🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)Transformer模型简介
Transformer模型自从2017年被提出以来,就以其优异的性能在自然语言处理(NLP)领域取得了巨大成功。它的设计哲学是完全基于自注意力机制(Self-Attention Mechanism),这使得模型能够在处理序列数据时,更有效地捕捉长距离依赖关系。不同于此前的循环神经网络(RNN)和卷积神经网络(CNN),Transformer不依赖序列数据的迭代处理,能够并行处理序列,从而大幅提高了处理效率和模型性能。
Transformer架构
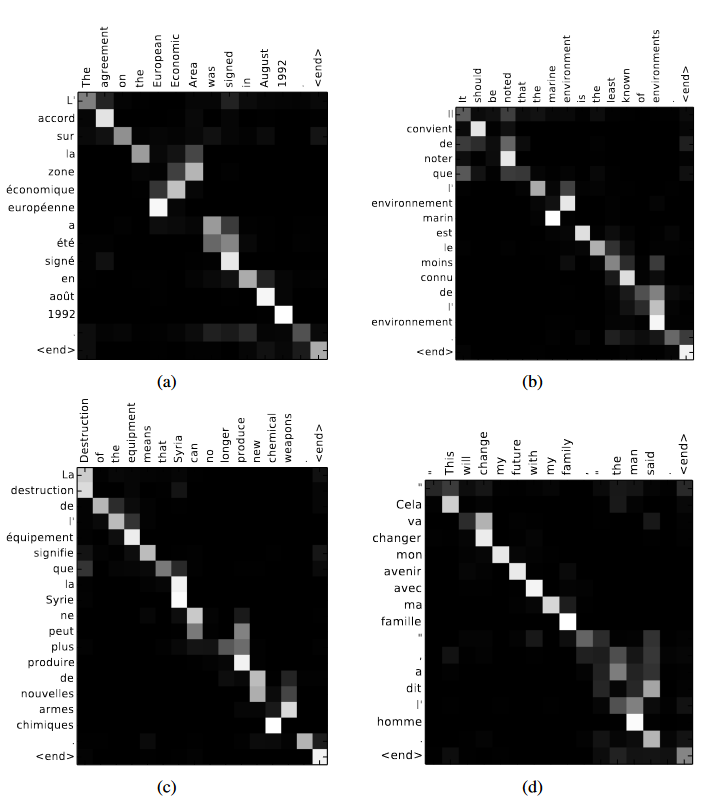
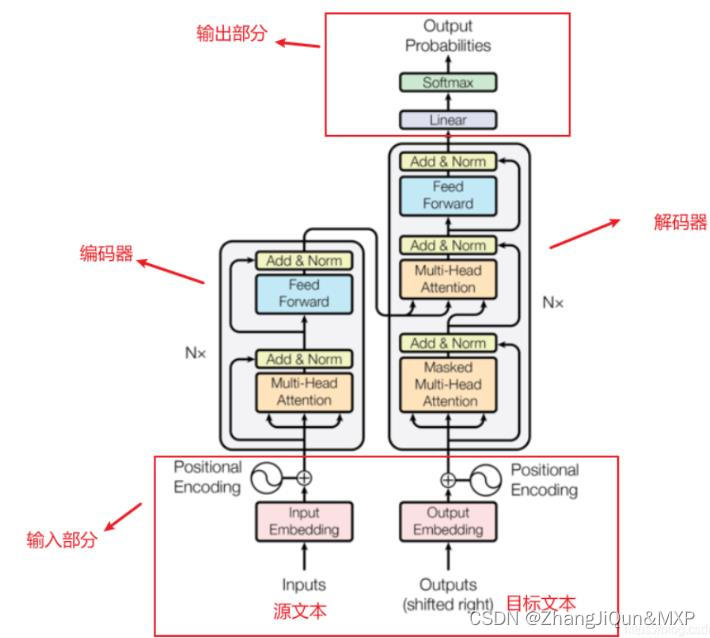
Transformer架构主要由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责处理输入序列,解码器则基于编码器的输出及之前的解码器输出生成目标序列。两者均由多个相同的层堆叠而成,每一层包含两个主要部分:自注意力层和前馈神经网络。自注意力机制允许模型在序列的任意位置间直接进行交互和学习,使得Transformer能够更好地理解文本。
代码示例
使用Hugging Face的transformers库来加载一个预训练的Transformer模型,并对一个句子进行编码。
from transformers import BertTokenizer, BertModel
# 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 准备输入
inputs = tokenizer("Hello, world!", return_tensors="pt")
# 前向传播,获取编码后的表示
with torch.no_grad():
outputs = model(**inputs)
# 获取最后一层的隐藏状态
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states)