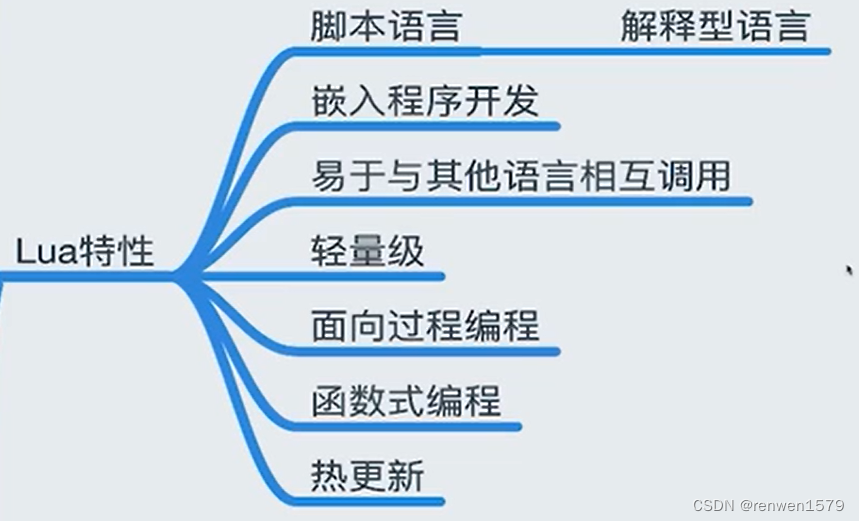
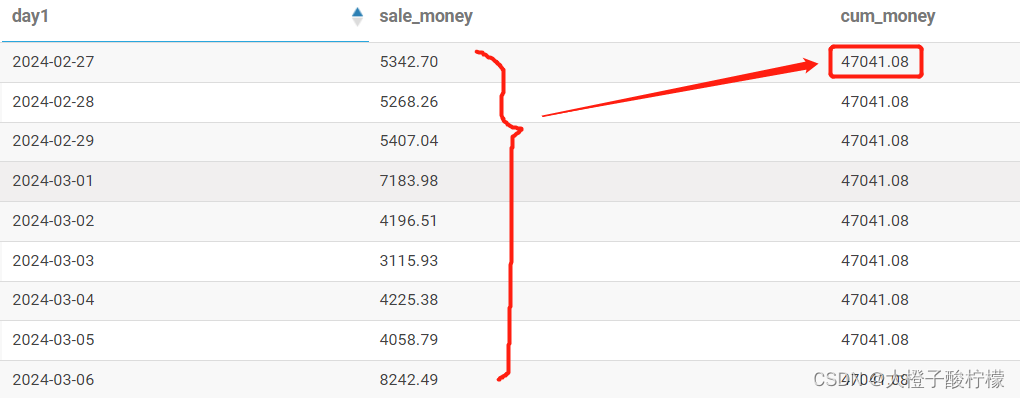
相关系数是用来衡量两个变量之间线性相关程度的指标。它的取值范围在-1到1之间,当相关系数为1时表示两个变量完全正相关(即一个变大另一个也变大),当相关系数为-1时表示两个变量完全负相关(即一个变大另一个变小),当相关系数为0时表示两个变量不存在线性相关性。
常用的相关系数有 Pearson 相关系数(用于衡量两个连续变量之间的线性相关性),Spearman 相关系数(用于衡量两个变量之间的等级相关性)等。相关系数的计算可以帮助我们了解数据之间的关系,对于统计分析和建模非常重要。
皮尔逊(pearson):
皮尔逊相关系数(Pearson correlation coefficient)衡量了两个连续变量之间的线性关系强度和方向。取值范围在-1到1之间,-1表示完全负相关,1表示完全正相关,0表示无线性相关
计算公式:

皮尔逊相关系数适用场景:
- 适用于连续变量之间的线性关系分析,例如:身高和体重之间的相关性分析、温度和销售额之间的相关性分析等。
- 适用于正态分布的数据或者满足线性关系的数据。
斯皮尔曼(spearman):
斯皮尔曼相关系数(Spearman’s rank correlation coefficient)用于度量两个变量之间的等级关系的强度和方向。它通过将变量的观测值转换为等级,然后计算这些等级之间的皮尔逊相关系数来实现。
计算公式:

斯皮尔曼相关系数适用场景:
- 适用于两个变量之间的等级关系分析,不要求数据满足线性关系。
- 适用于数据不满足正态分布或存在异常值的情况,更具有鲁棒性。
肯德尔(kendall):
肯德尔相关系数(Kendall rank correlation coefficient)也用于测量变量之间的等级关系。与斯皮尔曼相关系数类似,它使用变量的等级而不是实际值,来计算两个变量之间的相关性。
计算公式;
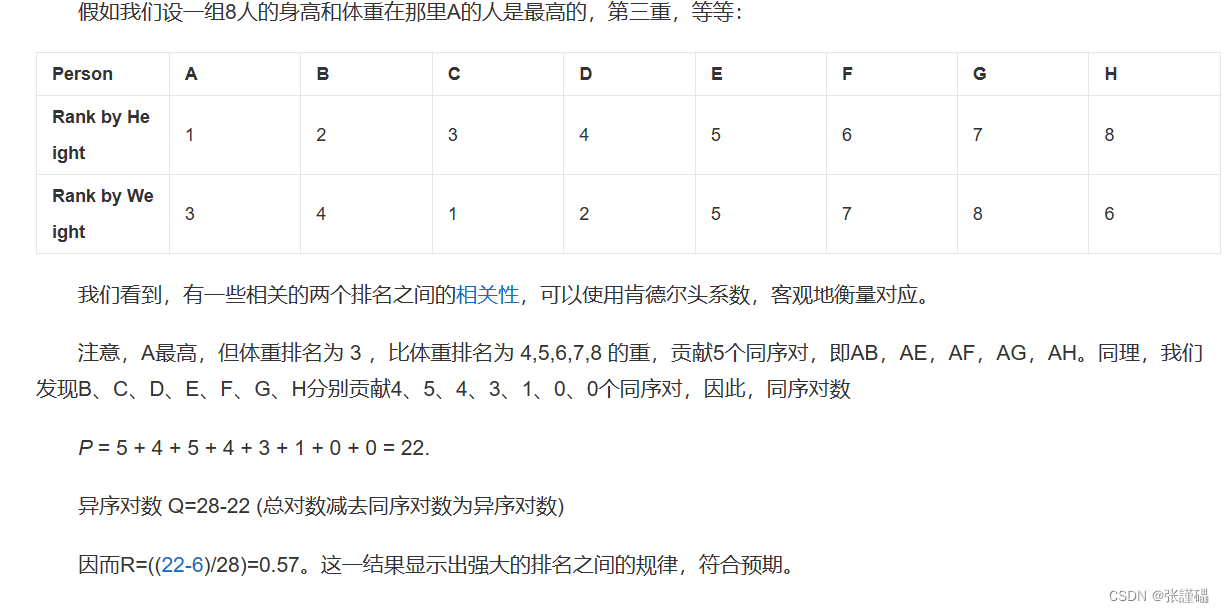
