- Attention is all you need.
- 注意力是你所需要的一切
- Vaswani A, Shazeer N, Parmar N, et al.
- Advances in neural information processing systems, 2017, 30.
文章目录
摘要
- 首先指出,目前主要的序列转导(sequence transduction)模型是含有encoder和decoder的基于复杂的RNN或CNN。性能最好的模型还通过注意力机制连接encoder和decoder。
- 序列转导模型:给定一个序列,生成另外一个序列(如机器翻译:给一句英文,翻译成一句中文)
- 然后提出,本文提出的模型Transformer—完全基于注意力机制,不需要任何递归(RNN)或卷积(CNN)的网络结构。
- 接着通过两个机器翻译的实验,证明了Transformer具有良好的性能,同时具有更高的并行性,并且需要训练的时间显著减少。
- the WMT 2014 Englishto-German translation task、the WMT 2014 English-to-French translation task
- 最后,还证明了Transformer可以很好地推广到其他任务。
1. 引言
- 介绍了序列建模和转导问题中常见的模型:RNN、LSTM、GRU
- 介绍了RNN的原理以及RNN的弊端:
- RNN原理:RNN模型通常会沿着输入和输出序列的符号位置进行计算。将位置与计算的时间步对齐,它们生成一系列隐藏状态 ht,作为先前隐藏状态 ht−1 和位置 t 输入的函数。
- RNN弊端:RNN这种固有的顺序性质阻碍了训练示例中的并行化,这对于处理长序列是非常不利的,因为内存限制限制了示例之间的批处理。
- 介绍了注意力机制的优势
- Attention mechanisms允许对依赖关系建模,而不考虑它们在输入或输出序列中的距离。
- 目前的注意力机制大部分,都是与RNN结合使用。
- 提出,本文的Transformer是一种避免使用RNN,并且完全依赖注意力机制来绘制输入和输出之间的全局依赖关系。
