本篇文章介绍K-means语义分割来估计 2000 年至 2023 年咸海水面的变化
让我们先看一下本教程中将使用的数据。这是同一地区的两张 RGB 图像,间隔 23 年,但很明显地表特性和大气条件(云、气溶胶等)不同。这就是为什么我决定训练两个独立的 k-Means 模型,每个图像一个。
首先,我们导入必要的库并将数据上传
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('MOD_01.jpg')
img2 = mpimg.imread('MOD_24.jpg')可以看到图像覆盖的区域相当大,所以我建议放大一点:
img = img[140:600,110:500,:]
img2 = img2[140:600,110:500,:]
fig, ax = plt.subplots(ncols=2, figsize=(16,9))
ax[0].imshow(img)
ax[1].imshow(img2)
for i in range(2):
ax[i].set_facecolor('black')
ax[i].set_xticks([])
ax[i].set_yticks([])
ax[0].set_title('2000-08-01', fontsize=26)
ax[1].set_title('2023-08-01', fontsize=26)
plt.show()
在 ML 阶段之前的最后一步,让我们将图像转换为pandas数据帧(每个图像通道一列)。我这样做是为了我的解释的可见性。如果你想对其进行优化,最好使用numpy数组。
df = pd.DataFrame({ 'R' : img[:,:, 0 ].flatten(), 'G' : img[:,:, 1 ].flatten(), 'B' :img[:,: , 2 ].flatten()})
df2 = pd.DataFrame({ 'R' : img2[:,:, 0 ].flatten(), 'G' : img2[:,:, 1 ].flatten(), 'B' :img2[:,:, 2 ].flatten()})k-均值
那么该算法背后的想法是什么呢?
想象一下,您使用两个标准来判断食物的味道:甜度和价格。记住这一点,我将为您提供一组可能的饮食选择:

我敢打赌你的大脑已经把这些选项分成了三类:水果、饮料和面包。基本上,您无意识地对二维数据进行了聚类,这些数据由一对值(甜度;价格)定义。
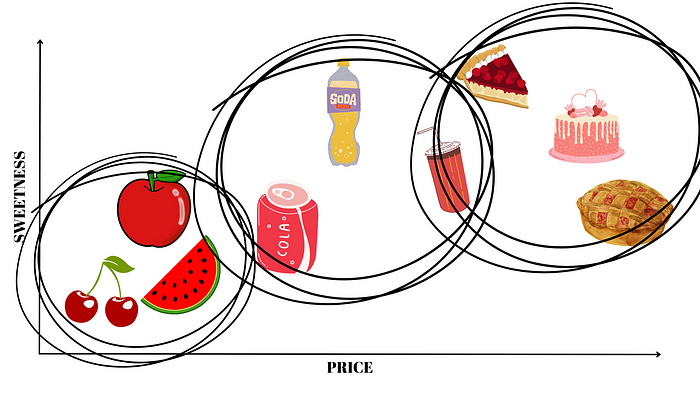
在k-Means的情况下,算法的目标非常相似 - 在 n 维空间中找到预设数量的簇k(例如,除了甜度和价格之外,您还想考虑营养、健康、存在感)冰箱中食物的数量,在本例中,n = 5)。