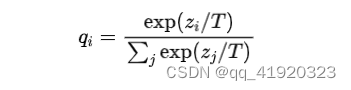摘要
知识蒸馏最初是为了利用单个教师的额外监督来训练学生模型。为了提高学生的表现,最近的一些变体试图利用来自多个教师的不同知识来源。然而,现有的研究方法主要是通过对多个教师预测进行平均或使用其他无标签策略将它们组合在一起来整个不同来源的知识,这可能会在存在低质量教师预测的情况下误导学生。为了解决这个问题,我们提出了自信感知的多教师知识蒸馏(CA-MKD),他在ground truth标签的帮助下自适应为每个教师预测分配样本置信度,那些接近一个热点标签的教师预测分配了较大的权重。此外,CA-MKD在中间层加入了特征,以稳定知识转移过程。
1、介绍
由于大众的智慧超过了最聪明的个人的智慧,一些多教师知识蒸馏(MKD)方法被提出并被证明也是有益的。基本上,他们将多名教师的预测与固定权重分配或其他无标签方案相结合,例如基于优化问题或熵准则计算权重等。然而,固定权重并不能区分高质量教师和低质量教师,其他方案可能会在低质量教师预测存在的情况下误导学生。图1提供了关于这个问题的直观说明。其中,一旦大多数教师的预测有偏差,使用平均加权策略训练的学生可能会偏离正确的方向。
幸运的是,我们实际上有基础ground-truth标签,可以量化我们对教师预测的信息,然后过滤掉低质量的预测,以更好的训练学生。为此,我们提出了自信感知多教师知识蒸馏(CA-MKD),通过考虑教师的预测置信度进行自适应知识整合来学习样本加权。置信度是基于预测分布和ground truth之间的交叉熵损失获得的。与以前的无标签加权策略相比,我们的方法使学生能够从一个相对正确的方向学习。
请注意,我们的信息感知机制不仅能够根据样本置信度自适应地对不同的教师预测进行加权,而且还可以扩展到中间层的学生-教师特征对。在我们生成的灵活有效的权重的帮助下,我们可以避免那些在知识转移过程中占主导地位的糟糕的教师预测,并在8种教师架构组合上显著提高学生的表现。
相关工作
知识蒸馏。Vanilla蒸馏旨在将知识从复杂网络(教师)转移到简单网络(学生),其软化输出之间的KL散度最小化。后来提出模仿中间层的教师表示,以探索更多的知识形式[5,6,14,15,7]。与这些需要对教师进行预训练的方法相比,有些作品同时培训多个学生,并激励他们相互学习。我们的技术不同于这些在线KD方法,因为我们试图从多个预先训练的教师中提取知识。
多教师知识蒸馏。MKD不是使用单一的教师,而是通过整合来自多个教师的预测来提高蒸馏的有效性。提出了一堆方法,如简单地为不同的教师分配平均或其他固定的权重,以及基于熵、潜在因素或梯度空间中的多目标优化来计算权重。然而,这些无标签策略可能会在低质量预测的情况下误导学生训练。例如,基于熵的策略将更倾向于盲目信任的模型,因为它倾向于低方差的预测;基于优化的策略倾向于多数人的意见,容易被噪声数据误导。相比之下,我们的CA-MKD基于ground truth量化了教师的预测,并进一步提高了学生的表现。

方法
把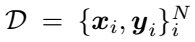 作为标记训练集。N是样本数量,K是教师数量。F是最后一个网络块的输出。我们表示
作为标记训练集。N是样本数量,K是教师数量。F是最后一个网络块的输出。我们表示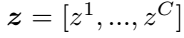 为logits的输出,其中C为类别数。最终模型预测由一个softmax函数与温度T得到。在下面的部分中,我们将详细介绍CA-MKD。
为logits的输出,其中C为类别数。最终模型预测由一个softmax函数与温度T得到。在下面的部分中,我们将详细介绍CA-MKD。
教师预测的损失
为了有效地整合多个教师的预测分布,我们通过计算教师预测和ground truth之间的交叉熵损失来分配不同的权重,这反映了他们的样本置信度。