- 再次强调,Transformer能够明显提高模型训练的并行度。
2. 背景
- 介绍了,如何使用CNN来替换RNN,从而减少顺序计算的常见模型:拓展GPU、ByterNet、ConvS2S
- 介绍了,自注意力的原理,以及能够应用于各种任务:阅读理解、抽象概括、文本蕴含、和与学习无关的句子等等
- self-attention:一种将单个序列的不同位置相关联的注意力机制。
- 介绍了端到端记忆网络:是基于注意机制的RNN,而不是序列对齐RNN。
- 强调了Transformer是第一个完全依赖自注意力来计算输入和输出表示,而不是使用序列对齐的RNN或卷积的转换模型。
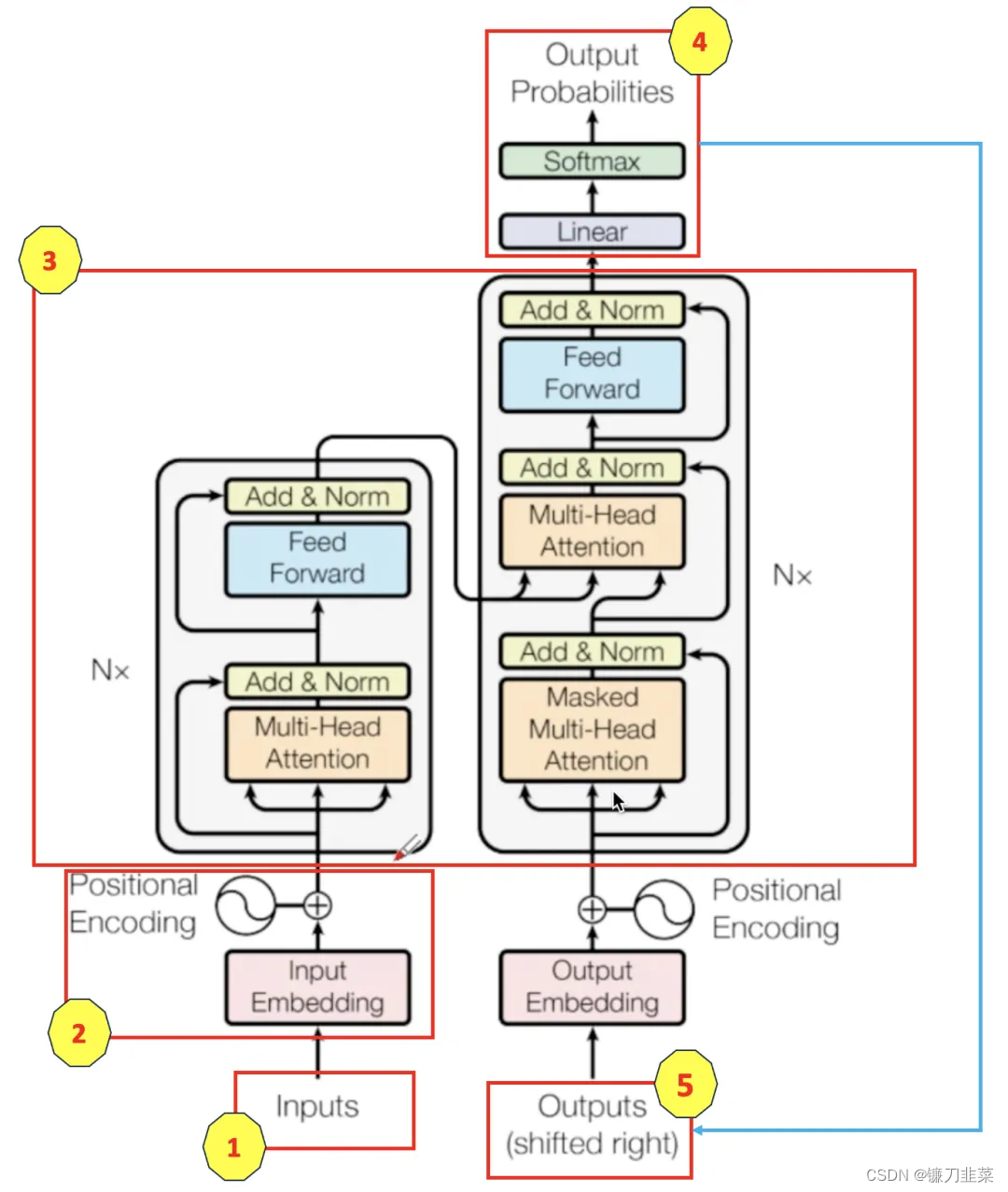
3. 模型结构
Transformer也是像大多数序列转导模型一样,具有encoder-decoder结构, 并且每个步骤模型都是自回归(auto-regressive)的。
- encoder:编码器将输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1,...,xn)映射到连续表示序列 z = ( z 1 , . . . , z n ) z=(z_1, ..., z_n) z=(z1,...,zn)
- decoder:解码器依次生成一个输出序列 ( y 1 , . . . , y m ) (y_1, ..., y_m) (y1,...,ym) (注意:encoder生成的序列长度和decoder输出的序列长度有可能不一样。)
- auto-regressive:在过去时刻的输出作当前时刻的输入。
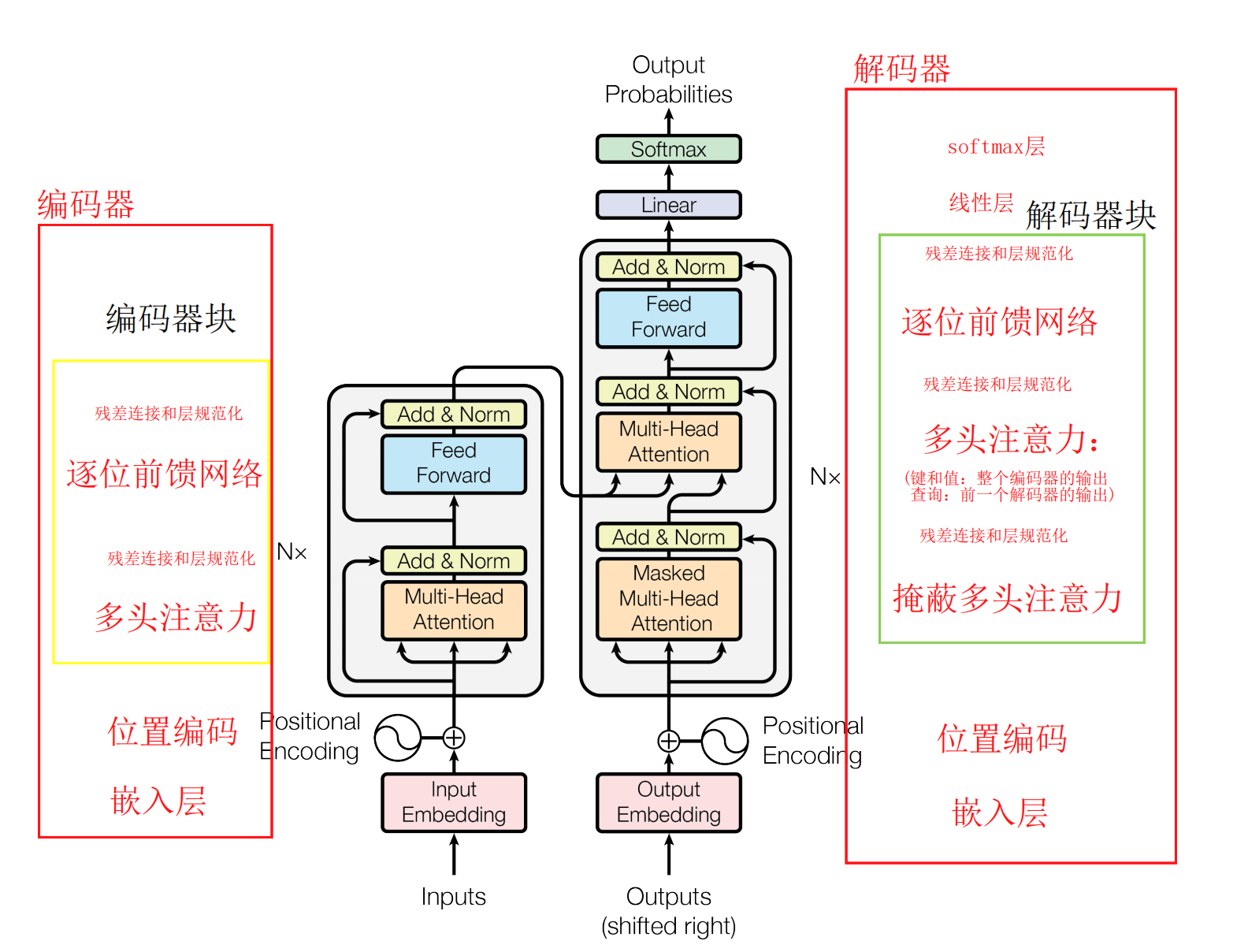
3.1 encoder和decoder块
- encoder:
- 编码器由N=6个相同的编码器块组成。
- 每个编码器块有两个子层:
- 一个是多头自注意力机制,
- 另一个是简单的MLP前馈网络。
- 对每个子层的输出采用残差连接和层归一化: L a y e r N o r m ( x + S u b l a y e r ( ) x ) LayerNorm(x + Sublayer()x) LayerNorm(x+Sublayer()x);