肯德尔相关系数适用场景:
- 适用于两个变量之间的等级关系分析,也不要求数据满足线性关系。
- 在样本数据较小时或存在重复数据时,肯德尔相关系数通常比较适用。
- 对异常值相对比较敏感的情况下,肯德尔相关系数也更可靠。
这三种相关系数都是用来度量变量之间关系的强度和方向,但适用于不同类型的数据和假设。
实例数据集:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 4.9 | 3 | 1.4 | 0.2 | 0 |
| 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 5 | 3.6 | 1.4 | 0.2 | 0 |
| 5.4 | 3.9 | 1.7 | 0.4 | 0 |
| 4.6 | 3.4 | 1.4 | 0.3 | 0 |
| 5 | 3.4 | 1.5 | 0.2 | 0 |
| 4.4 | 2.9 | 1.4 | 0.2 | 0 |
| 4.9 | 3.1 | 1.5 | 0.1 | 0 |
| 5.4 | 3.7 | 1.5 | 0.2 | 0 |
| 4.8 | 3.4 | 1.6 | 0.2 | 0 |
| 4.8 | 3 | 1.4 | 0.1 | 0 |
| 4.3 | 3 | 1.1 | 0.1 | 0 |
| 5.8 | 4 | 1.2 | 0.2 | 0 |
| 5.7 | 4.4 | 1.5 | 0.4 | 0 |
| 5.4 | 3.9 | 1.3 | 0.4 | 0 |
| 5.1 | 3.5 | 1.4 | 0.3 | 0 |
| 5.7 | 3.8 | 1.7 | 0.3 | 0 |
| 5.1 | 3.8 | 1.5 | 0.3 | 0 |
| 5.4 | 3.4 | 1.7 | 0.2 | 0 |
| 5.1 | 3.7 | 1.5 | 0.4 | 0 |
| 4.6 | 3.6 | 1 | 0.2 | 0 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 |