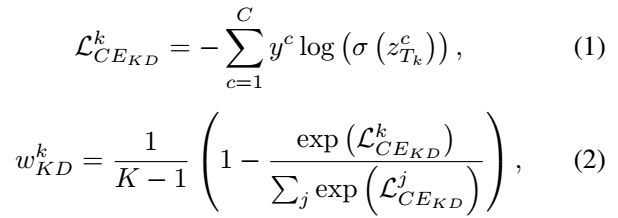
 表示第k个教师。
表示第k个教师。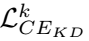 越小,对应的
越小,对应的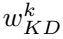 就越大。教师的总体预测是汇总计算出的权重:
就越大。教师的总体预测是汇总计算出的权重:
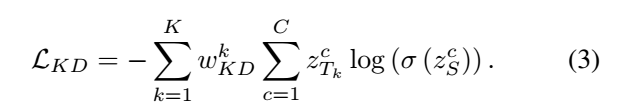
根据上述公式,预测更接近ground truth标签的教师将被赋予更大的权重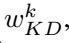 ,因为它有足够的信息做出准确的判断,从而进行正确的指导。
,因为它有足够的信息做出准确的判断,从而进行正确的指导。
中级教师特征的缺失
除了KD Loss外,受FitNet的启发,我们任务中间层也有利于学习结构知识,因此将我们的方法扩展到中间层以挖掘更多的信息。中间特征匹配的计算方法如下:
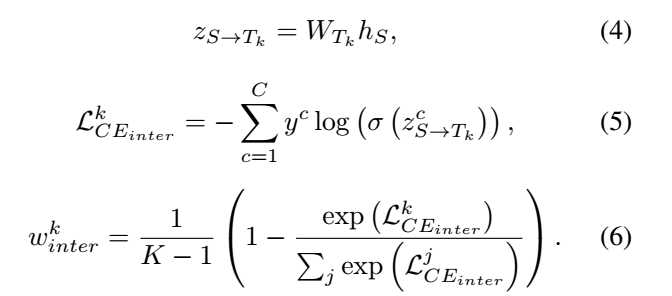
其中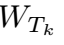 是第k位教师的最终分类器,
是第k位教师的最终分类器,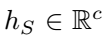 是最后一个学生特征向量,即
是最后一个学生特征向量,即 。
。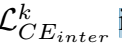 是通过hs传递到每个教师分类器得到的。
是通过hs传递到每个教师分类器得到的。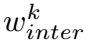 的计算方法和
的计算方法和 的计算方法相似。
的计算方法相似。
为了确定知识转移过程,我们将学生设计成更专注于模仿具有相似特征空间的教师, 确实可以作为一个相似度量,表示师生分类器在学生特征空间中的可判别性。
确实可以作为一个相似度量,表示师生分类器在学生特征空间中的可判别性。
消融实验也表明,在中间层,使用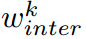 而不是
而不是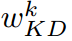 进行知识聚合更为有效。
进行知识聚合更为有效。
L i n t e r = ∑ k = 1 K w i n t e r k ∣ ∣ F T k − r ( F S ) ∣ ∣ 2 2 L_inter = \sum_{k=1}^K w_{inter} ^k ||F_{T_k} - r(F_S)||_2 ^2 Linter=k=1∑Kwinterk∣∣FTk−r(FS)∣∣22
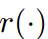 是对齐学生和教师特征维度的函数,l2损失函数作为中间特征的距离度量。最后,将特征对之间的总体训练按
是对齐学生和教师特征维度的函数,l2损失函数作为中间特征的距离度量。最后,将特征对之间的总体训练按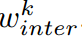 间隔进行汇总。
间隔进行汇总。
总损失
除了上述的两个损失,还计算了具有ground trutj的正则交叉熵损失
L C E = − ∑ c = 1 C y c l o g ( σ ( Z S c ) ) L_{CE} = -\sum_{c=1}^C y^c log(\sigma (Z_S ^c)) LCE=−c=1∑Cyclog(σ(ZSc))
CA-MKD的总损失:
L = L C E + α L K D + β L i n t e r L = L_{CE} + \alpha L_{KD} + \beta L_{inter} L=LCE+αLKD+βLinter