- 为了实现残差连接,所有的子层和嵌入层生成的输出维度相同: d m o d e l = 512 d_{model}=512 dmodel=512
- decoder:
- 解码器也由N=6个相同的解码器块组成。
- 每个编码器块有三个子层:
- 一个带有mask的多头自注意力机制(为了防止注意力机制关注当前位置以后的位置,mask与输出嵌入偏移一个位置相符合,确保位置i的预测只能依赖于小于i位置处的已知输出),
- 一个对编码器块输出执行的多头注意力机制
- 一个简单的MLP前馈网络。
- 对每个子层的输出采用残差连接和层归一化。
- 为什么Transformer使用LayerNorm而不使用BatchNorm?:
- 特征归一化:(特征-均值)/标准差。
- 二维输入(样本n,特征feature ):
- BN:对一个mini-batch内的每一个特征做归一化。
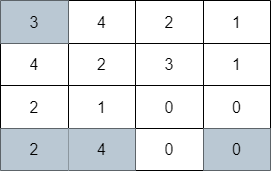
- LN:对每个样本做归一化。![[Pasted image 20240321110549.png|50]]
- 三维输入(有多个序列,每个序列有多个词(长度不一定相同),每个词都是一个向量(特征))
- BN:对一个batch内所有序列的每个特征做归一化。
- LN:对每个序列的做归一化。
- 如果每个序列的长度不一样:
- BN:如果一个batch内的序列长度变化较大时,计算BN的结果抖动就会比较大,并且在预测时,需要先计算之前全部样本均值和标准差,如果将全局的均值和标准差预测一个新的较长的序列(在训练的时候没有遇见过),则之前计算的均值和方差可能会不在那么好用。

- LN:计算每个样本自己的均值和方差,其他的序列长短对当前序列无关。 并且在预测时,也不需要计算全局的均值和标准差,计算结果相对稳定。

3.2 Attention
- 注意力函数是将query和一组key-value对映射到output(输出)的函数,其中query、key、value和output都是向量。