| 4.8 | 3.4 | 1.9 | 0.2 | 0 |
| 5 | 3 | 1.6 | 0.2 | 0 |
| 5 | 3.4 | 1.6 | 0.4 | 0 |
| 5.2 | 3.5 | 1.5 | 0.2 | 0 |
| 5.2 | 3.4 | 1.4 | 0.2 | 0 |
| 4.7 | 3.2 | 1.6 | 0.2 | 0 |
| 4.8 | 3.1 | 1.6 | 0.2 | 0 |
| 5.4 | 3.4 | 1.5 | 0.4 | 0 |
| 5.2 | 4.1 | 1.5 | 0.1 | 0 |
| 5.5 | 4.2 | 1.4 | 0.2 | 0 |
| 4.9 | 3.1 | 1.5 | 0.2 | 0 |
| 5 | 3.2 | 1.2 | 0.2 | 0 |
| 5.5 | 3.5 | 1.3 | 0.2 | 0 |
| 4.9 | 3.6 | 1.4 | 0.1 | 0 |
| 4.4 | 3 | 1.3 | 0.2 | 0 |
| 5.1 | 3.4 | 1.5 | 0.2 | 0 |
| 5 | 3.5 | 1.3 | 0.3 | 0 |
| 4.5 | 2.3 | 1.3 | 0.3 | 0 |
| 4.4 | 3.2 | 1.3 | 0.2 | 0 |
| 5 | 3.5 | 1.6 | 0.6 | 0 |
| 5.1 | 3.8 | 1.9 | 0.4 | 0 |
| 4.8 | 3 | 1.4 | 0.3 | 0 |
| 5.1 | 3.8 | 1.6 | 0.2 | 0 |
| 4.6 | 3.2 | 1.4 | 0.2 | 0 |
| 5.3 | 3.7 | 1.5 | 0.2 | 0 |
| 5 | 3.3 | 1.4 | 0.2 | 0 |
| 7 | 3.2 | 4.7 | 1.4 | 1 |
| 6.4 | 3.2 | 4.5 | 1.5 | 1 |
| 6.9 | 3.1 | 4.9 | 1.5 | 1 |
| 5.5 | 2.3 | 4 | 1.3 | 1 |
