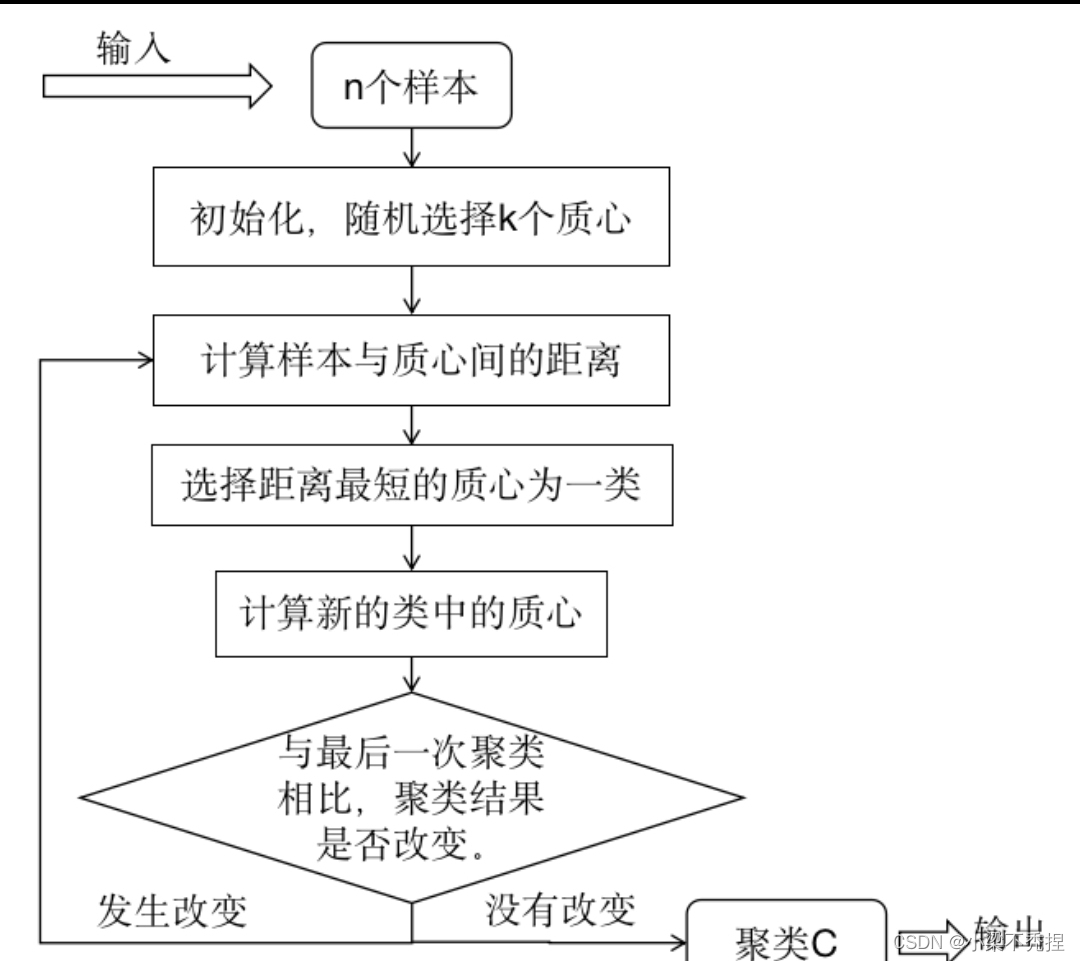
以下是一个使用Sklearn库实现K-均值聚类算法的简单代码示例。K-均值算法是一种迭代算法,用于将数据集分为K个簇,使得每个簇的内部平方误差最小。
# 导入必要的库
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import numpy as np
# 创建样本数据
# X是一个包含特征的二维数组
# 这里我们随机生成数据
np.random.seed(0)
X = np.random.rand(100, 2) # 100个样本,每个样本有2个特征
# 创建KMeans聚类模型实例
# 你可以根据需要调整n_clusters参数,即簇的数量
kmeans = KMeans(n_clusters=3, random_state=42)
# 训练模型
kmeans.fit(X)
# 预测聚类结果
labels = kmeans.predict(X)
# 计算并打印轮廓系数,评估聚类效果
silhouette = silhouette_score(X, labels)
print(f"轮廓系数为: {silhouette}")
# 打印聚类中心
print("聚类中心:", kmeans.cluster_centers_)
# 打印每个样本的预测标签
print("预测标签:", labels)
在上面的代码中,我们首先生成了一些随机数据作为样例,然后创建了一个KMeans聚类模型,并使用数据来拟合模型。在模型训练之后,我们使用轮廓系数来评估聚类的质量,轮廓系数取值范围在-1到1之间,值越大表示聚类效果越好。我们还打印出了聚类中心和每个样本的预测标签,以便于理解聚类结果。
请注意,K-均值算法对初始中心的选择敏感,可能会导致不同的运行结果。为了获得更稳定的结果,通常建议在多次运行中使用不同的初始中心,并选择具有最高轮廓系数的聚类结果。