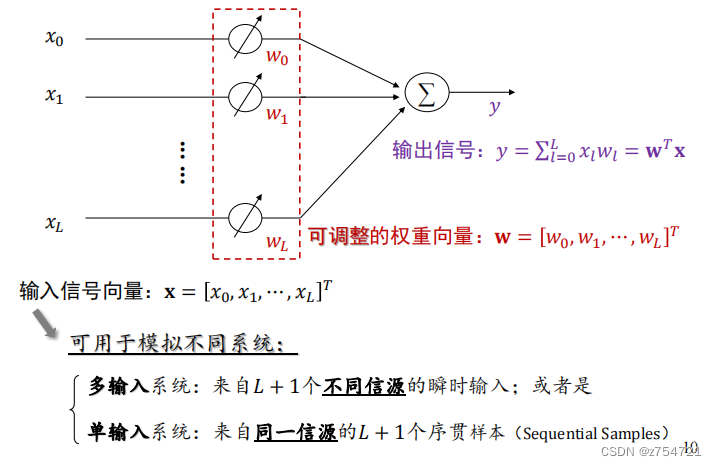
滤波器是一种以物理硬件或计算机软件形式,从含噪声的观测数据中抽取信号的装置。
前言
滤波器可以实现滤波、平滑和预测等信息处理的基本任务。如果滤波器输出是滤波器输入的线性函数,则称为线性滤波器;否则称为非线性滤波器。若滤波器的冲激响应是无穷长的,便称为无限冲激响应(IIR)滤波器,而冲激响应有限长的滤波器叫做有限冲激响应(FIR)滤波器。如果滤波器是在时间域、频率域或空间域实现,则分别称为时域滤波器、频域滤波器或空域滤波器。“信号与系统”和“数字信号处理”等课程主要是在频率域讨论滤波器,本章重点关注时域滤波器。
自适应滤波器是一种信号处理技术,用于从信号中提取所需信息或去除噪声。与传统的固定滤波器不同,自适应滤波器可以根据信号的实时特性自动调整其滤波参数,以适应信号的变化。
自适应滤波器的核心思想是根据输入信号的统计特性动态调整滤波器的参数。它通常包括以下几个步骤:
观测信号: 首先,需要观测输入信号,以便了解信号的统计特性和噪声情况。
估计滤波器参数: 基于观测到的信号,估计出滤波器的参数,使其能够有效地抑制噪声或提取所需的信号成分。这通常涉及到某种形式的自适应算法,如最小均方(LMS)算法或最小均方误差(LMMSE)算法等。
调整滤波器参数: 根据估计出的滤波器参数,动态调整滤波器以反映输入信号的实时特性。这可以通过不断地更新参数来实现,以适应信号的变化。
滤波处理: 将输入信号通过调整后的滤波器进行处理,以获得所需的输出信号。
自适应滤波器在许多领域都有广泛的应用,包括通信、雷达、医学影像处理等。它们可以有效地应对信号中的噪声和干扰,提高系统的性能和鲁棒性。
一、匹配滤波器
1、匹配滤波器(Matched Filter)
匹配滤波器是一种特定于信号和噪声统计特性的线性滤波器,用于最大化信号与预定义模板的相关性,从而实现最佳信号检测。其在雷达、通信等领域广泛应用。
优点:
- 最大化信号与预定义模板的相关性,对于已知信号和噪声统计特性的情况,具有最佳检测性能。
- 实现简单,计算效率高。
缺点:
- 对信号和噪声的统计特性要求较高,需要先验知识。
- 对信号的实时变化不敏感,不适用于动态环境。
匹配滤波器的输出可以表示为输入信号与模板信号的卷积运算,数学表达式如下:

其中,
- y(t) 是输出信号,
- x(t) 是输入信号,
- h(t) 是匹配滤波器的模板信号。
匹配滤波器的输出与输入信号之间的相关性可以用相关函数表示,数学表达式如下:

其中,
- Ryx(τ) 是输入信号x(t) 与输出信号 y(t) 之间的相关函数,
- τ 表示时间延迟。
匹配滤波器的输出峰值通常发生在输入信号与模板信号之间存在完美匹配的情况下,此时相关函数达到最大值。输出峰值 P 可以表示为: P=max(Ryx(τ))
匹配滤波器的设计目标是最大化信号与模板信号之间的相关性,从而提高信号与噪声的区分度。信噪比增益 G 可以定义为输出信号的平均功率与噪声功率之比:

波形匹配是指匹配滤波器的模板信号与待检测信号的波形相似度高。在波形匹配的情况下,匹配滤波器能够最大化输出信号与信号波形的相关性,从而实现最佳的信号检测。
白噪声情况下的最优滤波——匹配滤波器
在白噪声情况下,匹配滤波器可以实现最佳信号检测性能。白噪声是指具有平均功率谱密度均匀分布的随机信号,其功率在所有频率上都相等。在这种情况下,匹配滤波器能够最大化信号与噪声的相关性,从而提高信号检测的性能。
假设我们有一个输入信号x(t),包含待检测的信号 s(t) 和白噪声 n(t): x(t)=s(t)+n(t)
匹配滤波器的模板信号h(t) 通常选择与待检测信号 s(t) 相同的波形,因为在匹配滤波器的设计中,我们希望最大化待检测信号与模板信号之间的相关性。
匹配滤波器的输出 y(t) 可以表示为输入信号 x(t) 与模板信号 h(t) 的卷积运算:

在白噪声的情况下,噪声 n(t) 的功率谱密度均匀分布,可以表示为常数 N0。因此,匹配滤波器的输出信号与噪声之间的相关性可以简化为:

其中,δ(τ) 是单位冲激函数。
匹配滤波器的输出峰值P 通常发生在待检测信号与模板信号之间完美匹配的情况下,此时相关函数达到最大值。在白噪声背景下,匹配滤波器的输出峰值可以简化为:

因此,在白噪声背景下,匹配滤波器设计的关键是最大化模板信号的功率,从而提高输出信号与噪声之间的相关性,实现最佳的信号检测性能。
有色噪声情况下的最优滤波——广义匹配滤波器
在有色噪声情况下,即噪声的功率谱密度不是均匀分布的情况下,匹配滤波器的设计需要考虑噪声的频率特性。在这种情况下,可以使用广义匹配滤波器(Generalized Matched Filter)来实现最优滤波。
假设有色噪声的功率谱密度由函数 )Sn(f) 给出,其中 f 表示频率。通常情况下,有色噪声可以用自相关函数 Rn(τ) 表示。
广义匹配滤波器的设计旨在最大化信号与噪声之间的相关性,而不仅仅是匹配信号与模板信号的波形。其模板信号的设计可以通过以下步骤实现:
计算信号的自相关函数: 计算信号的自相关函数 Rs(τ)。
计算信号与噪声的互相关函数: 计算信号与噪声的互相关函数 Rsn(τ)。
设计模板信号: 广义匹配滤波器的模板信号可以通过以下公式计算: h(t)=Rs−1(τ)∗Rsn(τ) 其中,Rs−1(τ) 表示信号的自相关函数的逆,∗ 表示卷积运算。
广义匹配滤波器的输出 y(t) 可以表示为输入信号 x(t) 与模板信号 h(t) 的卷积运算:

广义匹配滤波器的设计旨在最大化输出信号与信号的相关性,同时考虑了噪声的颜色特性。通过合理设计模板信号,可以优化广义匹配滤波器的性能,提高信号检测的准确性和鲁棒性。

