论文标题:RT-H: Action Hierarchies Using Language
论文链接:https://arxiv.org/pdf/2403.01823.pdf
项目链接:RT-H: Action Hierarchies Using Language

Robot Transformer with Action Hierarchies使用行动层级的机器人Transformer
端到端框架RT-H:单一模型同时处理语言动作和行动查询
一、RT-H action hierarchy
1. 将复杂任务分解成简单的语言指令
2. 将语言指令转化为机器人行动
3. 支持对模型进行语言动作干预的微调
4. 开发了一种自动化方法,从机器人本体感受中提取简化的语言动作集,建立了超过2500个语言动作数据库,无需手动标注
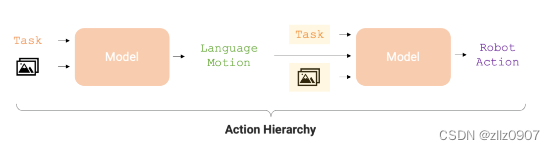
举例:
给定任务【盖上开心果罐的盖子】和场景图像,
RT-H会利用视觉语言模型(VLM)预测语言动作(motion),如【向前移动手臂】和【向右移动手臂】,
然后根据这些语言动作,预测机器人的行动(action)。
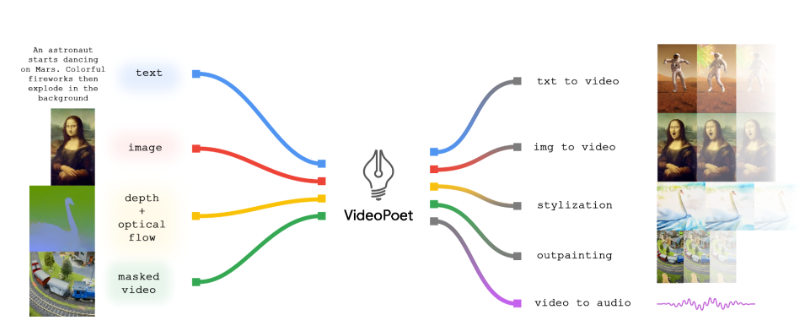
二、模型架构
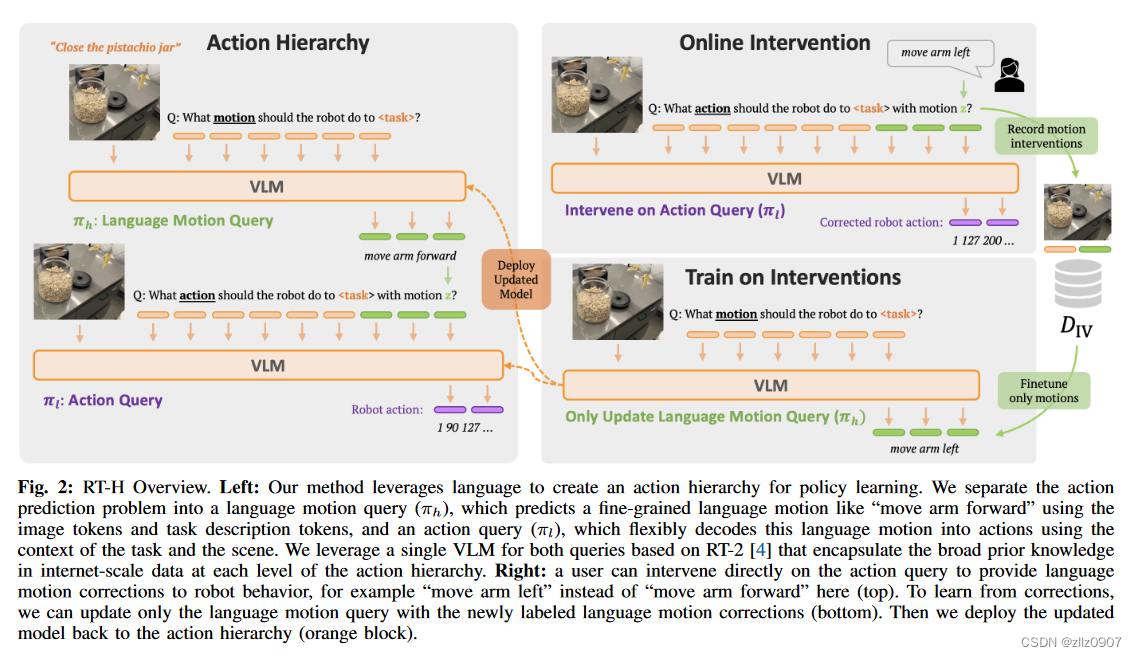
左图:
方法利用语言为policy学习创建一个行动层次结构。将动作预测问题分为语言运动查询(πh)和动作查询(πl),前者使用图像标记和任务描述标记预测像“向前移动手臂”这样的细粒度语言运动,后者使用任务和场景的上下文灵活地将这种语言运动解码为动作。利用基于 RT-2 的单一视觉语言模型(VLM)处理这两个查询,该模型在动作层次结构的每个层级都封装了互联网规模数据中的广泛先验知识。
右图:
用户可以直接干预动作查询,为机器人行为提供语言动作校正,例如此处的“向左移动手臂”而不是“向前移动手臂”(顶部)。为了从校正中学习,我们只能使用新标记的语言运动校正更新语言运动查询(底部)。然后,我们将更新后的模型部署回动作层次结构中(橙色块)。