目录
3.2.5. HttpServer.cc (看一看 Http 请求格式)
3.2.6. HttpServer.cc (添加 HTTP 响应数据)
3.3.2. HttpServer.cc (获得HTTP请求的资源路径)
1. HTTP协议
在序列化和反序列化文章中, 我们以自己的方式制定了一个 (应用层) 协议,然后我们在去看待所谓的应用层。
应用层本质上就是程序员基于 socket 接口之上编写的具体逻辑。这些工作通常会涉及到对文本的处理和分析,比如数据的加工、解析、显示等操作。
而我们以前经常说一个概念: 业务逻辑。
业务逻辑:当服务端收到客户端请求,服务端处理这个请求的逻辑,我们称之为业务逻辑。而使用的 socket 接口不是业务逻辑,socket 接口只是提供了数据通信的基础,而业务逻辑才是决定了服务器如何处理这些数据的关键部分。
在初始网络 --- 网络基础文章中, 我们就知道, HTTP协议是在协议栈中的应用层的, 因此,HTTP协议一定会具有大量的文本分析和处理。
例如:在处理HTTP请求和响应时,服务器端和客户端需要对传输的文本数据进行解析、处理、生成和呈现,以确保正确的通信和数据交换。
2. 认识URL
URL(Uniform Resource Locator)统一资源定位符,是用于定位互联网上资源的地址标识符。它包含了资源的访问方式、资源的存放位置以及资源的参数等信息。通常,URL由若干部分组成:
- 协议(Scheme):指定访问资源所采用的协议,比如 http://、https://、ftp:// 等。
- 主机名(Host):指定资源所在的主机的域名或 IP 地址。
- 端口号(Port):可选部分,指定访问资源所用的端口号,默认值根据协议而定。
- 路径(Path):指定资源在服务器上的路径。
- 查询字符串(Query):可选部分,包含向服务器传递的参数信息。
- 片段标识符(Fragment):可选部分,标识资源中的一个片段,用于直接定位到资源的某个部分。
通过URL,用户可以准确地定位并访问互联网上的各种资源,比如网页、图片、视频等。
实际上,平时我们所说的 "网址" 指的就是网站的地址,而网站的地址本质上就是 URL(统一资源定位符)。因此,我们所在浏览器地址栏中输入的网站地址,实际上就是对应这个网站的 URL。
同时, 域名本质上就是IP地址, 只不过一般域名需要被解析 (域名解析) 得到服务端的IP。
域名本质上就是IP地址, 只不过为了人们使用和记忆,用域名呈现给大众。
- 每台连接到互联网的设备都有一个唯一的IP地址,用于标识该设备在网络中的位置。而域名则是将这些复杂的IP地址用更易记忆的字符序列代替,以方便用户访问网站或其他网络资源。
- 在通过域名访问网站时,首先需要进行域名解析。域名解析的过程是将一个域名解析成对应的IP地址。
- 域名解析这个过程通常通过DNS(Domain Name System)来完成,用户输入域名后,DNS服务器会返回对应的IP地址,然后浏览器使用这个IP地址与服务器建立连接并获取相应的网页内容。
- 因此,域名本质上是对IP地址的映射,使用域名能够让用户更方便地访问互联网资源,而通过域名解析可以获取到服务器的IP地址,实现数据的传输和通信。
客户端要访问服务器, 那么客户端必须要有服务端的 IP 和 port, 因为 IP地址确定全网中唯一的一台主机, port 标定唯一的一个进程, 这两者就可以标定全网中唯一的一个进程。
客户端向服务端发起 HTTP 请求时,端口号是可以被忽略的, 此时使用的就是默认端口。
- 如果服务端是默认端口号,比如 HTTP 的80端口或 HTTPS 的443端口,那么此时可以忽略 (不需要再URL中显示端口),因为它们是众所周知的,这里的众所周知指的是客户端是众所周知的。
- 但是如果服务端使用的是非默认端口号,比如8080,那么在URL中需要明确指定端口号,比如 http://XXXX.com:8080。
总而言之:客户端默认会使用协议所对应的默认端口号,但是当服务端使用非默认端口号时,客户端需要在URL中显式地指定端口号,以确保能够正确连接到服务端。

