两年前,在一个名为"超越模仿游戏基准"(BIG-bench)的项目中,450名研究人员汇编了204个旨在测试大型语言模型能力的任务清单,这些模型是像ChatGPT这样的聊天机器人的动力源泉。在大多数任务上,随着模型规模的增加,性能预测地平稳提高——模型越大,性能越好。但在其他任务上,能力的提升并不平滑。性能在一段时间内几乎为零,然后突然跃升。其他研究也发现了类似的能力飞跃。
作者将其描述为“突破性”行为;其他研究人员将其比作物理学中的相变,如液态水冻结成冰。在2022年8月发表的一篇论文中,研究人员指出,这些行为不仅令人惊讶而且不可预测,它们应该成为围绕AI安全、潜力和风险不断演变的对话的一部分。他们将这些能力称为“突现”,这个词描述的是只有当系统达到高度复杂性时才出现的集体行为。
但情况可能并非如此简单。斯坦福大学三位研究人员的一篇新论文认为,这些能力的突然出现只是研究人员衡量LLM性能方式的一个结果。他们认为,这些能力既不是不可预测的,也不是突然的。“这种转变比人们认为的要可预测得多,”斯坦福大学的计算机科学家、论文的资深作者Sanmi Koyejo说。“关于突现的强烈主张,与我们选择的衡量方式有着同样的重要性,这与模型的实际操作有关。”
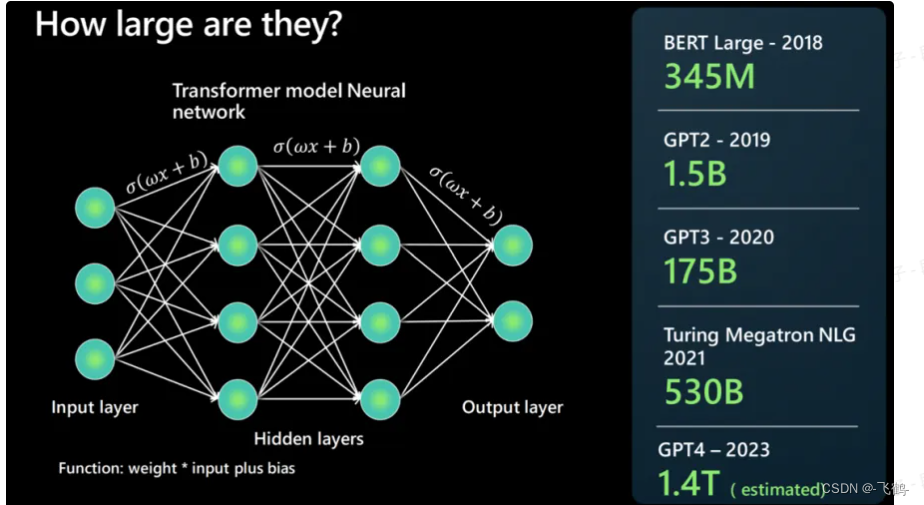
我们只是因为这些模型的规模变得如此之大,现在才开始看到并研究这种行为。大型语言模型通过分析大量的文本数据集——包括来自在线资源的书籍、网络搜索和维基百科的单词——并找出经常一起出现的单词之间的联系来进行训练。大小以参数来衡量,大致类似于所有可以连接的单词的方式。参数越多,LLM可以找到的连接就越多。GPT-2拥有15亿参数,而支持ChatGPT的GPT-3.5使用了3500亿参数。2023年3月推出的GPT-4现在支持Microsoft Copilot,据称使用了1.75万亿参数。
这种快速增长带来了惊人的性能和效率飙升,没有人质疑足够大的LLM可以完成小型模型无法完成的任务,包括那些它们未经训练的任务。斯坦福的三人组将突现视为“幻觉”,承认LLM在规模扩大时变得更有效;事实上,更大模型的增加复杂性应该使其有可能在更困难和更多样化的问题上表现得更好。但他们认为,这种改进看起来是平滑且可预测的还是参差不齐的,是由于度量标准的选择——甚至是测试示例的匮乏——而不是模型的内部工作。
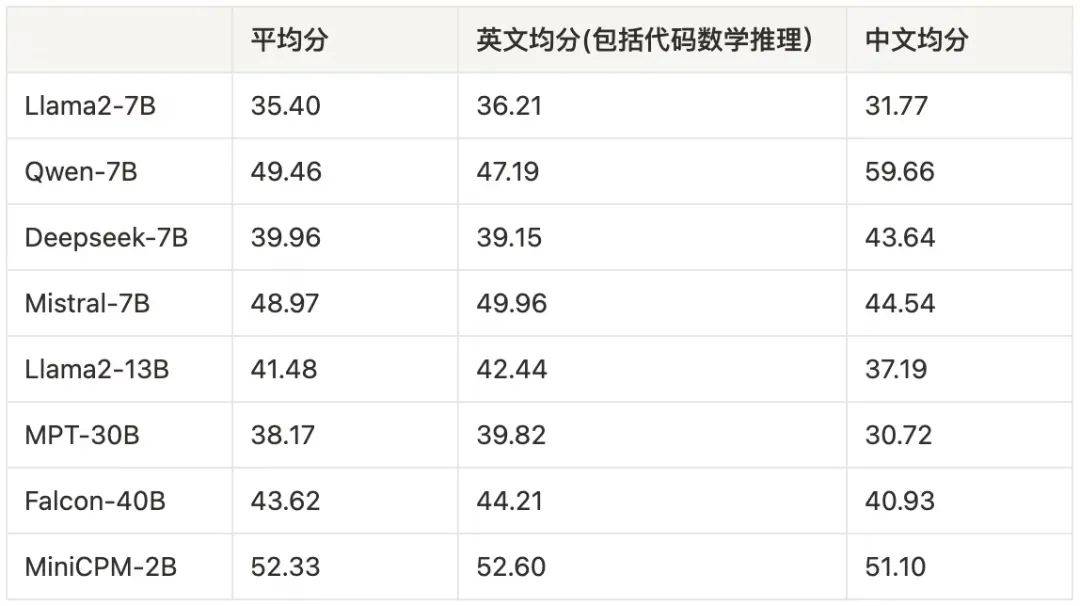
三位数加法提供了一个例子。在2022年的BIG-bench研究中,研究人员报告说,当参数较少时,GPT-3和另一个名为LAMDA的LLM都未能准确完成加法问题。然而,当GPT-3使用130亿参数进行训练时,它的能力就像开关一样改变。突然之间,它能够进行加法运算——LAMDA在680亿参数时也能做到。这表明加法能力在某个阈值处出现。