| 6.5 | 2.8 | 4.6 | 1.5 | 1 |
| 5.7 | 2.8 | 4.5 | 1.3 | 1 |
| 6.3 | 3.3 | 4.7 | 1.6 | 1 |
| 4.9 | 2.4 | 3.3 | 1 | 1 |
| 6.6 | 2.9 | 4.6 | 1.3 | 1 |
| 5.2 | 2.7 | 3.9 | 1.4 | 1 |
| 5 | 2 | 3.5 | 1 | 1 |
| 5.9 | 3 | 4.2 | 1.5 | 1 |
| 6 | 2.2 | 4 | 1 | 1 |
| 6.1 | 2.9 | 4.7 | 1.4 | 1 |
| 5.6 | 2.9 | 3.6 | 1.3 | 1 |
| 6.7 | 3.1 | 4.4 | 1.4 | 1 |
| 5.6 | 3 | 4.5 | 1.5 | 1 |
| 5.8 | 2.7 | 4.1 | 1 | 1 |
| 6.2 | 2.2 | 4.5 | 1.5 | 1 |
| 5.6 | 2.5 | 3.9 | 1.1 | 1 |
| 5.9 | 3.2 | 4.8 | 1.8 | 1 |
| 6.1 | 2.8 | 4 | 1.3 | 1 |
| 6.3 | 2.5 | 4.9 | 1.5 | 1 |
| 6.1 | 2.8 | 4.7 | 1.2 | 1 |
| 6.4 | 2.9 | 4.3 | 1.3 | 1 |
| 6.6 | 3 | 4.4 | 1.4 | 1 |
| 6.8 | 2.8 | 4.8 | 1.4 | 1 |
| 6.7 | 3 | 5 | 1.7 | 1 |
| 6 | 2.9 | 4.5 | 1.5 | 1 |
| 5.7 | 2.6 | 3.5 | 1 | 1 |
| 5.5 | 2.4 | 3.8 | 1.1 | 1 |
| 5.5 | 2.4 | 3.7 | 1 | 1 |
| 5.8 | 2.7 | 3.9 | 1.2 | 1 |
| 6 | 2.7 | 5.1 | 1.6 | 1 |
| 5.4 | 3 | 4.5 | 1.5 | 1 |