- output实际上是value的加权和,所以(output的维度于value的维度是一样的)其中对每个value的权重是由query和对应的key的相似度计算的。
- (假设有3个key和value,Q1和k1和k1比较相似,则它关于V1和V2的权重就大一些,关于V3的权重就小一点 )

3.2.1 缩放点积注意力(Scaled Dot-Product Attention)
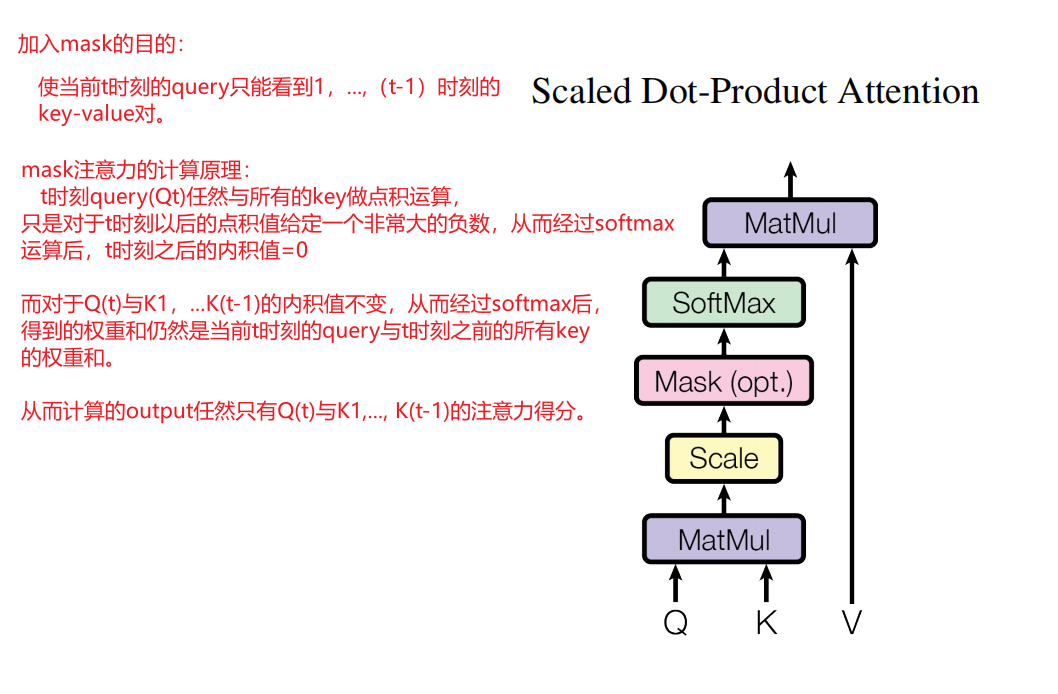
Scaled Dot-Product Attention:输入由query和key(维度都是 d k d_k dk)以及value(维度是 d v d_v dv)组成,计算query与所有的key的点积,在除以 d k \sqrt{d_k} dk,然后应用softmax函数(输出是非负且和为1)来得到value的权重。
(在实际的过程中,同时计算一组query的注意力函数,将其打包到矩阵Q中,key和value也打包到矩阵K和V中)(query和key的个数可能不同,但是query和key的维度一定是一样的)

A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V ( 1 ) Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\ \ \ \ \ (1) Attention(Q,K,V)=softmax(dkQKT)V (1)
- 常见的注意力函数由两种:
- 点积注意力(dot-product): Q和K的维度必须相同,通过计算Q和K的内积(|Q||K|cosθ)来计算Q和K的相似度(如果Q向量和K向量的consθ越大,也就是Q和K的夹角θ越小,表明Q和K的相似度越高;如果内积为0,也即是Q和K正交,没有相似度)
- 加性注意力(additive attention):Q和K的维度不必须相同,
- 为什么使用点积注意力:两者在理论上复杂性相似,但是点积注意力在实践中更快,更节省空间,(因为它可以使用两次矩阵乘法来实现)
- 为什么将点积缩放 1 d k \frac{1}{\sqrt{d_k}} dk1?
