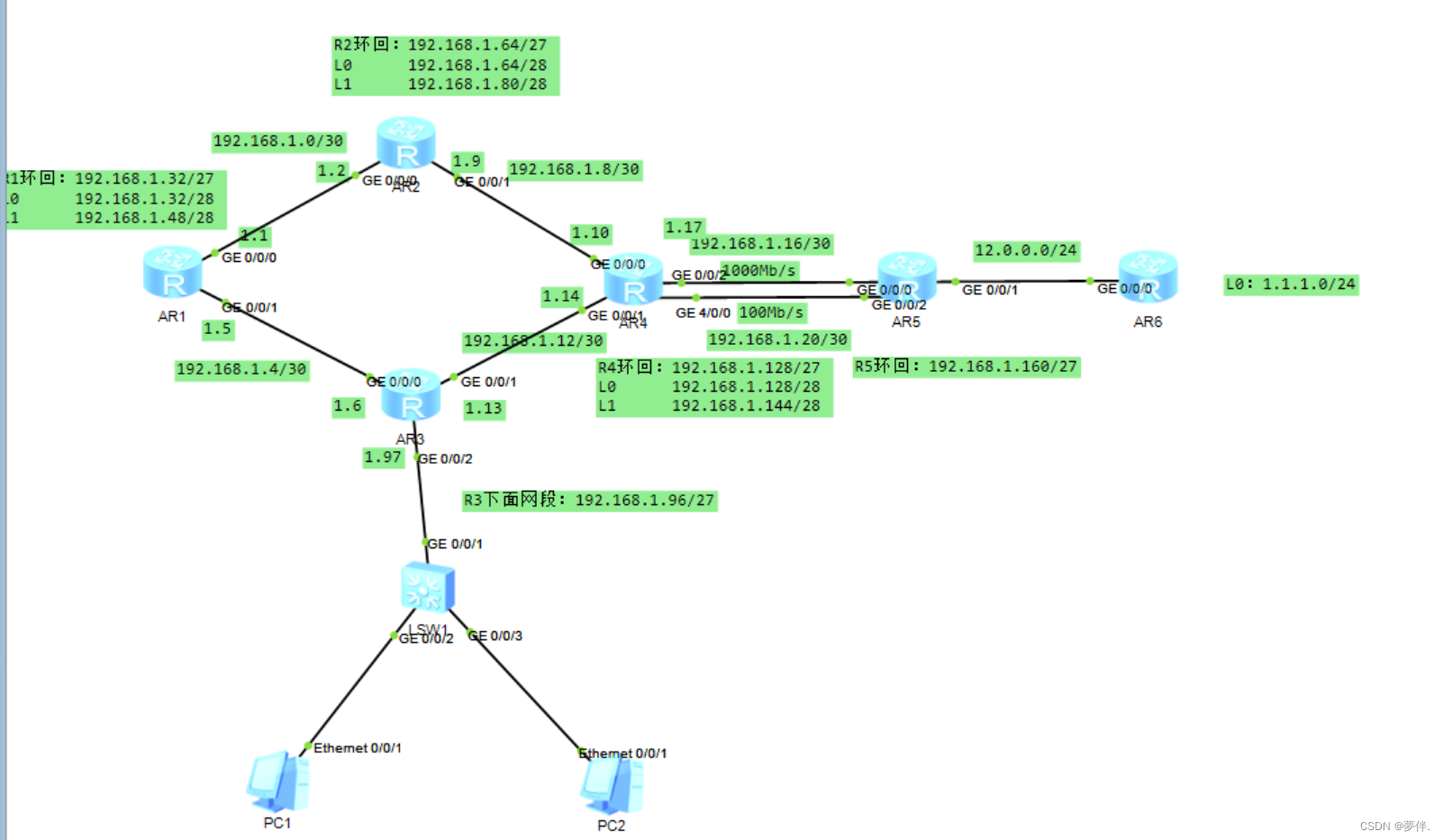
正则表达式
1.1正则简介
正则表达式,其实就是一些有特殊含义的符号:? . * + ^ $ () {}
注意区分正则和通配符
1、通配符主要是针对文件名,例如找文件名以txt为结尾的:*txt
2、正则主要是针对文件内容的,例如匹配文件的一行内容是以txt为结尾:*.txt
1.2基本正则
1.2.1匹配位置
1、匹配行首 ^
2、匹配行尾 $
3、匹配单词首部 \<
4、匹配单词尾部 \>
案例:
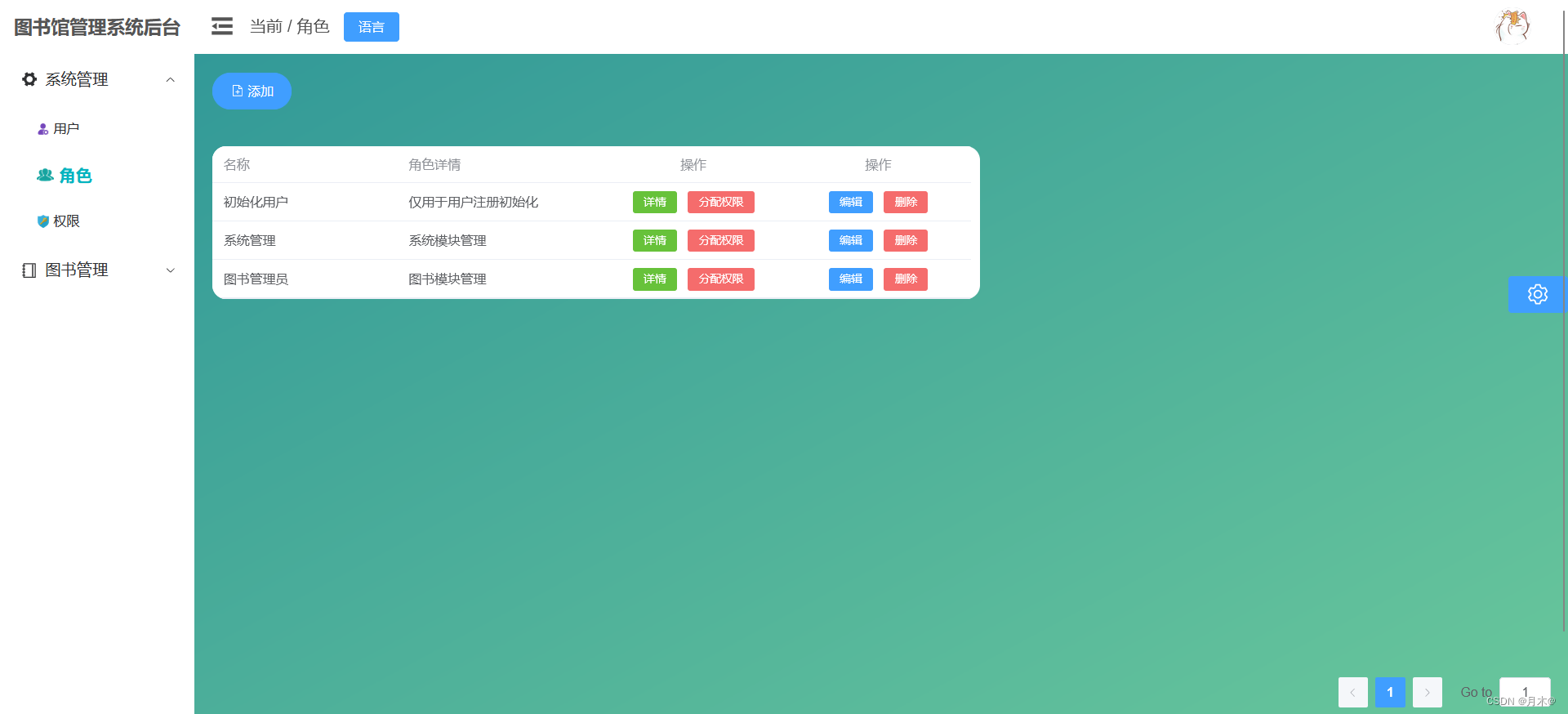
1、找到root的行
grep "root" a.txt
2、找到root开头的行
grep "^root" a.txt
3、找到root结尾的行
grep "root$" a.txt
4、找到包含root单词的行grep "\<root\>" a.txt
1.2.2 匹配范围
[ ] 表示限定一个范围
[0-9] 表示0-9之间的任意一个数字
[a-z] 表示任意一个小写字母
[A-Z] 表示任意一个大写字母
[0-9a-zA-Z] 表示人一个数字或者字母
[a-zA-Z] 表示任意一个字母
[a-Z] 表示任意一个字母
[acd39] 表示这五个字符中的任意一个字符
[[:space:]] 表示一个空格[[:digit:]] 表示任意一个数字
[[:lower:]] 表示任意一个小写字母
