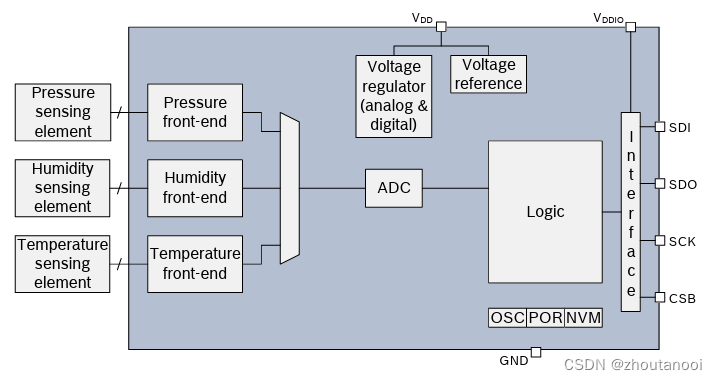
高级DBA带你学习海量数据的Mysql数据库实现按日期增量备份实战案例全网唯一
一、背景描述
日常生产环境的MySql数据库生产数据,通常我们都是以夜间全量备份机制处理的!但是,如果数据库的数据量越来越大,导致MySql数据库的全量备份整个夜间8小时无法完成,或者就算能备份完,恢复全量数据需要几天时间,如果生产事故发生数据丢失,马上恢复数据的时间过长,这个也是不能满足实际需求的。并且每天全量备份也会消耗很大的磁盘存储空间,用于存储这些庞大的备份文件!
所以笔者引入增量备份的算法及其具体方法,来解决上述的海量数据库备份的技术瓶颈!!
二、增量算法描述
每个重要的数据库表,需要有一个时间字段,用于记录该条数据是否被修改过,如果修改过,则自动更新成当前时间,这个字段用于分离出增量数据!
`GXSJ` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
先全量备份,再每天增量局部备份!每天只备份当天变化的发生数据!
举例:
今天2024年3月18日备份全量数据