- 当 d k d_k dk值较小时,两种机制的表现相似,甚至加性注意力优于点积注意力。
- 解释1:但是对于维度较大的 d k d_k dk,点积的幅度会变大,从而将softmax函数推入梯度较小的区域,为了抵消这种影响,将点积缩放 1 d k \frac{1}{\sqrt{d_k}} dk1
- 解释2:但是 d k d_k dk值很大时(Q和K的向量很长,Transformer默认 d k d_k dk=512),Q和K的点积值就有可能会比较大\小(点积=|Q|·|K|cosθ),等价于Q和K的相对差距较大(点积值会更加像两端靠拢,从而经过softmax后会更加靠近1,剩下的值会更加靠近0)。这样,在计算梯度时,会发现梯度比较小,(因为softmax最后的结果希望预测值置信地方尽量靠近1,不置信的地方尽量靠近0,收敛就饱和了,从而梯度就会变得比较小,训练就会很快收敛),从而导致模型很难更新。
3.2.2 多头注意力机制(Multi-Head Attention)
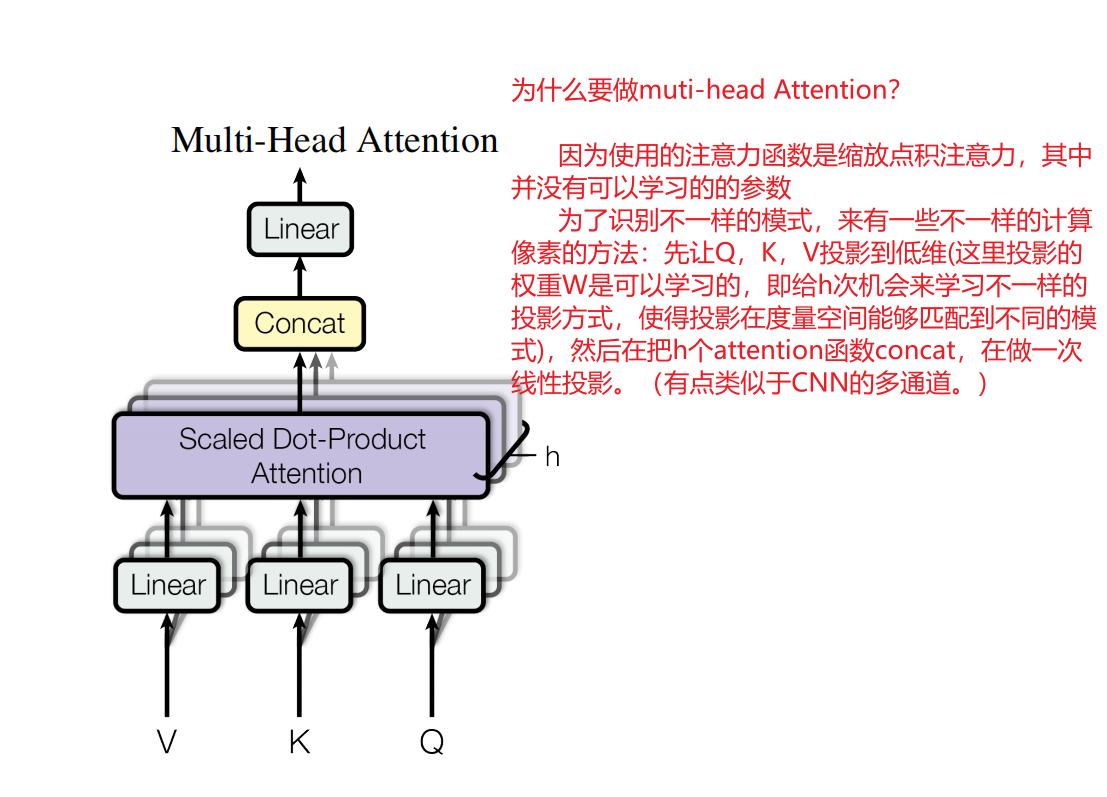
与其对维度为 d m o d e l d_{model} dmodel的Q、K、V做单个的注意力机制,不如先将Q、K、V投影到低维,投影h次,从而执行h次的注意力函数,然后将h个注意力函数的输出concat,在投影回维度 d m o d e l d_model dmodel,从而得到最终的输出。
M u t i H e a d ( Q , K , V ) = c o n c a t ( h e a d 1 , . . . , h e a d h ) W O , 其中 h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \begin{align} MutiHead(Q,K,V) = concat(head_1, ..., head_h)W^O,\\ 其中 head_i = Attention(QW^Q_i, KW^K_i,VW^V_i) \end{align} MutiHead(Q,K,V)=concat(head1,...,headh)WO,其中headi=Attention(QWiQ,KWiK,VWiV)
其中:
- 权重矩阵W: W i Q ∈ R d m o d e l × d k W^Q_i \in R^{d_{model}×d_k} WiQ∈Rdmodel×dk、 W i K ∈ R d m o d e l × d k W^K_i \in R^{d_{model}×d_k} WiK∈Rdmodel×dk、 W i V ∈ R d m o d e l × d v W^V_i \in R^{d_{model}×d_v} WiV∈Rdmodel×dv、 W i O ∈ R h d v × d m o d e l W^O_i \in R^{hd_{v}×d_{model}} WiO∈Rhdv×dmodel
- h=8, d k d_k dk= d v d_v dv= d m o d e l d_{model} dmodel/h = 64
3.2.3 Transformer的attention应用
- encoder-attention
- 编码器中的MSA:query、key、value均来自上一个编码器块的输出。
- 编码器块中的每个位置均能关注到上一个编码器块的所有位置。
- encoder-decoder-attention
- 连接编码器和解码器的MA:query来自上一个解码器块的输出,key-value来自编码器的输入;(不是自注意力)
- Attention允许解码器中的每个位置都关注输入序列中的所有位置。