我们以上面的 URL 举例:
我们将域名后的第一个 "/" 称之为 Web根目录 。
在URL中,域名后面的第一个斜杠 "/" 代表着Web根目录。这个斜杠 "/" 后面的路径将会决定服务器上所请求资源的位置,即这个路径是相对于Web根目录的路径,用来指定具体的资源或文件。
注意: Web根目录,代表着某一段资源的起始路径,而并不是代表 Linux 中的根目录。
在人们的日常上网过程中,我们可以大致分为两种情况:
- 用户想通过客户端从服务端获取什么资源;
- 用户想通过客户端向服务端上传什么资源。
在互联网中, 一张图片、一个视频、一段文本等等, 我们将这些都称之为资源。
那么在这个资源没有被你获取到的时候, 这个资源在哪里呢?
答案是: 这个资源在服务器上, 一般情况下,这里的服务器指的就是 Linux 服务器。
而作为一个服务器, 可能存在着很多的资源。
这些资源在 Linux 的服务器上, 本质上都是一个文件。
客户端访问服务端资源时, 服务端是如何得知客户端访问的资源是哪一个呢, 在哪里呢?
答案: 服务端通过客户端发送的URL请求中的路径信息确定的。
- 客户端通过URL中的路径来请求和定位服务器端的资源,这个路径指定了服务器上所请求资源的唯一位置。
- 当客户端向服务端发起请求时,服务端会根据URL中的路径信息来找到对应的文件或者资源,然后将其读取内容并通过网络发送给客户端。
- 在Linux系统中,每个文件都有一个唯一的路径来标识其在文件系统中的位置。因此,在URL中的路径部分也类似地指定了服务器上资源的位置。通过这个路径,服务端能够找到对应的文件或内容。
总的来说,客户端通过URL中的路径请求资源时,路径的唯一性和准确性确保了客户端能够获得所需的资源,并且服务端能够找到并返回正确的内容。
2.1. URL中的四个主要字段
我们在这里主要介绍 URL (统一资源定位符) 中的四个主要字段:
例如:

- http:// : 代表着访问资源所采用的协议,也就是使用 HTTP 协议来进行通信。
- server ip: 域名,本质上就是服务端的IP地址,用来标定互联网中唯一的一台机器。
- port:端口号标识了服务器上提供服务的特定进程。在一台服务器上,可能会同时运行多个服务,通过端口号来区分不同的服务。
- /a/b/c/d.html:这部分是客户端希望访问的资源路径,服务端会根据这个路径来定位资源文件。通过这个路径,服务端可以准确找到客户端所需的资源,并将其发送给客户端。
服务端通过客户端发送URL中的路径信息,就可以锁定确定的资源。
我们将这种获取资源的方式称之为万维网。
对于公开的万维网资源,在全球范围内,只要我们知道它的URL,并可以正确锁定这个URL,就可以通过网络访问和获取这个资源。
这是万维网的基本工作原理之一:通过URL来唯一标识和定位网络资源,进而访问这些资源。
2.2. URL Encode && URL Decode
在 URL 中包含特殊字符时,如空格、问号、加号、汉字等,浏览器会自动对它们进行编码 (Encode),以确保 URL 的准确性和完整性。这种编码方式通常被称为 URL 编码或百分比编码(Percent Encoding)。
例如:对于 + 这个字符, 浏览器就会对其进行 Encode 编码。

当服务端接收到编码后的 URL,并希望提取或解析其中的特殊字符时,它需要先对 URL 进行解码 (Decode),将被转义的特殊字符恢复成原始的特殊字符。这个过程通常被称为 URL 解码或反转义。
总而言之:URL当中出现的特殊字符需要被编码,被编码 ( Encode ) 后,如果服务端想提取它需要先做解码 ( Decode );这样才能确保 URL 中的特殊字符不会造成歧义或错误解析。
3. HTTP 协议格式
- HTTP 协议是基于请求和响应的;
- 客户端向服务端发送的是 HTTP 请求,服务端向客户端发送的是 HTTP 响应;
- 我们将这种模式称之为 CS (Client - Server) 模式;
- CS 双方交互的报文, 就是 HTTP 请求或者 HTTP 响应。
- HTTP 协议是应用层协议,在底层使用 TCP (传输层协议) 进行通信。
- 在 HTTP 通信过程中,TCP 提供了可靠的传输,HTTP 协议本身并不负责处理连接管理,因此对于连接的建立和维护,需要经过 TCP 的三次握手过程,以确保双方建立可靠的连接。
- 从 HTTP 协议的角度来看,它并不关心底层 TCP 的连接管理细节,因为 TCP 协议已经负责处理了连接的建立、维护和释放等问题。
为了理解HTTP协议, 我们分为三个过程。
- 快速构建 HTTP 请求和响应的报文格式;
- 实现一个 HTTP demo;
- 通过该 demo 逐步分析过程,理解细节。
3.1. 快速构建 HTTP 请求和响应的报文格式
站在报文角度, HTTP 协议可以被看成是基于行的文本协议。
3.1.1. HTTP 请求格式
- 请求行:包含请求方法、请求URL,客户端的 HTTP 版本, 这三个字段以空格为分隔符, 并且最后以 "\r\n" 结尾。
- 请求报头:有若干个请求行组成。 每个请求行都是一个 key: value\r\n 结构,表示了客户端发送的额外信息,如请求的主机、内容类型、用户代理等。
- 空行:在请求行和请求报头之间存在一个空行,即 "\r\n"。用于分隔请求行和请求报头与请求正文。空行是必需的,用于告诉服务器请求头部的结束。
- 请求正文:HTTP 请求中的请求正文是可选的,通常用于传递客户端向服务器提交的数据,如表单数据、JSON 数据等。对于 GET 请求,通常不包含请求正文,而对于 POST 请求则可能包含请求正文。
HTTP 请求如图所示:

3.1.2. HTTP 响应格式
- 状态行:包含服务端的HTTP版本、状态码、状态码描述符。 这三个字段以空格为分隔符,并且最后以 "\r\n" 结尾。 例如 "HTTP/1.1 200 OK\r\n",代表含义是服务器使用 HTTP/1.1 版本协议成功处理了客户端的请求,并且成功返回了请求的资源。
- 响应报头:由多个 key: value\r\n 请求行组成。这些请求行提供了服务器返回响应的数据,如内容类型、响应时间、服务器类型等。
- 空行: 在状态行和响应报头之间存在一个空行,即 "\r\n"。用于分隔响应头部和响应正文。空行是必需的,用于告诉客户端响应头部的结束。
- 响应正文:HTTP 响应中的响应正文是可选的。通常用于包含服务端向客户端发送的实际资源,如 HTML 页面、图片、文本等。
HTTP 响应如图所示:

3.1.3. 关于 HTTP 请求 && 响应的宏观理解
首先,在学习协议的过程中,我们需要建立一个共识:
每一个协议是如何进行 (向下) 封装和 (向上) 解包的, 是如何将报文中的报头和正文信息进行区分的。
可以看到,HTTP 请求和 HTTP 响应中都有HTTP版本信息, 它们的区别在于:
- HTTP 请求中的 HTTP 版本代表的是: 客户端告诉服务端,客户端使用的HTTP是哪一个版本;
- HTTP 响应中的 HTTP 版本代表的是: 服务端告诉客户端,服务端使用的HTTP是哪一个版本。
对于一个报文而言,我们是需要将报头和有效载荷分开的, 因为在进行业务处理的时候并不需要报头信息, 只需要有效载荷。
- 在HTTP中, 所谓的有效载荷就是 HTTP中的正文部分;
- 那么 HTTP 是如何区分报头和有效载荷的呢?
- 答案是: 通过空行 "\r\n" 区分报头和有效载荷的, 只要读到了空行,就代表着报头信息被读完了,接下来的信息就是有效载荷!
- 这个空行标志着报头的结束,对于 HTTP 请求和响应都是一样的处理方式。
总而言之:在处理 HTTP 报文时,首先会解析报头部分以获取与请求或响应相关的信息,然后通过空行识别报头和有效载荷的分界线,进而提取和处理有效载荷中的实际数据内容。
既然可以通过空行将报头和有效载荷区分,那么一定能够把报头读完,既然报头可以读完, 那么一定能保证接下来读取的就是正文了。
可是,我们如何得知正文 (有效载荷) 的大小呢?
因为 HTTP 底层是 TCP协议,而TCP是面向字节流的,你如何保证你接下来读取的有效载荷是多少个字节呢?
很简单, 在请求和响应报头中都有一个属性字段: Content-Length, 该字段指定了正文部分的字节长度,这样接收端就能够准确知道需要读取多少字节的数据作为有效载荷。
因此,对于HTTP而言,只要按行读取内容, 读取到空行,就说明把报头信息读取完毕, 然后再根据报头信息中的相关字段 ( Content-Length ) 确定正文 (有效载荷) 的长度, 我们就可以保证将一个完整的http请求 (响应) 报文全部读取到。
3.2. 实现一个 HTTP demo
有了上面的初步理解后,我们就可以通过一个 HTTP demo 见一见 HTTP 请求和响应是怎样的。
这个 demo 也不多做处理, 我们先将 HTTP 请求获取到,并打印出来。
3.2.1. Sock.hpp
该模块主要用于封装 socket 接口。
#ifndef __SOCK_HPP_
#define __SOCK_HPP_
#include <iostream>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "Log.hpp"
namespace Xq
{
class Sock
{
public:
Sock() :_sock(-1) {}
// 创建套接字
void Socket(void)
{
_sock = socket(AF_INET, SOCK_STREAM, 0);
if(_sock == -1)
{
LogMessage(FATAL, "%s,%d\n", strerror(errno));
exit(1);
}
LogMessage(DEBUG, "listen sock: %d create success\n", _sock);
}
// 将该套接字与传入的地址信息绑定到一起
void Bind(const std::string& ip, uint16_t port)
{
sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = ip.empty() ? INADDR_ANY : inet_addr(ip.c_str());
int ret = bind(_sock, reinterpret_cast<const struct sockaddr*>(&addr), sizeof(addr));
if(ret == -1)
{
LogMessage(FATAL, "bind error\n");
exit(2);
}
}
// 封装listen 将该套接字设置为监听状态
void Listen(void)
{
int ret = listen(_sock, 10);
if(ret == -1)
{
LogMessage(FATAL, "listen error\n");
exit(3);
}
}
//封装accept
// 如果想获得客户端地址信息
// 那么我们可以用输出型参数
// 同时我们需要将服务套接字返回给上层
int Accept(std::string& client_ip, uint16_t* port)
{
struct sockaddr_in client_addr;
socklen_t addrlen = sizeof client_addr;
bzero(&client_addr, addrlen);
int server_sock = accept(_sock, \
reinterpret_cast<struct sockaddr*>(&client_addr), &addrlen);
if(server_sock == -1)
{
LogMessage(FATAL, "%s,%d\n", strerror(errno));
return -1;
}
// 将网络字节序的整数转为主机序列的字符串
client_ip = inet_ntoa(client_addr.sin_addr);
// 网络字节序 -> 主机字节序
*port = ntohs(client_addr.sin_port);
// 返回服务套接字
return server_sock;
}
// 向特定服务端发起连接
void Connect(struct sockaddr_in* addr, const socklen_t* addrlen)
{
int ret = connect(_sock,\
reinterpret_cast<struct sockaddr*>(addr), \
*addrlen);
if(ret == -1)
{
LogMessage(FATAL, "%s%d\n", strerror(errno));
}
}
// 服务端结束时, 释放监听套接字
~Sock(void)
{