2024年3月19日 备份2024年3月18日只2024年3月19日中途变化的数据,更新时间大于2024年3月18日的并且小于当前时间的变化数据!
2024年3月20日 备份2024年3月18日只2024年3月20日中途变化的数据,更新时间大于2024年3月18日的并且小于当前时间的变化数据!
2024年3月21日 备份2024年3月18日只2024年3月21日中途变化的数据,更新时间大于2024年3月18日的并且小于当前时间的变化数据!
2024年3月22日 备份2024年3月18日只2024年3月22日中途变化的数据,更新时间大于2024年3月18日的并且小于当前时间的变化数据!
依次类推,只保留就近30天的备份!
这种算法可以恢复到期间的任何1天的数据!
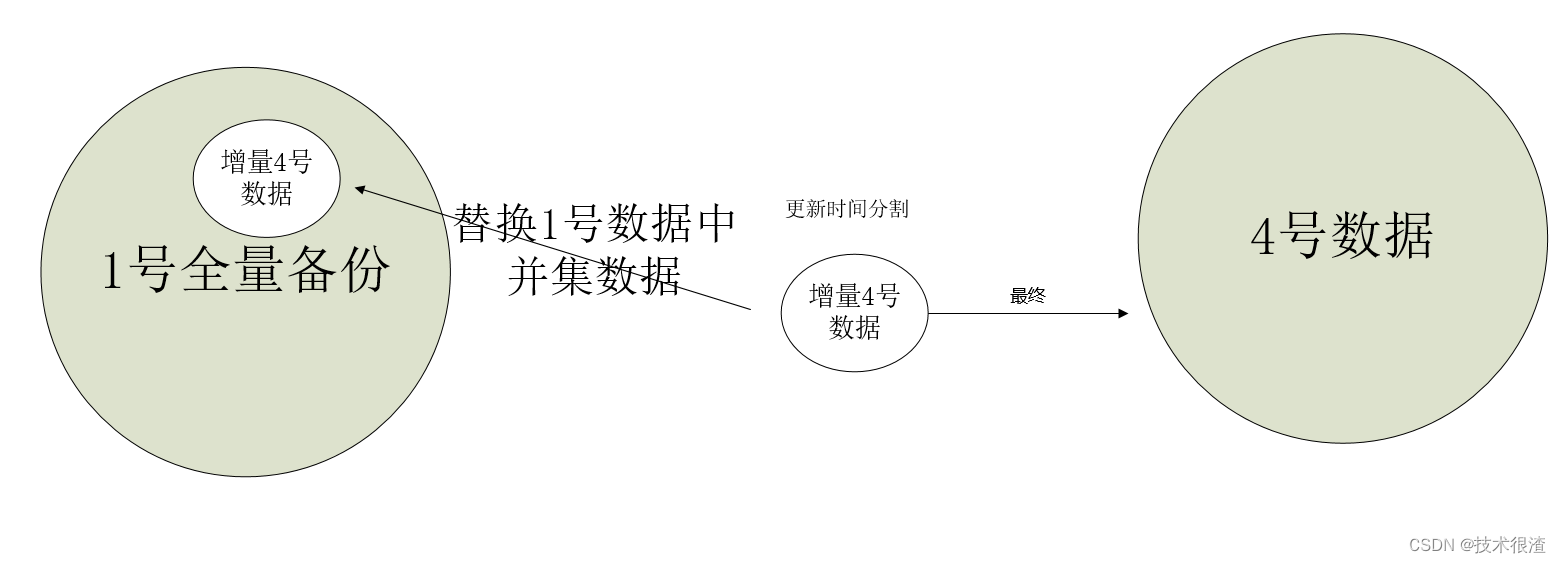
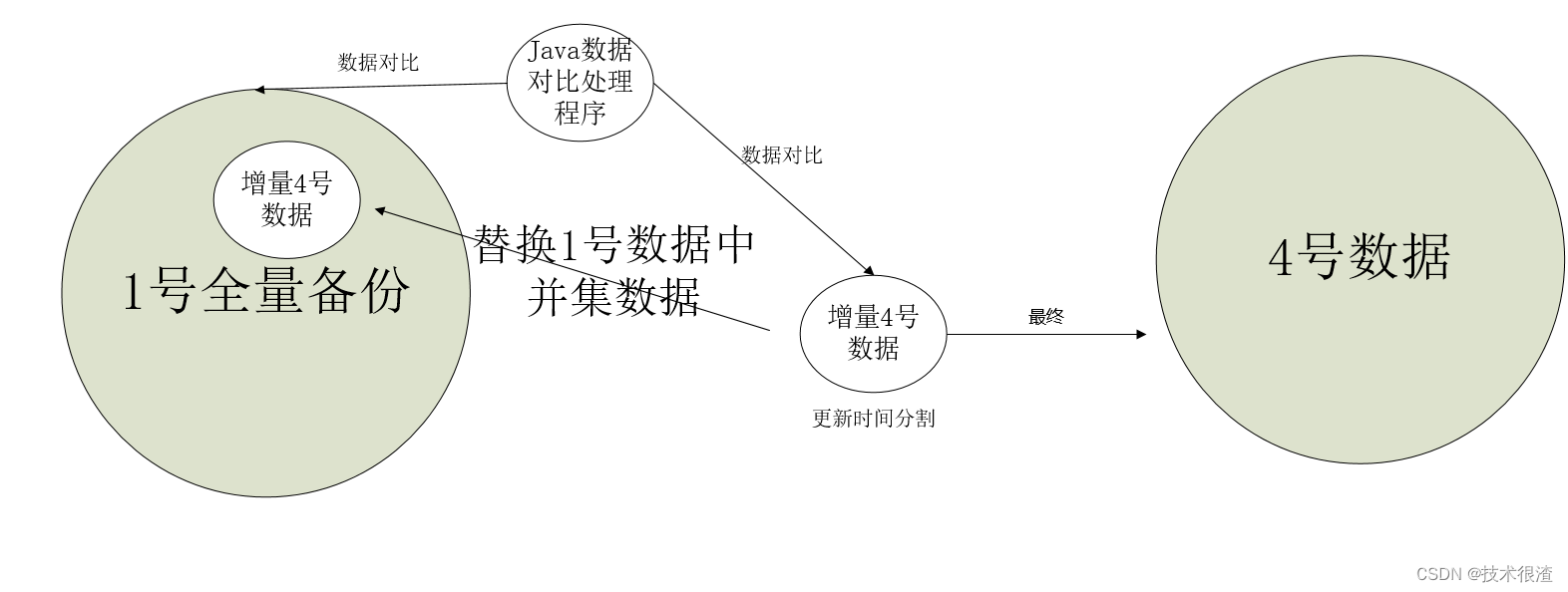
如果想恢复2024年3月22日时间的数据,则将2024年3月22日的备份恢复到一个数据库B!源数据库是A。
通过数据对比(主键)分离出数据库A中数据库B发生变化的增量数据将其删除,然后再将数据库B的数据重新插入到数据库A!将源数据库中,这端时间发生变化的数据删除,再插入最新的数据替代!