- decoder-attention
- 解码器中的mask-MSA:query、key、value均来自上一个解码器块的输出。
- mask-MSA允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。
- 通过mask(设置为 −∞)Q与K非法连接相对应的所有内积值( Q K T QK^T QKT),从而使得softmax输出的非法权重为0,来防止解码器中的左向信息流,以保留自回归属性。
3.3 逐位前馈网络(Position-wise Feed-Forward Networks)
逐位前馈网络:对每个位置使用单独且相同的MLP来实现。
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 ( 2 ) FFN(x) =max(0, xW_1+b_1)W_2 + b2 \ \ \ \ \ \ \ (2) FFN(x)=max(0,xW1+b1)W2+b2 (2)
其中:
- x ∈ R 1 × 512 、 W 1 ∈ R 512 × 2048 、 W 2 ∈ R 2048 × 512 x\in R^{1×512}、W_1\in R^{512×2048}、W_2\in R^{2048×512} x∈R1×512、W1∈R512×2048、W2∈R2048×512
- b 1 ∈ R 1 ∗ 2048 、 b 2 ∈ R 1 ∗ 512 b_1\in R^{1*2048}、b_2\in R^{1*512} b1∈R1∗2048、b2∈R1∗512


3.4嵌入层和softmax
- embedding:将编码器的输入token和解码器的输出token,通过学习,映射为一个维度为 d m o d e l d_{model} dmodel的向量。
- 在Transformer中,对于两个embeding层和softmax之前的linear层共享相同的权重矩阵, (目的:训练的时候会简单一点)
- 并且在两个嵌入层中,权重都需要乘以 d k \sqrt{d_k} dk
- 是因为在学习embedding时,每个权重的值会比较小(随着维度的增大,每个权重的值就会变小)
- embedding后要加上position encoding,而位置编码并不会维度增大导致向量值变小
- 所以emebdding的权重矩阵乘以 d k \sqrt{d_k} dk后,保证embddding和position encoding的计算scale相差不大。
3.5 position encoding
- 加入位置编码的目的:
- attention本身没有时序信息:attention的输出就是value的加权和,而权重就是query和key的相似度,与序列信息无关,从而不会关注key-value对在序列中的具体位置(<==>给定一句话,把顺序打乱后,attention的输出值都是一样的)
- 如何在attention中加入时序信息:
- 在attention的输入中加入时序信息,就是把第i个词的位置i加入输入中。
- 具体地,对于embedding输出的向量维度是512,position用一个长为512的向量来表示输出向量的位置信息(使用cos\sin函数,会将位置信息的值在(-1, 1)之间抖动,所以embedding也乘了 d m o d e l \sqrt{d_{model}} dmodel,差不多使得embedding的输出也在(-1, 1)的数值区间里面)
- 因为attention不会受输出序列的顺序影响,所以不管怎样打乱序列的顺序,attention输出的值是不变的,最多是输出序列的顺序发生了相应的变化。