[[:upper:]] 表示任意一个大写字母
[[:alnum:]] 表示任意一个数字或者字母
[[:punct:]] 表示任意一个符号
[[:digit:][:space:]] 表示一个空格或者任意一个数字
案例:
1、匹配以字母a或c或f为开头的行
grep "^[acf]" 1.txt
2、匹配以数字或者空格或者#为开头的行
grep "^[[:space:][:digit:]#]" 1.txt
3、匹配以#为开头,后面是空格,空格后是非空字符
grep "^#[[:space:]][[:alnum:][:punct:]]
匹配范围以外的字符
[^XXX]
案例:
1、匹配135以外的字符
grep "[^135]" a.txt
2、匹配不是1 3 5为开头的行grep "^[^135]" a.txt
3、匹配以非空格为开头的行grep "^[^[:space:]]" a.txt
1.2.3 次数匹配
. 表示任意一个字符
* 表示其前面的字符出现任意次数【任意次可以使0次、1次、无数次】
\{m,n\} 表示其前面的字符出现最少m次,最多n次
\{3,7\} 表示其前面的字符出现最少3次,最多7次
\{3,\} 表示其前面的字符最少出现3次
\{,7\} 表示其前面的字符最多出现7次
\{3,3\} 表示其前面的字符出现3次
? 表示其前面的字符0次或者1次 [最多一次] - 扩展正则的选项
+ 表示其前面的字符出现最少一次 - 扩展正则的选项
案例:
1、过滤文件a.txt中,a前面至少有3个b的行
grep "b\{3,\}a" a.txt
2、过滤文件a.txt中,a前面最多有1个b的行grep "b\{,1\}a" a.txt
grep -E "b?a" a.txt
3、过滤文件a.txt中,a前面最少有1个b的行grep -E "b+a" a.txt
grep "b\{1,\}a" a.txt
4、过滤a和c之间有两个字符的行
grep "a..c" a.txt
常用的组合
.* 可表示任意个任意字符
案例:
1、匹配以#为开头的行,而且以数字为结尾的行
grep "^#.*[[:digit:]]$" a.txt
2、匹配出现了两个数字的行grep "[0-9].*[0-9]" a.txt
1.2.4 分组
\( 定位分组的位置\)
\1 引用第一个分组的内容
\2 引用第二个分组的内容
案例:
1、匹配出现两个相同数字的行
grep "\([0-9]\).*\1" a.txt
测试代码
i love my loverhe love his likershe like her lovershe love her liker
输出前后一致的行,例如前后都是love或者前后都是likegrep -E "(l..e).*\1" a.txt
1.2.5 或
| 或
测试对象
sadfa cat asfasdf Cat a asdf
案例:匹配cat Cat
grep -E "(c|C)at" 6.txt
grep -E "(cat|Cat)" 6.txt