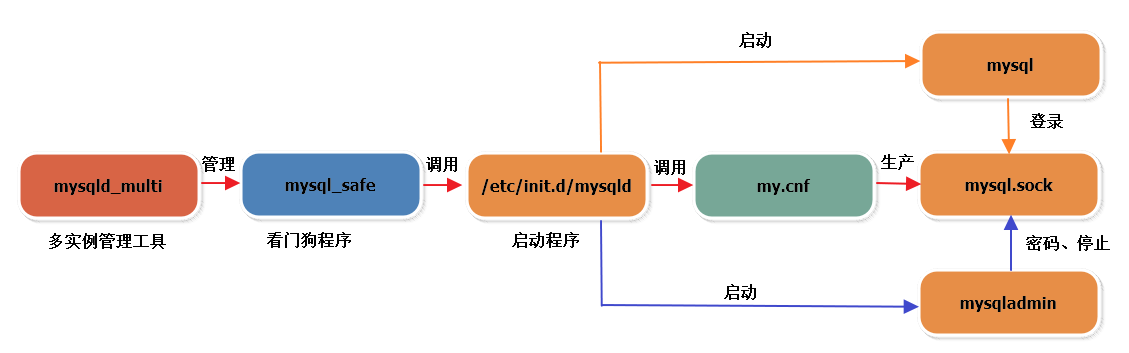
三、Linux的shell脚本案例
(一)mysql增加条件导出案例
本实际案例是:每个月1号全量备份,增量备份只保留1个月!每个月1号一次全量,其余增量!
此处用到mysql导出表并且加时间分割条件的核心命令
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen --where="GXSJ >= '2024-03-17'" --tables table_1 > "/home/db_increment_bak/$now_date/table_1_2024-03-17.sql"
这个语句是导出nasen数据库的table_1的更新时间大于2024-03-17的增量数据(昨天到现在的变化的数据),导出insert语句,包括建表语句!
(二)shell脚本时间案例
#!/bin/bash
if [ "$(date +%d)" -eq "01" ]; then
# 删除 db_full_bak 文件夹及其内容
rm -rf "/home/db_full_bak/"
echo "已删除 /home/db_full_bak/ 文件夹及其内容"
rm -rf "/home/db_increment_bak/"
echo "已删除 /home/db_increment_bak/ 文件夹及其内容"
fi
if [ -d "/home/db_full_bak/" ]; then
echo "db_full_bak 文件夹已经存在!"
else
mkdir "/home/db_full_bak/"
fi
if [ -d "/home/db_increment_bak/" ]; then
echo "db_increment_bak 文件夹已经存在!"
else
mkdir "/home/db_increment_bak/"
fi
# 使用指定的日期格式
now_date="$(date +%Y-%m-%d)"
echo "当前日期:$now_date"
if [ -f "/home/db_full_bak/*.sql" ]; then
echo "全量还未备份!需要执行全量备份!"
else
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen > /home/db_full_bak/${now_date}.sql
fi
# 读取文件名并记
file_name="$(basename "$(ls -1 /home/db_full_bak/*.sql)")"
file_name_time="${file_name%.*}"
echo "文件名:$file_name_time"
# 在 /home/db_increment_bak/ 基础上用 now_date 变量创建一层目录
mkdir -p "/home/db_increment_bak/$now_date"
if [ -d "/home/db_increment_bak/$now_date" ]; then
echo "目录已存在,无需创建。"
else
echo "创建目录 /home/db_increment_bak/$now_date 成功。"
fi
# 执行增量备份
echo "全量备份已经执行过,执行增量备份!"
