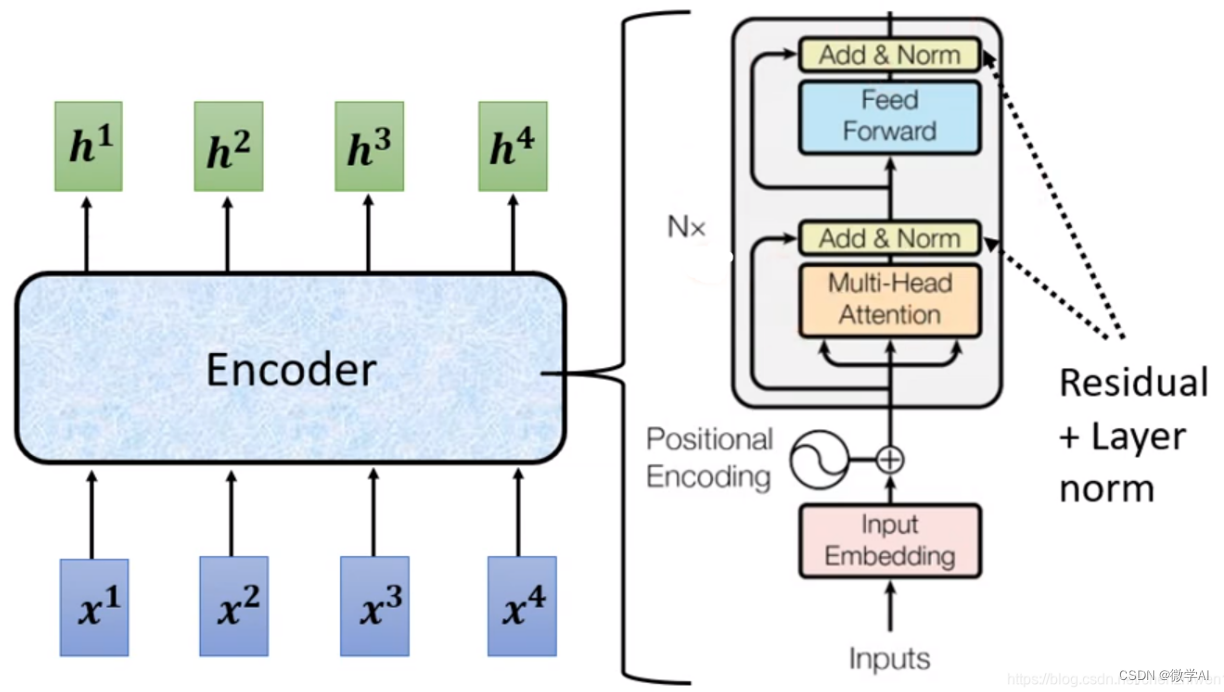
论文中的transformer架构

各个组件简介:
1,Inputs:论文中是为了英德翻译,inputs就是英文
2,input embedding:文本嵌入,将文本中词汇转为张量表示。
3,positional encoding:位置编码器,将位置信息加入到文本嵌入张量。
4,encoder:编码器,提取特征值。论文中有6层,N=6;每个encoder里面有2个子层:
- Multi-Head attention:多头注意机制,这个是transformer的核心,下文细讲
- Feed forward:前馈全连接,担心Multi-Head attention的拟合结果不够,增加全连接网络提高拟合能力。
- 子层连接结构add&norm:
- add:残差连接(跳跃连接),把原来的输入跟输出又并到一起。
- norm:规范化层的主要作用:在一定的网络层数之后,对数值进行规范化,使得特征数值保持在合理的范围内。这样,可以有效地解决参数过大或过小的问题,提高模型的稳定性和收敛速度。
5,outputs(shifted right):论文中是为了英德翻译,outputs就是德文。
6,output embedding:文本嵌入,将文本中词汇转为张量表示。
7,decoder:解码器,使用特征值预测输出。论文中有6层,N=6;decoder里面有3个子层,跟encode大体相同,下面只讲不同的地方
- Masked Multi-Head attention:在encode里面的MHA,因为是训练阶段,所以知道输入的所有信息,计算了所有输入的注意力;而decoder是要预测输出,只能根据已有的输入,不能预知未来。所以需要Masked未知的输出。
- 中间的Multi-Head attention:把encode里的输出K和V(英文)注入到MHA,用来拟合英德翻译。
8,linear:线性层,转化维度。
9,softmax:使最后一维向量缩放到0-1之间。
10,output Proabilities:输出的就是概率。
encoder/decoder动画

GIF图片引用:

![js 用正<span style='color:red;'>则</span>表达式 匹配自定义字符之间<span style='color:red;'>的</span>字符串数据,<span style='color:red;'>如</span>:( )、[ ]、{ }、< >、【】<span style='color:red;'>等</span>括号之间<span style='color:red;'>的</span>字符串数据](https://img-blog.csdnimg.cn/direct/4450994bc8224c729223c8fc3a666100.png)
























![[HackMyVM]靶场 Slowman](https://img-blog.csdnimg.cn/direct/43de8619dd2b466fb3a2dea339f372b2.png)