| 6 | 3.4 | 4.5 | 1.6 | 1 |
| 6.7 | 3.1 | 4.7 | 1.5 | 1 |
| 6.3 | 2.3 | 4.4 | 1.3 | 1 |
| 5.6 | 3 | 4.1 | 1.3 | 1 |
| 5.5 | 2.5 | 4 | 1.3 | 1 |
| 5.5 | 2.6 | 4.4 | 1.2 | 1 |
| 6.1 | 3 | 4.6 | 1.4 | 1 |
| 5.8 | 2.6 | 4 | 1.2 | 1 |
| 5 | 2.3 | 3.3 | 1 | 1 |
| 5.6 | 2.7 | 4.2 | 1.3 | 1 |
| 5.7 | 3 | 4.2 | 1.2 | 1 |
| 5.7 | 2.9 | 4.2 | 1.3 | 1 |
| 6.2 | 2.9 | 4.3 | 1.3 | 1 |
| 5.1 | 2.5 | 3 | 1.1 | 1 |
| 5.7 | 2.8 | 4.1 | 1.3 | 1 |
| 6.3 | 3.3 | 6 | 2.5 | 2 |
| 5.8 | 2.7 | 5.1 | 1.9 | 2 |
| 7.1 | 3 | 5.9 | 2.1 | 2 |
| 6.3 | 2.9 | 5.6 | 1.8 | 2 |
| 6.5 | 3 | 5.8 | 2.2 | 2 |
| 7.6 | 3 | 6.6 | 2.1 | 2 |
| 4.9 | 2.5 | 4.5 | 1.7 | 2 |
| 7.3 | 2.9 | 6.3 | 1.8 | 2 |
| 6.7 | 2.5 | 5.8 | 1.8 | 2 |
| 7.2 | 3.6 | 6.1 | 2.5 | 2 |
| 6.5 | 3.2 | 5.1 | 2 | 2 |
| 6.4 | 2.7 | 5.3 | 1.9 | 2 |
| 6.8 | 3 | 5.5 | 2.1 | 2 |
| 5.7 | 2.5 | 5 | 2 | 2 |
| 5.8 | 2.8 | 5.1 | 2.4 | 2 |
| 6.4 | 3.2 | 5.3 | 2.3 | 2 |