但斯坦福的研究人员指出,这些LLM只根据准确性来判断:要么它们能够完美地做到,要么就做不到。因此,即使LLM预测了大部分数字正确,它也失败了。这似乎不对。如果你在计算100加278,那么376似乎比-9.34更准确。
因此,Koyejo及其合作者使用一种授予部分学分的度量标准测试了相同的任务。“我们可以问:它预测第一个数字的准确度如何?然后是第二个?然后是第三个?”他说。
Koyejo将这项新工作的想法归功于他的研究生Rylan Schaeffer,他说Rylan注意到LLM的性能似乎会随着其能力的衡量方式而改变。与另一位斯坦福研究生Brando Miranda一起,他们选择了新的度量标准,表明随着参数的增加,LLM在加法问题中预测的数字序列越来越正确。这表明加法能力不是突现的——意味着它经历了一个突然、不可预测的跳跃——而是逐渐和可预测的。他们发现,用不同的度量标准,突现消失了。
但其他科学家指出,这项工作并没有完全消除突现的概念。例如,这三人的论文并没有解释如何预测何时、哪些度量标准将显示LLM的急剧改善,东北大学的计算机科学家Tianshi Li说。“所以从这个意义上说,这些能力仍然是不可预测的,”她说。其他人,如现在在OpenAI工作、曾是BIG-bench论文作者之一的计算机科学家Jason Wei,认为早期关于突现的报告是合理的,因为对于像算术这样的能力来说,正确的答案确实是最重要的。
“这里绝对有一个有趣的对话,”AI初创公司Anthropic的研究科学家Alex Tamkin说。新论文巧妙地将多步骤任务分解,以识别个别组成部分的贡献,他说。“但这并不是全部故事。我们不能说所有这些跳跃都是幻觉。我仍然认为文献显示,即使你有一步预测或使用连续度量标准,你仍然会有不连续性,随着你的模型大小的增加,你仍然可以看到它以跳跃式的方式变得更好。”
即使可以用不同的测量工具解释今天的LLM中的突现,这很可能不适用于明天更大、更复杂的LLM。“当我们将LLM发展到下一个水平时,它们不可避免地将借鉴其他任务和模型的知识,”莱斯大学的计算机科学家Xia “Ben” Hu说。
这种对突现的不断考量不仅仅是研究人员要考虑的抽象问题。对于Tamkin来说,它直接涉及到预测LLM行为的持续努力。“这些技术是如此广泛且适用,”他说。“我希望社区将此作为一个起点,继续强调预测这些事物的科学有多么重要。我们如何不被下一代模型所惊讶?






























![[HackMyVM]靶场 Slowman](https://img-blog.csdnimg.cn/direct/43de8619dd2b466fb3a2dea339f372b2.png)