## 1. 引言
在当今的数据驱动世界中,实时数据处理变得越来越重要。Flink 提供了一个高性能、可扩展的平台,用于构建实时数据分析和处理应用。它支持事件时间处理和精确一次(exactly-once)处理语义,确保数据的准确性和一致性。Flink 的架构设计是其高性能和可靠性的基础。
## 2. Flink 架构概览
Flink 的架构可以分为以下几个主要部分:
- **Master Nodes (JobManager 和 TaskManager)**
- **JobGraph 和 ExecutionGraph**
- **DataStream API 和 Table API**
- **状态管理和容错机制**
- **部署模式**
### 2.1 Master Nodes
Flink 的 Master Nodes 包括 JobManager 和 TaskManager。JobManager 是负责接收提交的作业、管理作业的生命周期和调度任务的组件。TaskManager 负责执行作业中的任务,并与 JobManager 通信。
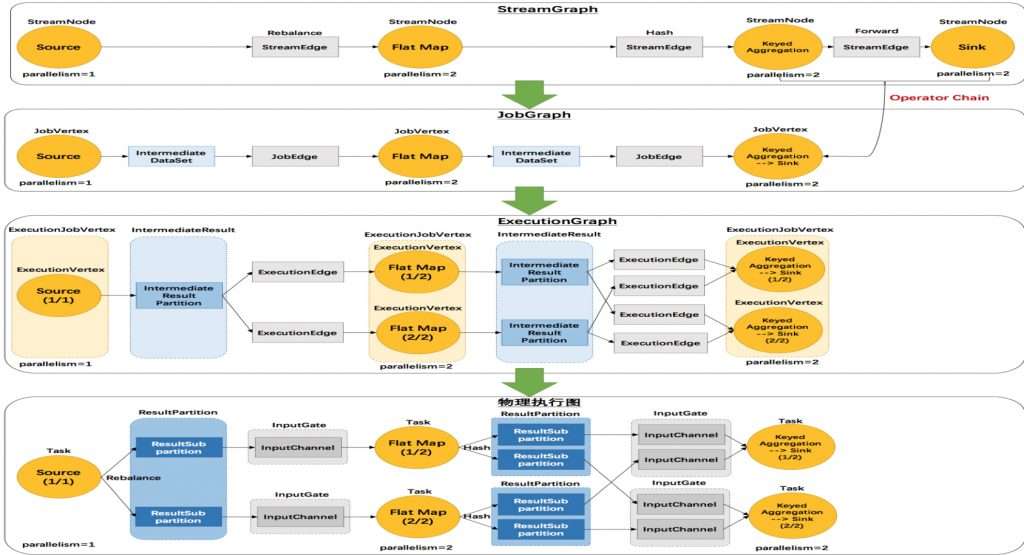
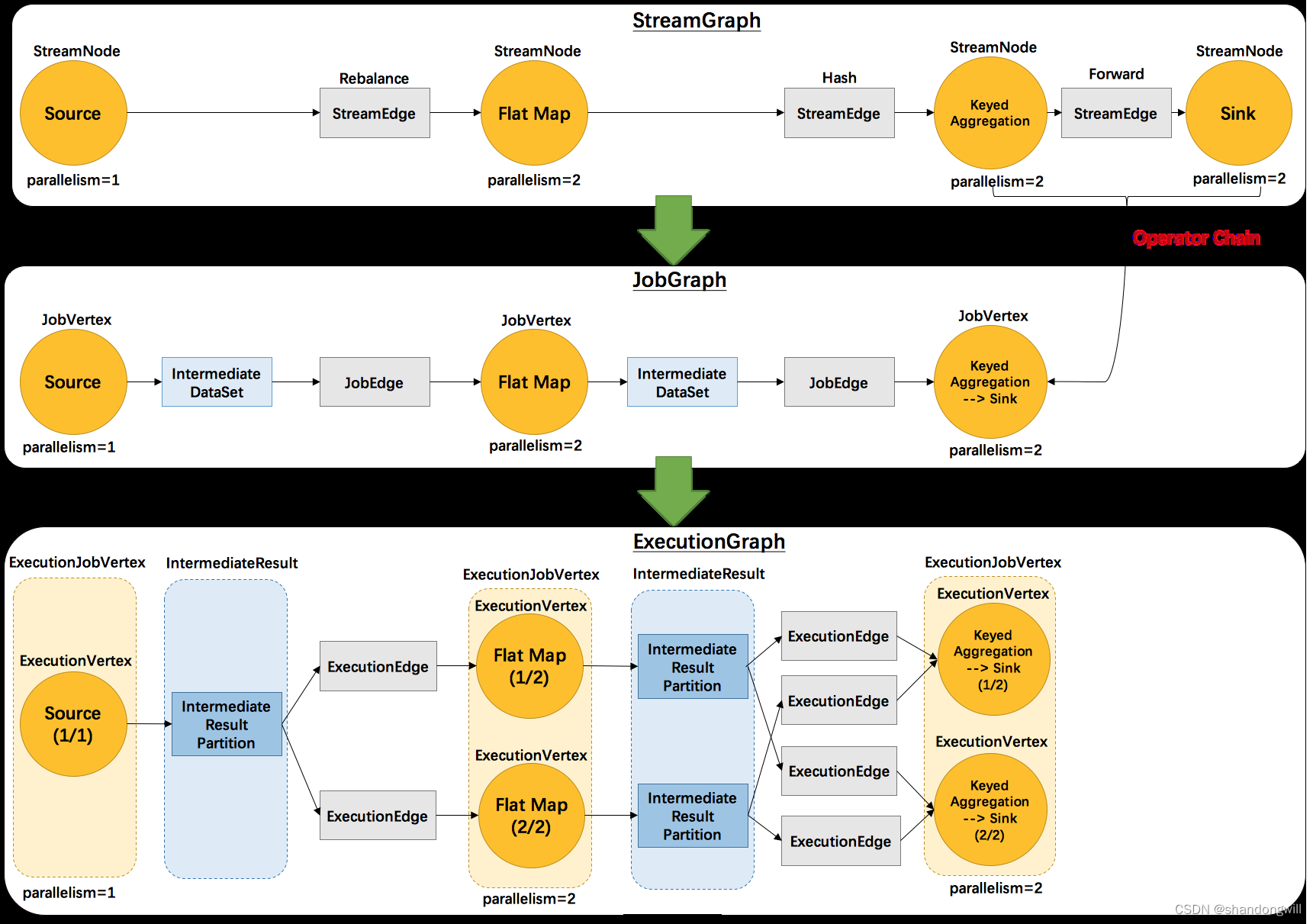
### 2.2 JobGraph 和 ExecutionGraph
JobGraph 是 Flink 作业的逻辑表示,它描述了作业的拓扑结构和转换操作。ExecutionGraph 是 JobGraph 的物理表示,它包含了任务的执行计划和资源分配。
### 2.3 DataStream API 和 Table API
DataStream API 是 Flink 的核心 API,用于构建流处理应用。Table API 是建立在 DataStream API 之上的声明式 API,它允许用户以 SQL 风格的方式进行流处理。
### 2.4 状态管理和容错机制
Flink 的状态管理是其强大的流处理能力的关键。它允许操作符(Operators)在处理事件时维护状态。Flink 的容错机制确保了状态的一致性和作业的高可用性。
### 2.5 部署模式
Flink 支持多种部署模式,包括 Standalone、YARN、Mesos 和 Kubernetes,以及 Session 和 Job 模式。
## 3. Flink 架构详细解析
### 3.1 JobManager
JobManager 是 Flink 集群的大脑,负责协调和管理作业。它的主要职责包括:
- **作业调度**:接收提交的作业,将作业的 JobGraph 转换为 ExecutionGraph,并调度任务到 TaskManager 上执行。
- **资源管理**:根据作业的资源需求和集群的状态,分配资源给任务。
- **故障恢复**:在发生故障时,负责重启失败的任务,并恢复状态。
### 3.2 TaskManager
TaskManager 是 Flink 集群的工作节点,负责执行具体的任务。每个 TaskManager 可以运行多个任务槽(Task Slot),每个槽可以运行一个并行任务。TaskManager 的主要职责包括:
- **执行任务**:根据 JobManager 的调度执行任务,并与 JobManager 报告任务的状态。
- **资源提供**:提供任务执行所需的资源,如 CPU、内存等。