4 为什么要用self-attention

- Complexity per layer(每层的计算复杂度,越低越好)
- Sequential Operations (顺序计算,越少越好)
- 下一步计算必须要等前面多少步计算完成后执行,顺序计算越少,计算并行度越高
- Maximum Path Length(最大路径长度,越短越好)
- 前向和后向信号在网络中必须经过的路径的长度。
- self_attention:
- 计算复杂度------ O ( n 2 ⋅ d ) O(n^2·d) O(n2⋅d):多少个矩阵运算: Q [ n , d ] 与 K [ d , n ] Q[n, d]与K[d, n] Q[n,d]与K[d,n]做矩阵乘法。
- 顺序计算------ O ( 1 ) O(1) O(1):只有矩阵乘法,矩阵里面的乘法运算都是可以并行的。
- 最大路径长度------ O ( 1 ) O(1) O(1):一个query可以与所有的key做运算,输出是所有value的加权和。
- RNN:
- 计算复杂度------ O ( n ⋅ d 2 ) O(n·d^2) O(n⋅d2):当更新循环神经网络的隐状态时,d×d的权重矩阵乘以d维隐状态,计算复杂度为O( d 2 d^2 d2), 由于序列长度为n,所以RNN的时间复杂度为O( n ⋅ d 2 n·d^2 n⋅d2)。
- 顺序计算------ O ( n ) O(n) O(n):n时刻的输出要等前面1,…,n-1时刻的隐状态全部计算完成。
- 最大路径长度------ O ( n ) O(n) O(n):RNN中的输入信息到最后输出,需要走n步完成。
- 所以RNN计算特别长的序列,需要的时间和内存花销很大。
- CNN:
- 计算复杂度------ O ( K ⋅ n ⋅ d 2 ) O(K·n·d^2) O(K⋅n⋅d2):卷积计算序列时,使用一个1d的卷积核大小为[1, k],序列长度为n,输入和输出的通道数是d,所以时间复杂度为 O ( K ⋅ n ⋅ d 2 ) O(K·n·d^2) O(K⋅n⋅d2)
- 顺序计算------ O ( 1 ) O(1) O(1):卷积就是矩阵乘法
- 最大路径长度------ O ( l o g k ( n ) ) O(log_k(n)) O(logk(n)):卷积的感受野需要使用多个k的卷积窗口,来看到最初的不相邻的信息
- self_attention(restricted):
- query只跟最近的r个key-value对做运算,一个长为n的序列就被分成了r的序列。
- 但是,在实际中用attention主要是关心特别长的序列,你真的能够把信息揉的较好一点,所以在实际过程中,self-attention(restricted)用的不是那么多,大家都是用最原始的版本。(如果在语音识别方向 会用到restricted,可以让语音识别变成实时的)
5. 训练
6. 结果
7. 结论
- 论文提出了 Transformer,+这是第一个完全基于注意力的序列转换模型,用多头自注意力取代了编码器-解码器架构中最常用的RNN层。
- 对于翻译任务,Transformer 的训练速度明显快于基于RNN或CNN的架构。在两个翻译任务:the WMT 2014 Englishto-German translation task、the WMT 2014 English-to-French translation task,均实现了SOTA。
- 作者计划将 Transformer 扩展到涉及NLP以外的输入和输出模式的问题。(图像、音频和视频等大型输入和输出)