| 6.5 | 3 | 5.5 | 1.8 | 2 |
| 7.7 | 3.8 | 6.7 | 2.2 | 2 |
| 7.7 | 2.6 | 6.9 | 2.3 | 2 |
| 6 | 2.2 | 5 | 1.5 | 2 |
| 6.9 | 3.2 | 5.7 | 2.3 | 2 |
| 5.6 | 2.8 | 4.9 | 2 | 2 |
| 7.7 | 2.8 | 6.7 | 2 | 2 |
| 6.3 | 2.7 | 4.9 | 1.8 | 2 |
| 6.7 | 3.3 | 5.7 | 2.1 | 2 |
| 7.2 | 3.2 | 6 | 1.8 | 2 |
| 6.2 | 2.8 | 4.8 | 1.8 | 2 |
| 6.1 | 3 | 4.9 | 1.8 | 2 |
| 6.4 | 2.8 | 5.6 | 2.1 | 2 |
| 7.2 | 3 | 5.8 | 1.6 | 2 |
| 7.4 | 2.8 | 6.1 | 1.9 | 2 |
| 7.9 | 3.8 | 6.4 | 2 | 2 |
| 6.4 | 2.8 | 5.6 | 2.2 | 2 |
| 6.3 | 2.8 | 5.1 | 1.5 | 2 |
| 6.1 | 2.6 | 5.6 | 1.4 | 2 |
| 7.7 | 3 | 6.1 | 2.3 | 2 |
| 6.3 | 3.4 | 5.6 | 2.4 | 2 |
| 6.4 | 3.1 | 5.5 | 1.8 | 2 |
| 6 | 3 | 4.8 | 1.8 | 2 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 |
| 6.7 | 3.1 | 5.6 | 2.4 | 2 |
| 6.9 | 3.1 | 5.1 | 2.3 | 2 |
| 5.8 | 2.7 | 5.1 | 1.9 | 2 |
| 6.8 | 3.2 | 5.9 | 2.3 | 2 |
| 6.7 | 3.3 | 5.7 | 2.5 | 2 |
| 6.7 | 3 | 5.2 | 2.3 | 2 |
