- 实验目的与要求
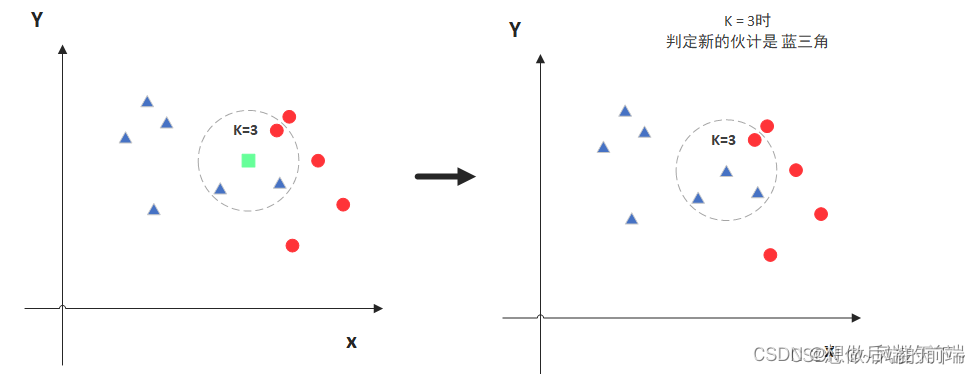
- 掌握基于 K-近邻分类算法的编程方法
- 通过编程理解 K-近邻分类算法和该算法的基本步骤
- 实验器材
- 硬件:PC 机(参与实验的学生每人一台)
- 软件环境:Python3.7 + Pycharm
- 实验内容
- 使用 sklearn 库中的 neighbors 模块实现 K-近邻算法,并对二手房样本所
属类别进行预测,程序流程为:
(1) 导入 sklearn 库中的 K-近邻算法模块(KNeighborsClassifier),数据集分割模块(train_test_split)以及机器学习准确率评估模块(metrics)
(2) 读取数据,并分割成特征属性集和类别集
(3) 将数据集分割成训练集和测试集
(4) 构建模型
(5) 利用循环语句,k 值取 1-8 分别训练模型以确定最优 k 值
(6) 使用最优 k 值训练模型并对新样本[7,27]和[2,4]的类别进行预测
(7) 使用测试集对模型进行测试
(8) 预测新样本类别
(9) 绘制分类边界图
- 数据集下载
本实验的数据集可以点击此处去下载
- 代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
X1,y1=[],[]
fr = open('./knn.txt')
for line in fr.readlines():
lineArr = line.strip().split()
X1.append([int(lineArr[0]),int(lineArr[1])])
y1.append(int(lineArr[2]))
X=np.array(X1)
y=np.array(y1)
X_train,X_test,Y_train,Y_test=train_test_split(X,y,test_size=0.16)
k_range = range(1, 9)
k_error = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=3, scoring='accuracy')
k_error.append(1 - scores.mean())
k_error.pop(0)
k_min = min(k_error)
k = k_error.index(k_min)
knn=KNeighborsClassifier(k + 2)
knn.fit(X,y)
KNeighborsClassifier(n_neighbors=3)
y_pred=knn.predict(X_test)
print(knn.score(X_test,Y_test))
print(metrics.accuracy_score(y_true=Y_test,y_pred=y_pred))
print(metrics.confusion_matrix(y_true=Y_test,y_pred=y_pred))
from sklearn.metrics import classification_report
target_names = ['labels_1','labels_2','labels_3']
print(classification_report(Y_test,y_pred))
1.0
1.0
[[2]]
precision recall f1-score support
2 1.00 1.00 1.00 2
accuracy 1.00 2
macro avg 1.00 1.00 1.00 2
weighted avg 1.00 1.00 1.00 2
label=knn.predict([[7,27],[2,4]])
print(label)
[2 1]
import matplotlib as mpl
N, M = 90, 90
t1 = np.linspace(0, 25, N)
t2 = np.linspace(0,12, M)
x1, x2 = np.meshgrid(t1, t2)
x_show = np.stack((x1.flat, x2.flat), axis=1)
y_show_hat = knn.predict(x_show)
y_show_hat = y_show_hat.reshape(x1.shape)
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light,alpha=0.3)
<matplotlib.collections.QuadMesh at 0x3e6b6e10>