if(_sock != -1)
{
close(_sock);
LogMessage(DEBUG, "close listen sock: %d\n", _sock);
}
}
public:
int _sock; // 套接字
};
}
#endif3.2.2. Log.hpp
日志的自我实现,
#pragma once
#include "Date.hpp"
#include <iostream>
#include <map>
#include <string>
#include <cstdarg>
#define LOG_SIZE 1024
// 日志等级
enum Level
{
DEBUG, // DEBUG信息
NORMAL, // 正常
WARNING, // 警告
ERROR, // 错误
FATAL // 致命
};
const char* pathname = "./log.txt";
void LogMessage(int level, const char* format, ...)
{
// 如果想打印DUBUG信息, 那么需要定义DUBUG_SHOW (命令行定义, -D)
#ifndef DEBUG_SHOW
if(level == DEBUG)
return ;
#endif
std::map<int, std::string> level_map;
level_map[0] = "DEBUG";
level_map[1] = "NORAML";
level_map[2] = "WARNING";
level_map[3] = "ERROR";
level_map[4] = "FATAL";
std::string info;
va_list ap;
va_start(ap, format);
char stdbuffer[LOG_SIZE] = {0}; // 标准部分 (日志等级、日期、时间)
snprintf(stdbuffer, LOG_SIZE, "[%s],[%s],[%s] ", level_map[level].c_str(), Xq::Date().get_date().c_str(), Xq::Time().get_time().c_str());
info += stdbuffer;
char logbuffer[LOG_SIZE] = {0}; // 用户自定义部分
vsnprintf(logbuffer, LOG_SIZE, format, ap);
info += logbuffer;
FILE* fp = fopen(pathname, "a");
fprintf(fp, "%s", info.c_str());
fclose(fp);
va_end(ap);
}3.2.3. Usage.hpp
#pragma once
#include <iostream>
void Usage(const std::string &name)
{
std::cout << "Usage:\n " << name << " port" << std::endl;
}3.2.4. HttpServer.hpp
#ifndef _HTTPSERVER_HPP_
#define _HTTPSERVER_HPP_
#include <functional>
#include "Sock.hpp"
#include "Log.hpp"
#include "Date.hpp"
#include "Usage.hpp"
using func_t = std::function<void(int)>;
namespace Xq
{
class HttpServer
{
public:
// 初始化服务器
HttpServer(uint16_t port)
{
// 创建套接字
_sock.Socket();
// 绑定套接字
_sock.Bind("", port);
// 将该套接字设置为监听状态
_sock.Listen();
}
// 服务端需要绑定的服务
void BindHandle(func_t func)
{
_func = func;
}
// 子进程执行的服务 (该服务就是外部绑定的服务)
void ExecuteHandle(int server_sock)
{
_func(server_sock);
}
// 启动服务器
void start(void)
{
while(true)
{
std::string client_ip;
uint16_t client_port = 0;
int server_sock = _sock.Accept(client_ip, &client_port);
// 让子进程执行该客户端请求
if(fork() == 0)
{
// 子进程关闭监听套接字
close(_sock._sock);
// 处理该客户端请求
ExecuteHandle(server_sock);
// 执行完, 关闭该服务套接字
close(server_sock);
// 子进程退出
exit(0);
}
// 父进程不需要该服务套接字, 关闭掉
close(server_sock);
// 同时, 我们显式忽略了SIGCHLD信号
// 避免僵尸问题的产生
// 父进程继续去获取客户端连接
}
}
private:
Sock _sock;
func_t _func;
};
}
#endif3.2.5. HttpServer.cc (看一看 Http 请求格式)
#include <memory>
#include <signal.h>
#include <fstream>
#include "HttpServer.hpp"
#include "Tool.hpp"
#define BUFFER_SIZE 10240
void HttpServerHandle(int sock)
{
// 因为http底层是tcp协议
// 而tcp协议是面向字节流的
// 因此可以使用 recv 接口
char buffer[BUFFER_SIZE] = {0};
// 读取客户端请求
ssize_t real_size = recv(sock, buffer, BUFFER_SIZE - 1, 0);
if(real_size > 0)
{
buffer[real_size] = 0;
// 打印一下 HTTP 请求
std::cout << buffer << "------------------" << std::endl;
}
}
int main(int arg, char** argv)
{
if(arg != 2)
{
Usage(argv[0]);
exit(1);
}
// 显示忽略 SIGCHLD 信号, 避免僵尸问题
signal(SIGCHLD, SIG_IGN);
std::unique_ptr<Xq::HttpServer> server(new Xq::HttpServer(atoi(argv[1])));
// Bind 处理客户端请求的方法
server->BindHandle(HttpServerHandle);
// 启动服务器
server->start();
return 0;
}测试现象如下:


可以看到,上面这个 HTTP 请求是由三部分组成的, 请求行、 请求报头、空行。
GET / HTTP/1.1 就是一个请求行。
- GET代表请求方法, "/" 代表资源路径,具体就是 Web根目录, HTTP/1.1 服务端的HTTP版本;
- 当 HTTP 请求中未显式具体的资源路径时,默认的资源路径就是 "/",即Web根目录;
- 注意,当资源路径为 "/" 时,并不是获取 Web 根目录下的所有资源;
- 一般的服务端都有自己的默认首页,比如通常所使用的 index.html 或 index.php 等默认首页文件;
- 当只有 "/" 时, 服务端就会将默认首页的内容返回给客户端。
3.2.6. HttpServer.cc (添加 HTTP 响应数据)
现在,我们可以收到 HTTP 请求,也看出 HTTP 请求的格式。
那么我们可以在此基础之上, 构建一个简单的 HTTP 响应。
实现如下:
void HttpServerHandle(int sock)
{
// 因为http底层是tcp协议
// 而tcp协议是面向字节流的
// 因此可以使用 recv 接口
char buffer[BUFFER_SIZE] = {0};
ssize_t real_size = recv(sock, buffer, BUFFER_SIZE - 1, 0);
if(real_size > 0)
{
buffer[real_size] = 0;
// 打印一下 HTTP 请求
std::cout << buffer << "------------------" << std::endl;
}
// 状态行(服务器端HTTP版本 状态码 状态码描述符\r\n)
std::string HttpResponse = "HTTP/1.1 200 OK\r\n";
// 暂时不添加响应报头
// 添加空行
HttpResponse += "\r\n";
// 响应正文 (简单的构建一个html)
HttpResponse += "<html><h3> hello world! </h3></html>";
// 发送给客户端
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}
int main(int arg, char** argv)
{
// 省略
}
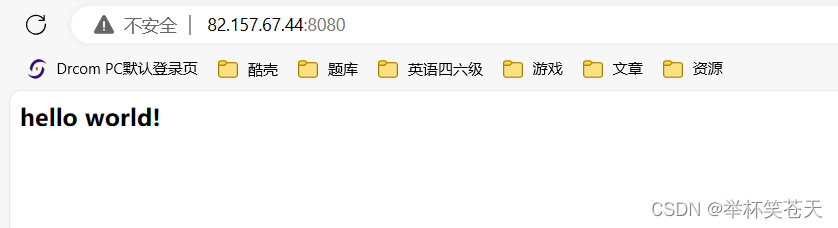
上面的 HTTP 响应很简单, 只有状态行,响应报头 (省略,有的浏览器可以自动识别),空行、响应正文。
因为 HTTP 的底层是 TCP,而TCP是面向字节流的, 故我们可以直接将 HTTP 响应作为字符串发送给客户端。
服务端继续跑起来,测试如下:
3.3. 通过该 demo 逐步分析过程,理解细节
有了上面的过程,我们对 HTTP请求和响应有了一定的理解,但我们还要强调两个问题,URL 和 Web根目录。
首先,我们在浏览器输入:

得到的现象是:

然后,我们在浏览器输入:

得到的现象是:

经过对比,我们知道,在浏览器输入的 URL 可以显示声明要访问服务端的什么资源,可是服务端怎么知道你要访问什么资源呢? 是不是需要通过 HTTP 请求中的资源路径来确定。
因此,服务端需要获得 HTTP 请求中的资源路径 (也就是解析 HTTP 请求),根据该路径找到特定资源,因为一般的服务端都是 Linux , 故这里的资源就是文件,因此,服务端需要打开该文件,读取文件内容,并将内容返回给客户端。
那么我们也就可以理解域名后的第一个 "/" 为什么被称之为 Web根目录了, 实际上,这个 "/" 是可以被用户自定义路径的, 其代表着服务端资源的起始路径。
例如上面的 URL 是 /a/b/c/d/e.html,那么这个路径表示服务端自定义的资源路径下的 a 目录下的 b 目录下的 c 目录下的 d 目录下的 e.html 文件。服务端会根据这个路径找到对应的文件(e.html),读取文件内容,并将内容返回给客户端作为响应。
那么我们现在至少知道,当 客户端发起HTTP请求时, 服务单获得该HTTP请求后,需要对其进行解析, 获得相关属性,例如服务端需要获得 HTTP请求中的资源路径,根据该路径,访问服务端下的特定资源。
而HTTP底层使用的是TCP, TCP是面向字节流的, 换言之, 服务端要对HTTP请求进行解析,本质上也就是需要做字符串处理,获得相关字段。
因此,有了上面的需求,我们可以实现一个工具模块 Tool.hpp,用于解析字符串。
3.3.1. Tool.hpp
这个模块主要有一个成员函数,CutString,用来将一个字符串,以特定的分割字符串,将原串分割为不同的子串,并将不同的子串以输出型参数返回给上层。
#ifndef _UTIL_HPP_
#define _UTIL_HPP_
#include <iostream>
#include <string>
#include <vector>
namespace Xq
{
class Tool
{
public:
static void CutString(const std::string& src, const std::string& sep, std::vector<std::string>* out)
{
size_t start = 0;
size_t pos = 0;
while(pos != std::string::npos && start < src.size() - 1)
{
pos = src.find(sep, start);
if(pos != std::string::npos)
{
out->push_back(src.substr(start, pos - start));
start = pos;
start += sep.size();
}
}
if (start < src.size())
{
out->push_back(src.substr(start));
}
}
};
}
#endif依据这个模块,服务端就可以解析 HTTP 请求,从而获得相关属性,比如 HTTP 请求中的资源路径。
3.3.2. HttpServer.cc (获得HTTP请求的资源路径)
#include <memory>
#include <signal.h>
#include <fstream>
#include "HttpServer.hpp"
#include "Tool.hpp"
#define BUFFER_SIZE 10240
// 服务器资源的起始目录
#define START_PATH "./wwwroot"
void HttpServerHandle(int sock)
{
// 因为http底层是tcp协议
// 而tcp协议是面向字节流的
// 因此可以使用 recv 接口
char buffer[BUFFER_SIZE] = {0};
ssize_t real_size = recv(sock, buffer, BUFFER_SIZE - 1, 0);
if(real_size > 0)
{
buffer[real_size] = 0;
// 打印一下 HTTP 请求
std::cout << buffer << "------------------" << std::endl;
}
// 这个vector用于存储HTTP请求中的每一行信息
std::vector<std::string> v_line;
Xq::Tool::CutString(buffer, "\r\n", &v_line);
// 因为我们需要 HTTP 请求中的 资源路径
// 故我们实际上只需要 HTTP 请求的第一行信息 (v_line[0])
// 即请求行, 而请求行中的第二个字段就是资源路径
// 这个vector用于存储请求行中的每一个字段
std::vector<std::string> v_block;
Xq::Tool::CutString(v_line[0], " ", &v_block);
for(const auto& vit : v_block)
{
std::cout << vit << std::endl;
}
// 而此时的v_block[1]就是HTTP请求中的资源路径
std::string resource_path = v_block[1];
std::cout << "resource_path: " << resource_path << std::endl;
// 状态行(服务器端HTTP版本 状态码 状态码描述符\r\n)
std::string HttpResponse = "HTTP/1.1 200 OK\r\n";
// 暂时不添加响应报头
// 添加空行
HttpResponse += "\r\n";
// 响应正文 (简单的构建一个html)
HttpResponse += "<html><h3> hello world! </h3></html>";
// 发送给客户端
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}
int main(int arg, char** argv)
{
if(arg != 2)
{
Usage(argv[0]);
exit(1);
}
// 显示忽略 SIGCHLD 信号, 避免僵尸问题
signal(SIGCHLD, SIG_IGN);
std::unique_ptr<Xq::HttpServer> server(new Xq::HttpServer(atoi(argv[1])));
// Bind 处理客户端请求的方法
server->BindHandle(HttpServerHandle);
// 启动服务器
server->start();
return 0;
}现象如下:

一旦服务端解析 HTTP 请求获得了客户端请求的资源路径,接下来就是根据这个资源路径来处理请求。处理方式主要分为两种情况:
- 如果服务端没有这个资源,即无法找到客户端请求的资源,服务端需要构建一个对应的 HTTP 响应,通常是状态码为 404(Not Found),表示未找到请求的资源。这样客户端就会收到一个告知资源不存在的响应。
- 如果服务端找到了客户端请求的资源,服务端就需要打开这个资源,并读取它的内容。然后将读取到的内容作为响应的实体主体部分,返回给客户端。客户端在收到响应后就能够获取到请求的具体资源内容。
因此,在服务端处理 HTTP 请求的过程中,根据请求的资源路径不同,服务端会针对不同情况做出相应的处理,包括构建响应、读取资源内容并响应等操作,以便实现正确的请求处理和响应。
除此之外,在 Web 服务器中,通常会设置默认首页,也称为默认文档或主页,用来作为根目录下没有指定具体资源路径时的默认返回页面。
当客户端发起一个 HTTP 请求时:
- 如果资源路径为 "/"(Web根目录),这时服务端会将默认首页的内容返回给客户端,让客户端能够浏览网站的主要内容。这样可以提供用户友好的访问体验,并展示网站的内容。
- 如果 HTTP 请求中的资源路径不是Web根目录("/"),而是具体的资源路径,服务端会按照上面提到的处理方式来定位、读取和返回相应的资源内容,以响应客户端的请求。
因此,服务端在处理 HTTP 请求时,会根据请求中的资源路径的不同情况采取相应的处理措施:当资源路径是根目录时返回默认首页,当资源路径为具体文件或其他路径时定位并返回对应的资源内容。
有了上面的理解后,我们就可以实现下面的代码了:
#include <memory>
#include <signal.h>
#include <fstream>
#include "HttpServer.hpp"
#include "Tool.hpp"
#define BUFFER_SIZE 10240
// 服务器资源的起始目录
#define START_PATH "./wwwroot"
void HttpServerHandle(int sock)
{
// 因为http底层是tcp协议
// 而tcp协议是面向字节流的
// 因此可以使用 recv 接口
char buffer[BUFFER_SIZE] = {0};
ssize_t real_size = recv(sock, buffer, BUFFER_SIZE - 1, 0);
if(real_size > 0)
{
buffer[real_size] = 0;
// 打印一下 HTTP 请求
std::cout << buffer << "------------------" << std::endl;
}
// 这个vector用于存储HTTP请求中的每一行信息
std::vector<std::string> v_line;
Xq::Tool::CutString(buffer, "\r\n", &v_line);
// 因为我们需要 HTTP 请求中的 资源路径
// 故我们实际上只需要HTTP 请求的第一行信息
// 即请求行, 而请求行中的第二个字段就是资源路径
// 这个vector用于存储请求行中的每一个字段
std::vector<std::string> v_block;
Xq::Tool::CutString(v_line[0], " ", &v_block);
for(const auto& vit : v_block)
{
std::cout << vit << std::endl;
}
// 而此时的v_block[1]就是HTTP请求中的资源路径
std::string resource_path = v_block[1];
std::cout << "resource_path: " << resource_path << std::endl;
// 服务器要访问的目标路径
std::string Target_path;
Target_path = START_PATH;
Target_path += resource_path;
// 如果该路径是Web根目录 ("/"), 那么返回默认首页
if(resource_path == "/")
{
Target_path += "index.html";
}
// std::cout << "Target_path: " << Target_path << std::endl;
// 目标路径已经准备就绪, 现在就需要打开该文件
std::ifstream in(Target_path.c_str());
// HTTP 响应
std::string HttpResponse;
// 如果该文件不存在, 那么HTTP响应中的状态码就是404
if(!in.is_open())
{
// 状态行(服务器端HTTP版本 状态码 状态码描述符\r\n)
HttpResponse = "HTTP/1.1 404 Not Found\r\n";
// 空行
HttpResponse += "\r\n";
// 错误信息文件的路径
std::string error_path = START_PATH;
std::string error_info;
error_path += "/error.html";
// 将错误信息添加到HTTP响应正文中
std::ifstream error(error_path);
if(error.is_open())
{
while(getline(error, error_info))
{
HttpResponse += error_info;
}
}
error.close();
// done
}
else
{
// 状态行
HttpResponse = "HTTP/1.1 200 OK\r\n";
// 空行
HttpResponse += "\r\n";
// 有效载荷
std::string content;
while(std::getline(in, content))
{
HttpResponse += content;
}
// done
}
// 读取文件完毕后, 关闭文件
in.close();
// 发送给客户端
send(sock, HttpResponse.c_str(), HttpResponse.size(), 0);
}
int main(int arg, char** argv)
{
// 忽略...
}可以看到,我是定义了一个服务端的资源起始路径,也就是 wwwroot;
如下图所示:

在这里演示一下 index.html 和 error.html;
3.3.3. index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width">
<title> 咸蛋超人的网站 </title>
</head>
<body>
<html><p> ------------------ 北国风光, 千里冰封, 万里雪飘。 --------------------- </p><html>
<html><p> ------------------ 望长城内外, 惟余莽莽; 大河上下, 顿失滔滔。 --------------------- </p><html>
<html><p> ------------------ 山舞银蛇, 原驰蜡象, 欲与天公试比高。 --------------------- </p><html>
<html><p> ------------------ 须晴日, 看红装素裹, 分外妖娆。 --------------------- </p><html>
<html><p> ------------------ 江山如此多娇, 引无数英雄竞折腰。 --------------------- </p><html>
<html><p> ------------------ 惜秦皇汉武, 略输文采; 唐宗宋祖, 稍逊风骚。 --------------------- </p><html>
<html><p> ------------------ 一代天骄, 成吉思汗, 只识弯弓射大雕。 --------------------- </p><html>
<html><p> ------------------ 俱往矣, 数风流人物, 还看今朝。 --------------------- </p><html>
</body>
</html>
现象如下:

3.3.4. error.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width">
<title> 咸蛋超人的网站 </title>
</head>
<body>
<h1> 404 --- Not Found </h1>
</body>
</html>现象如下:

3.3.5. 简单总结
- HTTP 协议本质上是一个文本协议,因为它采用文本格式来进行请求和响应的传输和通信,同时从 HTTP 请求和响应的结构也可以看出,它们都是由文本数据组成的,各种属性和信息也以文本形式呈现;
- 域名后的第一个 "/" 我们称之为 Web 根目录, 这个目录一般是由服务端自定义的,它代表着服务端资源的起始地址,是客户端访问服务端资源的入口路径;
- 未来,服务端的各种资源都可以放在这个路径 (Web根目录) 下,并通过特定的 URL 来访问这些资源。
- 一般服务端都要有自己的默认首页,如果 HTTP 请求的资源路径是 "/",那么服务端将默认首页的内容返回给客户端;
- URL(统一资源定位符)代表客户端想要访问服务器上的哪个资源,服务端通过URL访问特定资源,并将内容返回给客户端。
至此,关于HTTP协议上的内容就此结束,至于更多细节,我们在 HTTP 协议下详述。
























![[音视频学习笔记]七、自制音视频播放器Part2 - VS + Qt +FFmpeg 写一个简单的视频播放器](https://img-blog.csdn.net/20140508135954718?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbGVpeGlhb2h1YTEwMjA=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)