- **状态管理**:为运行在其上的任务维护状态。
### 3.3 JobGraph 和 ExecutionGraph
JobGraph 是作业的逻辑表示,它包含了作业的所有操作符和连接。每个操作符代表一个转换步骤,连接定义了数据如何在操作符之间流动。JobGraph 通过一系列的转换操作构建而成。
ExecutionGraph 是 JobGraph 的执行表示,它包含了任务的详细执行计划。ExecutionGraph 中的顶点代表操作符,边代表数据的传输路径。ExecutionGraph 还包含了任务的调度信息,如任务分配给哪个 TaskManager。
### 3.4 DataStream API 和 Table API
DataStream API 是 Flink 用于构建流处理应用的编程接口。它提供了丰富的操作符,如 map、reduce、filter 等,以及窗口函数和状态管理功能。DataStream API 支持事件时间处理和水印机制,确保事件的准确处理。
Table API 是 Flink 的高级抽象,它允许用户以类似 SQL 的方式进行流处理。Table API 建立在 DataStream API 之上,提供了更简洁的语法和更强大的表达能力。
### 3.5 状态管理和容错机制
状态管理是 Flink 的核心特性之一。Flink 允许操作符在处理事件时维护状态,这些状态可以是键控状态、操作符状态或全局状态。Flink 使用状态后端(如 RocksDBStateBackend 或 FsStateBackend)来存储和管理状态。
Flink 的容错机制基于分布式快照算法,确保在发生故障时可以恢复到一个一致的状态。Flink 通过检查点(Checkpoints)和保存点(Savepoints)来实现状态的持久化和恢复。
### 3.6 部署模式
Flink 支持多种部署模式,以适应不同的生产环境。Standalone 模式是最简单的部署方式,适用于小规模集群。YARN、Mesos 和 Kubernetes 模式允许 Flink 在这些资源管理平台上运行,实现资源的动态分配和扩展。
## 4. Flink 架构的优势
Flink 的架构设计带来了多个优势:
- **高吞吐量和低延迟**:Flink 的事件驱动模型和优化的网络通信机制使其能够处理大规模数据流,同时保持低延迟。
- **强大的状态管理**:Flink 的状态管理能力使其能够处理复杂的流处理场景,如事件时间处理和状态丰富的转换。
- **高可用性**:Flink 的容错机制确保了作业的高可用性和状态的一致性。
- **灵活的部署**:Flink 支持多种部署模式,可以轻松集成到现有的基础设施中。
## 5. 结论
Flink 的架构设计是其成功的关键。它通过高效的事件处理模型、强大的状态管理和灵活的部署选项,为实时数据分析提供了一个可靠和高效的平台。随着数据流处理需求的不断增长,Flink 将继续在实时数据处理领域发挥重要作用。
## 6. 参考文献
- Apache Flink 官方文档
- Flink: Scalable Stream and Batch Data Processing, by Fabian Hueske, et al.
- Stream Processing with Apache Flink, by Vasiliki Kalavri