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen --where="GXSJ >= '$file_name_time'" --tables table_1 > "/home/db_increment_bak/$now_date/table_1_${now_date}.sql"
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen --where="GXSJ >= '$file_name_time'" --tables table_2 > "/home/db_increment_bak/$now_date/table_2_${now_date}.sql"
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen --where="GXSJ >= '$file_name_time'" --tables table_3 > "/home/db_increment_bak/$now_date/table_3_${now_date}.sql"
mysqldump -unasen -pnasen -h192.168.1.225 --databases nasen --where="GXSJ >= '$file_name_time'" --tables table_4 > "/home/db_increment_bak/$now_date/table_4_${now_date}.sql"
(三)代码详细讲解
这是一个 Bash 脚本,它执行了一系列的操作,包括删除文件夹、创建文件夹、执行数据库备份等。下面是对脚本逻辑的逐步解释:
- 检查日期:
- 首先,脚本检查当前日期是否为 1 号。如果是,则删除
/home/db_full_bak/和/home/db_increment_bak/文件夹及其内容。
- 首先,脚本检查当前日期是否为 1 号。如果是,则删除
- 检查文件夹是否存在:
- 接下来,它检查
/home/db_full_bak/和/home/db_increment_bak/文件夹是否存在。 - 如果存在,相应地输出消息。
- 如果不存在,则创建这些文件夹。
- 接下来,它检查
- 获取当前日期:
- 使用
date +%Y-%m-%d格式获取当前日期,并将其存储在now_date变量中。
- 使用
- 检查全量备份:
- 检查是否存在
/home/db_full_bak/*.sql文件。 - 如果不存在,执行全量备份并将其保存到
/home/db_full_bak/${now_date}.sql。
- 检查是否存在
- 处理文件名:
- 获取文件名的基本部分(不带扩展名),并将其存储在
file_name_time变量中。
- 获取文件名的基本部分(不带扩展名),并将其存储在
- 创建增量备份目录:
- 在
/home/db_increment_bak/下创建一个以当前日期命名的新目录。 - 如果目录已存在,输出相应消息。
- 在
- 执行增量备份:
- 执行增量备份,将指定表的数据备份到新创建的目录中,文件名包含表名和当前日期。
总的来说,这个脚本的目的是根据日期执行数据库的全量或增量备份,并管理相关的文件和文件夹。它根据不同的条件执行不同的操作,以确保备份的顺利进行。
四、总结
此增量算法备份,每个月1号全量,后30天增量备份期间发生变化的数据!这种算法可以恢复到任意一天的数据,确保数据的安全,并且占用磁盘空间较每天全量小了不少,并且局部恢复某一天的数据的恢复时间大大减小!因为每天增量数据是有限的!
增量恢复算法还需要按表主键数据对比删除的源数据库数据处理操作,数据对比逻辑可以开发JAVA小程序来实现!
想真正实现海量数据库增量算法备份,不单独需要熟悉数据库,同样也得熟悉增量算法,当然也得熟悉java或者py小工具开发,还得熟悉撰写linux的shell脚本,将整个知识栈串起来才能真正实现!需要我们工程师的技术广度更宽!
当然对于海量数据项目通常提前都以业务分库分库划分,或者以时间划分!比如:交易记录、手机账单!
笔者这个案例是那种单个库数据非常庞大的场景!并且不容易做分库的实际生产项目!
笔者简介
国内某一线知名软件公司企业认证在职员工:任JAVA高级研发工程师,大数据领域专家,数据库领域专家兼任高级DBA!10年软件开发经验!现任国内某大型软件公司大数据研发工程师、MySQL数据库DBA,软件架构师。直接参与设计国家级亿级别大数据项目!并维护真实企业级生产数据库300余个!紧急处理数据库生产事故上百起,挽回数据丢失所造成的灾难损失不计其数!并为某国家级大数据系统的技术方案(国家知识产权局颁布)专利权的第一专利发明人!