| 6.3 | 2.5 | 5 | 1.9 | 2 |
| 6.5 | 3 | 5.2 | 2 | 2 |
| 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 5.9 | 3 | 5.1 | 1.8 | 2 |
这里以鸾尾花的数据集为例
皮尔逊(pearson)
代码实现:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 转换为 DataFrame
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
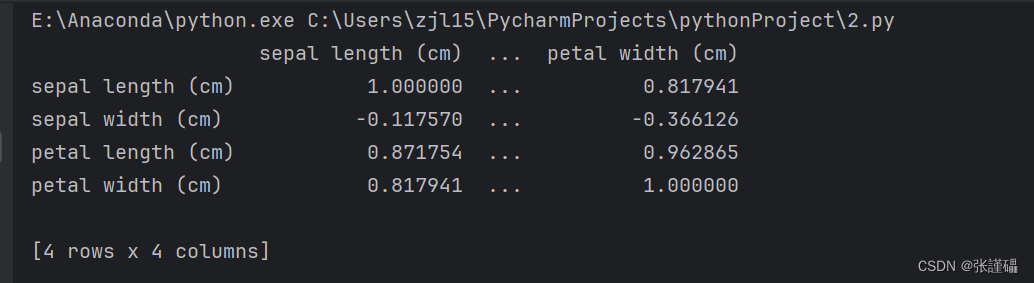
# 计算相关系数(pearson方法)
iris_pearson = iris_df.corr(method='pearson')
#输出计算结果
print(iris_pearson)
#生成特征热力图
plt.figure(figsize=(10,8))
sns.heatmap(iris_df.corr(method='kendall'),cmap="coolwarm",annot=True)
plt.show()
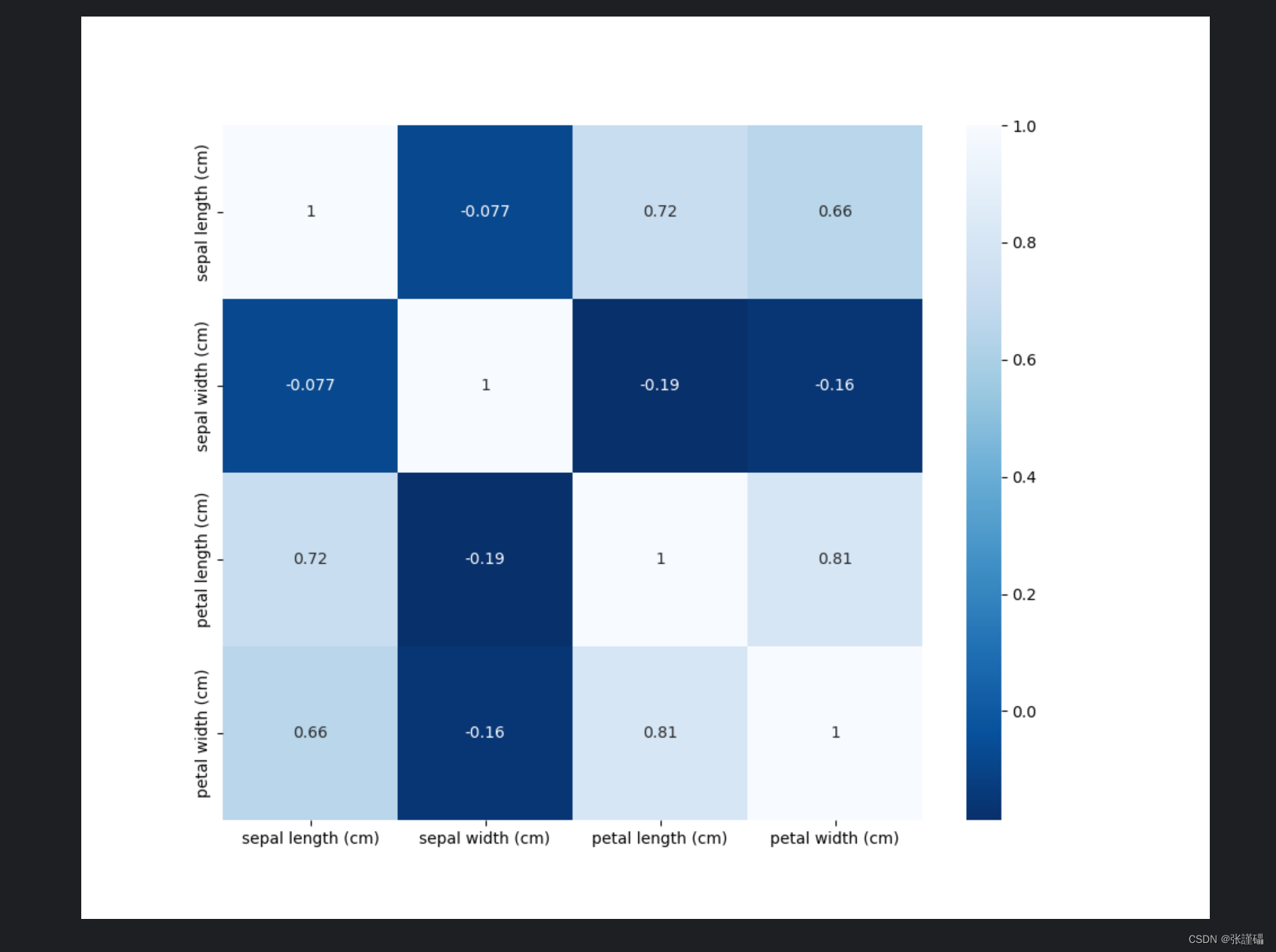
图片:
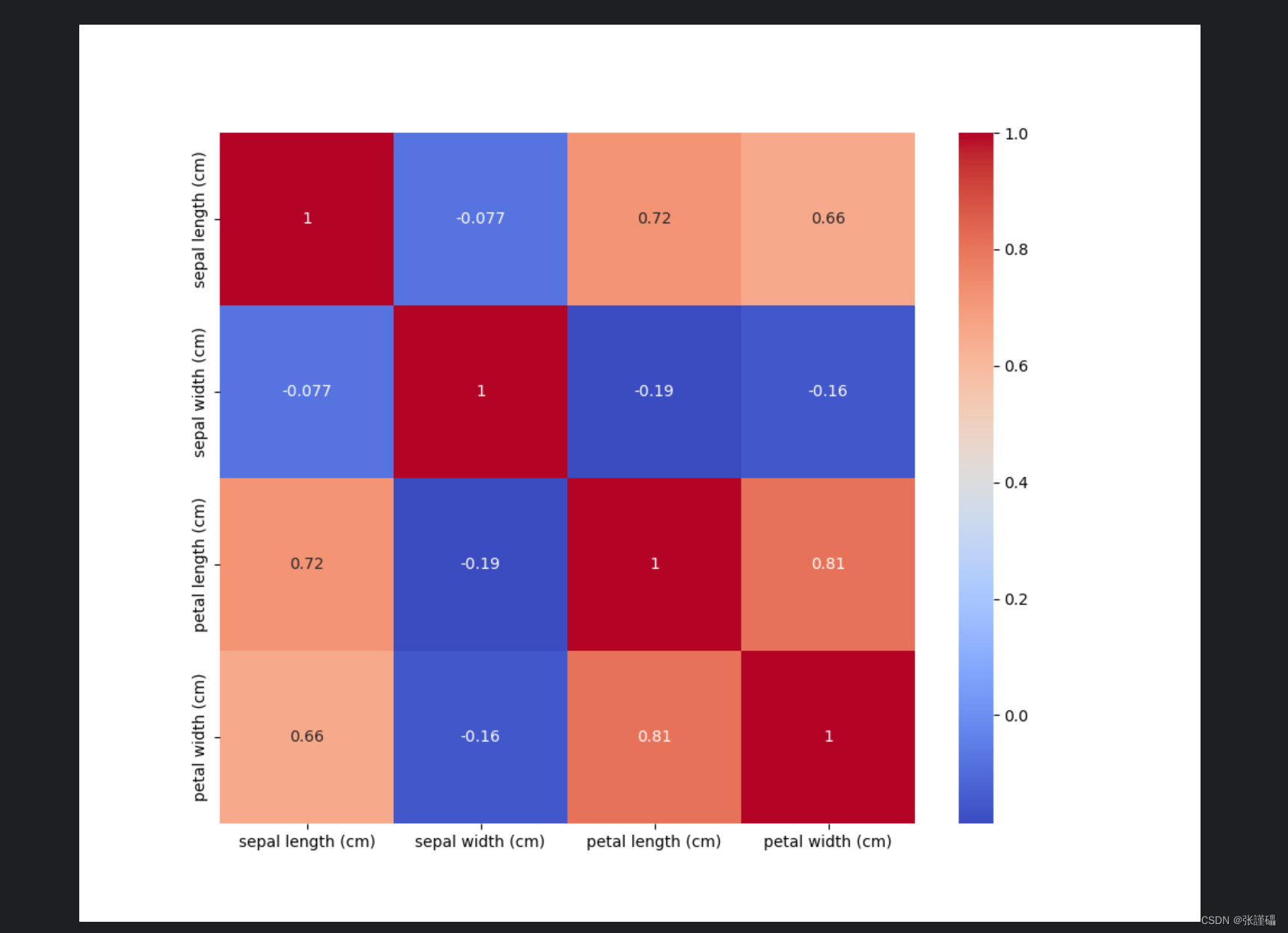
斯皮尔曼(spearman)
代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 转换为 DataFrame
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 计算相关系数(spearman方法)
iris_pearson = iris_df.corr(method='spearman')
#输出计算结果
print(iris_pearson)
#生成特征热力图
plt.figure(figsize=(10,8))
sns.heatmap(iris_df.corr(method='kendall'),cmap="cool",annot=True)
plt.show()
图片: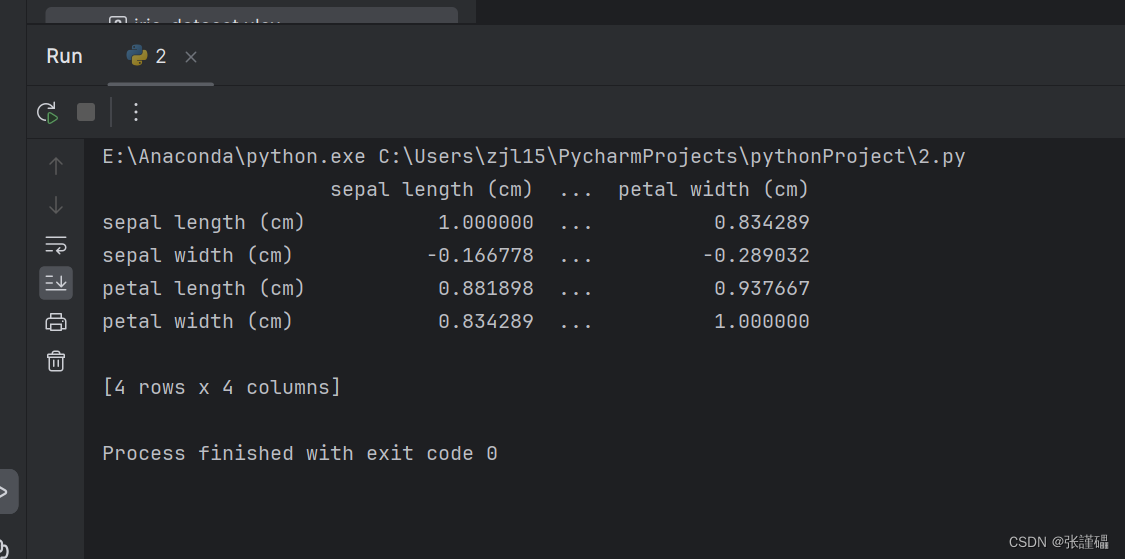
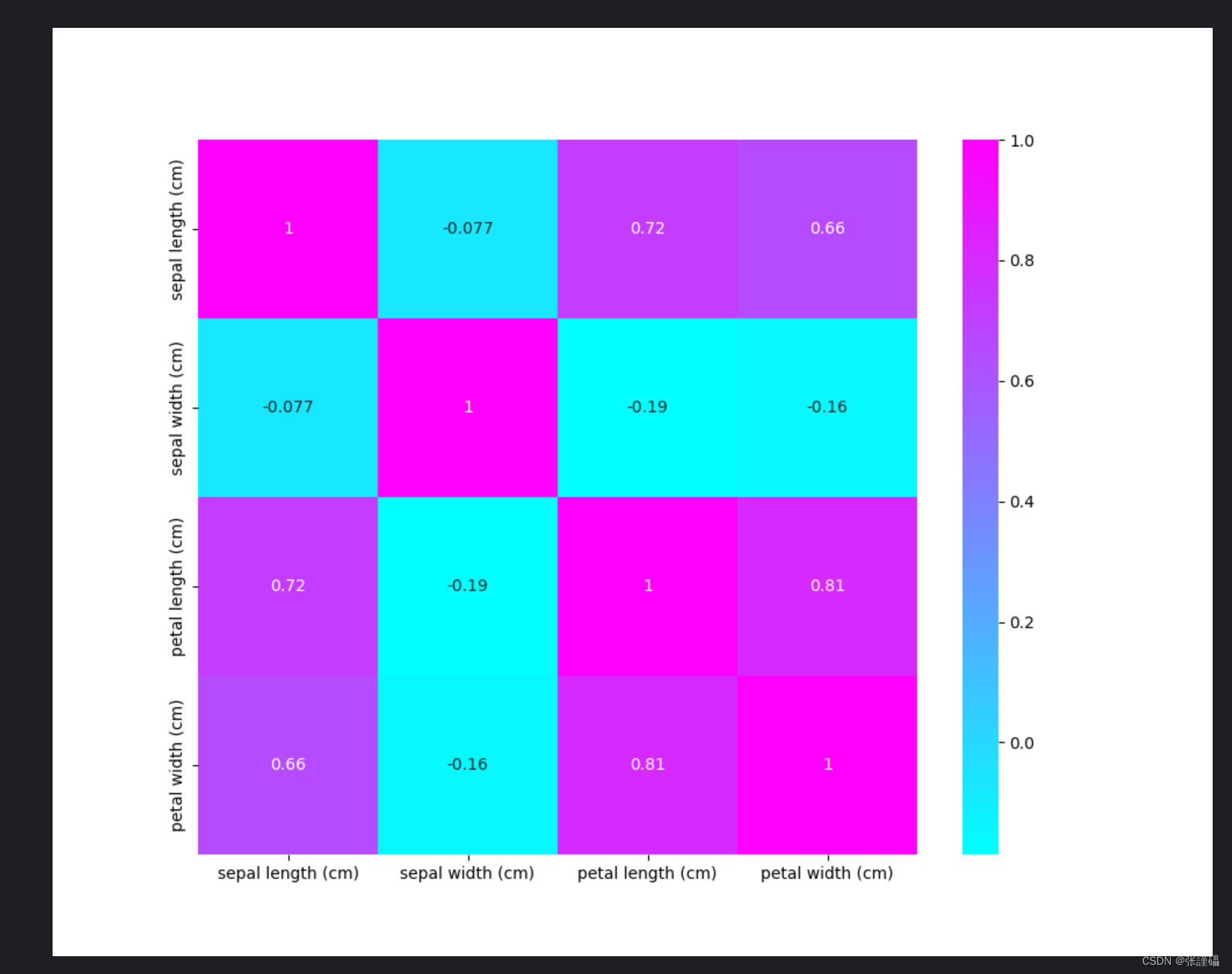
肯德尔(kendall)相关系数
代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 转换为 DataFrame
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 计算相关系数(kendall方法)
iris_pearson = iris_df.corr(method='kendall')
#输出计算结果
print(iris_pearson)
#生成特征热力图
plt.figure(figsize=(10,8))
sns.heatmap(iris_df.corr(method='kendall'),cmap="Blues_r",annot=True)
plt.show()
图片:
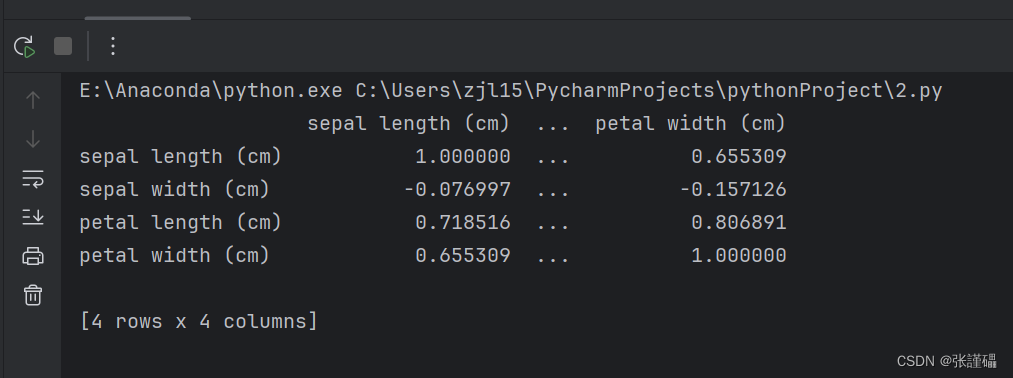

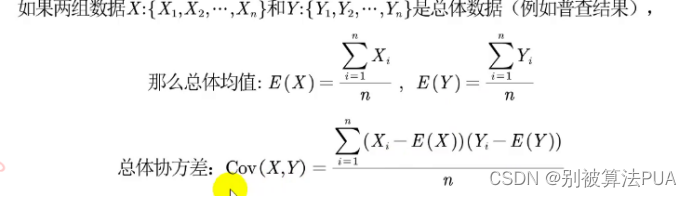



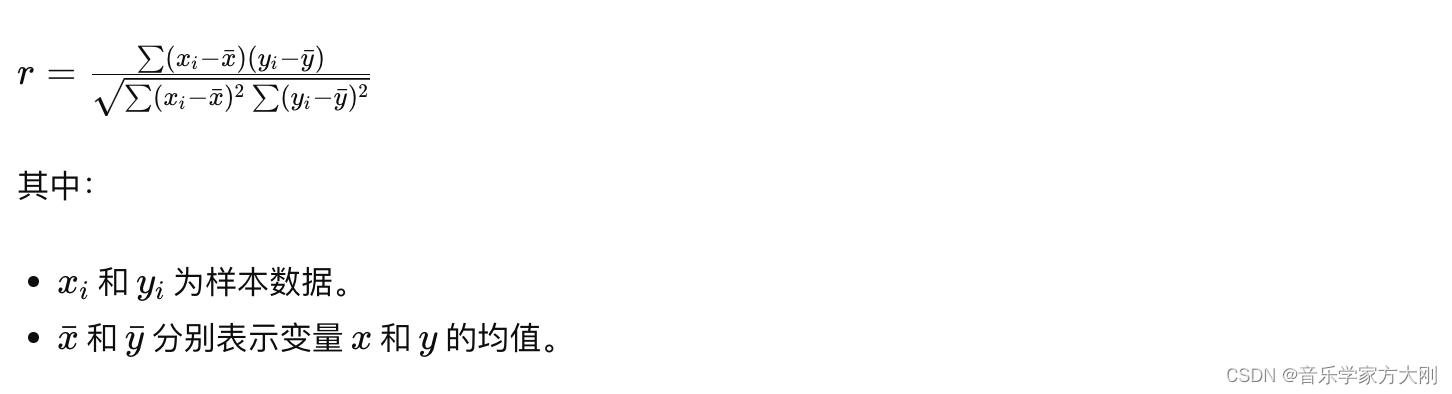























![[音视频学习笔记]七、自制音视频播放器Part2 - VS + Qt +FFmpeg 写一个简单的视频播放器](https://img-blog.csdn.net/20140508135954718?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbGVpeGlhb2h1YTEwMjA=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)