2、匹配滤波器的性质
匹配滤波器是一种特殊的线性滤波器,其设计旨在最大化输入信号与滤波器的模板信号之间的相关性。以下是匹配滤波器的一些重要性质:
最大化相关性
匹配滤波器的设计目标是使输出信号与预定义的模板信号之间的相关性最大化。这意味着当输入信号与模板信号完全匹配时,匹配滤波器的输出将达到最大值。
与输入信号的相关性
匹配滤波器的输出与输入信号之间的相关性可以用相关函数表示。在匹配滤波器中,相关函数通常用于衡量输入信号中是否存在与模板信号相似的特征。
波形匹配
匹配滤波器通常被设计为与待检测信号具有相似的波形。在波形匹配的情况下,匹配滤波器能够最大化输出信号与信号波形的相关性,从而实现最佳的信号检测性能。
最优性能
在理想情况下,匹配滤波器能够实现最佳的信号检测性能。然而,在实际应用中,匹配滤波器的性能可能受到信号和噪声的非理想性、系统噪声以及滤波器设计的限制等因素的影响。
适用性广泛
匹配滤波器在许多领域都有广泛的应用,包括雷达、通信、生物医学信号处理等。它们能够有效地提高信号与噪声的区分度,从而改善系统的性能和鲁棒性。
匹配滤波器对波形相同而幅值不同的时延信号具有适应性。匹配滤波器对频移信号不具有适应性。
3、匹配滤波器的实现
1). 确定模板信号
首先,需要确定用作匹配滤波器的模板信号。模板信号通常是待检测信号的理想表示,其波形与待检测信号相似。
2).计算模板信号的自相关函数
接下来,计算模板信号的自相关函数。自相关函数描述了信号与其自身在不同时间延迟下的相关性。匹配滤波器的设计是为了最大化输入信号与模板信号之间的相关性,因此自相关函数是设计匹配滤波器的关键。
3).实现匹配滤波器
匹配滤波器可以通过以下两种方法实现:
时域方法:直接实现匹配滤波器的卷积操作。在时域中,匹配滤波器的输出可以表示为输入信号与模板信号的卷积运算。可以使用卷积的快速算法(如快速傅里叶变换)来高效地计算滤波器的输出。
频域方法:将输入信号和模板信号都转换到频域,然后将它们的频谱相乘,最后通过逆傅里叶变换得到滤波器的输出。这种方法可以通过频谱乘法来实现匹配滤波器的效果。
4).输出处理
匹配滤波器的输出通常是一个连续的信号。根据具体应用,可能需要对输出信号进行后续处理,例如设置阈值以进行信号检测,或者进行信号分析以提取感兴趣的特征。
5).参数调优和性能评估
最后,对匹配滤波器的参数进行调优,并对其性能进行评估。可以通过模拟仿真或实际数据测试来验证匹配滤波器在不同条件下的性能表现,并根据需要进行调整和优化。
二、连续时间的Wiener 滤波器
Wiener 滤波器是一种经典的线性滤波器,旨在最小化输出信号与原始信号之间的均方误差,同时考虑信号和噪声的统计特性。
优点:
- 考虑信号和噪声的统计特性,适用于较为复杂的信号和噪声场景。
- 对信号和噪声的要求相对较低,不需要完全已知统计特性。
缺点:
- 需要对信号和噪声的统计特性进行合理的估计,可能会引入一定的误差。
- 对于非平稳信号或噪声,性能可能不稳定。
非因果Wiener 滤波器
非因果 Wiener 滤波器是一种滤波器,通常用于信号处理中,特别是在需要处理非因果系统的情况下。非因果系统是指其输出取决于未来的输入,而不仅仅是当前和过去的输入。
在非因果系统的情况下,传统的因果滤波器设计方法可能不适用,因为它们基于当前和过去的输入来计算输出。而非因果 Wiener 滤波器允许考虑未来的输入,因此在处理非因果系统时更为适用。
非因果 Wiener 滤波器的设计基于经典的 Wiener 滤波器理论,该理论是一种线性滤波器设计方法,旨在最小化输出信号与期望信号之间的均方误差。然而,在处理非因果系统时,需要修改传统的 Wiener 滤波器设计方法,以考虑未来输入的影响。
通常,非因果 Wiener 滤波器的设计会通过一些技术手段来实现,例如:
- 预测未来输入:通过对未来输入信号进行预测,可以将非因果系统转化为因果系统。预测技术可以基于已知的信号模型、历史数据或其他先验信息。
- 反向滤波:采用反向滤波技术来处理非因果系统。这种方法利用了系统的逆特性,以一种与传统 Wiener 滤波器不同的方式来设计滤波器参数。
因果Wiener 滤波器
因果 Wiener 滤波器是一种经典的线性滤波器,它基于 Wiener-Hopf 方程,旨在最小化输出信号与期望信号之间的均方误差,适用于因果系统的信号处理任务。
因果 Wiener 滤波器的设计基于信号和噪声的统计特性,旨在最小化输出信号与期望信号之间的均方误差。它通过对输入信号和滤波器的线性组合来生成输出信号,其中滤波器的系数通过最小化均方误差来确定。
Wiener-Hopf 方程描述了 Wiener 滤波器的设计原理,它是一种线性代数方程,通过解 Wiener-Hopf 方程可以得到滤波器的系数。在因果 Wiener 滤波器的情况下,Wiener-Hopf 方程可以表示为:

其中,
- Rxx(k) 是输入信号x(k) 的自相关函数,
- Rxy(k) 是输入信号 x(k) 与期望信号 y(k) 的互相关函数,
- w(k) 是滤波器的系数。
通过解 Wiener-Hopf 方程,可以得到滤波器的系数 w(k),通常使用 Levinson-Durbin 递归算法或 Yule-Walker 方程等方法来求解。这些方法可以有效地计算出最优的滤波器系数,以最小化输出信号与期望信号之间的均方误差。
得到滤波器系数后,可以将它们应用于输入信号进行滤波处理。滤波器的实现可以通过直接滤波运算、卷积运算或者快速傅里叶变换等方式进行。
在实际应用中,通常需要对滤波器的参数进行调优,并对其性能进行评估。可以通过模拟仿真或实际数据测试来验证滤波器在不同条件下的性能表现,并根据需要进行调整和优化。

三、最优滤波器与Wiener 滤波器
1、线性最优滤波器

线性离散滤波器
线性最优滤波器是一类滤波器,旨在通过线性组合输入信号的样本来估计期望的输出信号,并使输出信号与期望信号之间的均方误差最小化。这类滤波器的设计是基于信号和噪声的统计特性,通常包括以下几种常见的线性最优滤波器:
Wiener 滤波器是一种经典的线性最优滤波器,旨在最小化输出信号与期望信号之间的均方误差。它的设计基于输入信号和期望信号的统计特性,通常通过解 Wiener-Hopf 方程来确定滤波器的系数。
Kalman 滤波器是一种递归最优滤波器,用于估计动态系统状态的最优滤波器。它基于状态空间模型和最小均方误差准则,结合先验信息和观测数据进行状态估计。Kalman 滤波器通常用于动态系统状态的实时跟踪和估计。
Savitzky-Golay 滤波器是一种平滑滤波器,用于平滑输入信号的曲线或曲面。它基于多项式拟合和最小二乘法,通过对输入信号的局部数据进行多项式拟合来估计输出信号。Savitzky-Golay 滤波器在信号平滑和去噪方面具有良好的性能。4. Least Mean Squares (LMS) 滤波器
LMS 滤波器是一种迭代最优滤波器,通过不断调整滤波器的权重系数,以最小化输出信号与期望信号之间的均方误差。它的设计基于梯度下降算法,具有较好的收敛性和适应性。
2、正交性原理

四、Kalman 滤波器
Kalman 滤波器是一种递归滤波器,用于估计动态系统状态的最优滤波器。它基于状态空间模型和最小均方误差准则,结合先验信息和观测数据进行状态估计。
自适应实现算法:
- 扩展 Kalman 滤波器(EKF):用于非线性系统的 Kalman 滤波器,通过线性化过程模型实现状态估计。
- 无迹变换 Kalman 滤波器(UKF):通过无迹变换来处理非线性系统,避免了对过程和观测模型的线性化。
优点:
- 能够有效处理非线性系统和非高斯噪声。
- 适用于动态系统状态估计的实时跟踪。
缺点:
- 对系统的动态模型要求较高,需要准确的系统建模。
- 对于高维状态空间和复杂系统,计算复杂度较高。
五、LMS 类自适应算法
与Kalman滤波算法基于状态空间模型不同,另一大类自适应算法则基于优化理论中的(梯度)下降算法。下降算法有两种主要实现方式。一种是自适应梯度算法,另一种是自适应高斯-牛顿算法。
自适应梯度算法包括最小均方(Least mean square, LMS)算法及其各种变型和改进(统称LMS类自适应算法),自适应高斯-牛顿算法则包括递推最小二来(recursive least squares,RLS)算法及其变型和改进。
LMS(最小均方)类自适应算法是一类基于梯度下降的自适应滤波器算法,用于调整滤波器的权重系数以适应输入信号的统计特性。LMS 类算法的核心思想是通过不断调整滤波器的权重系数,以最小化输出信号与期望信号之间的均方误差。以下是几种常见的 LMS 类自适应算法:
LMS 算法是最基本的一种 LMS 类自适应算法,它根据梯度下降的原理,以步进参数 �μ 不断更新滤波器的权重系数。具体地,权重系数的更新规则为:
w(n+1)=w(n)+μe(n)x(n)
其中,
- w(n) 是第 n 次迭代时的滤波器权重系数,
- μ 是步进参数(学习速率),
- e(n) 是输出信号与期望信号之间的误差,
- x(n) 是输入信号。
NLMS 算法是 LMS 算法的一种改进版本,它在权重系数更新过程中引入了归一化因子,以防止权重系数的更新幅度过大。具体地,NLMS 算法的权重系数更新规则为:

其中,x(n)∥2 是输入信号的模长的平方,ϵ 是一个小正数,用于防止除零错误。
RLS 算法是一种递归最小二乘法算法,与 LMS 类算法不同,它使用历史数据的信息来动态调整滤波器的权重系数。RLS 算法的主要思想是在每次迭代中更新滤波器的权重系数,以最小化预测误差的加权平方和。
APA 算法是一种基于梯度下降的自适应滤波器算法,它通过利用滤波器输出误差的历史信息来调整权重系数。APA 算法在权重系数更新中引入了一个反馈路径,以提高算法的收敛速度和稳定性。
1、下降算法
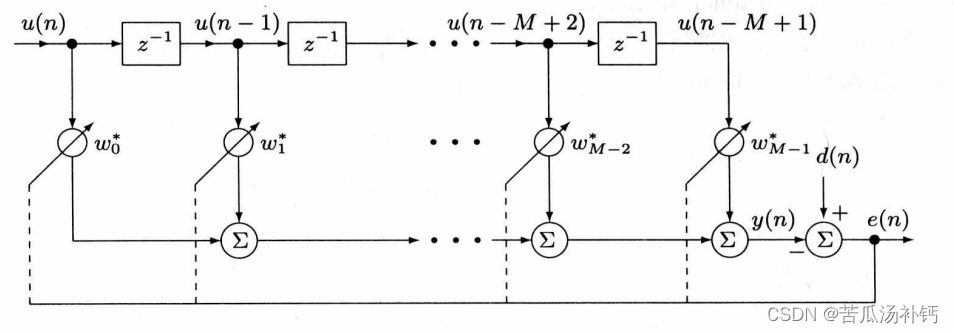
自适应FIR滤波器
梯度下降法(Gradient Descent)
梯度下降法是最基本的一种下降算法,其更新规则是沿着函数梯度的反方向以固定步长 �α 更新参数。具体地,参数 θ 的更新规则为:θ:=θ−α⋅∇J(θ)
其中,J(θ) 是目标函数,∇J(θ) 是目标函数的梯度。
随机梯度下降法(Stochastic Gradient Descent, SGD)
随机梯度下降法是梯度下降法的一种变体,它每次迭代仅使用一个样本来估计梯度,并根据该样本更新参数。SGD 在处理大规模数据集时具有较好的性能,但对于非凸优化问题可能会收敛到局部最小值。
批量梯度下降法(Batch Gradient Descent)
批量梯度下降法是梯度下降法的一种变体,它在每次迭代中使用整个训练集来估计梯度,并根据整个训练集更新参数。批量梯度下降法通常具有较好的收敛性,但在处理大规模数据集时计算代价较高。
动量法(Momentum)
动量法是一种改进的梯度下降算法,它引入了动量项来加速收敛过程,并减小参数更新的方差。动量法通过综合考虑当前梯度和之前的更新方向,来更新参数。动量法在处理非凸优化问题和高曲率问题时具有良好的性能。
自适应学习率方法
自适应学习率方法是一类根据梯度信息动态调整学习率的算法,以提高收敛速度和稳定性。常见的自适应学习率方法包括 Adagrad、RMSprop、Adam 等。
2、LMS算法及其基本变型


六、RLS自适应算法
1、RLS算法
RLS 算法基于最小二乘法原理,通过不断调整参数来最小化预测误差的加权平方和。它在每次迭代中递归地更新参数,以适应动态系统的变化。
RLS 算法的主要步骤如下:

特点
- 递归更新:RLS 算法具有递归性质,每次迭代仅使用最新的数据进行更新,因此具有较低的计算复杂度。
- 忘却因子:通过引入忘却因子 λ,RLS 算法可以平衡新数据和历史数据对参数估计的影响,从而提高算法的适应性和稳定性。
- 收敛速度:由于采用了最小二乘法原理,RLS 算法通常具有较快的收敛速度,在动态系统参数估计和自适应滤波器设计中具有广泛的应用。
2、RLS算法与Kalman滤波算法的比较

RLS(Recursive Least Squares)算法和 Kalman 滤波算法都是用于动态系统参数估计和状态估计的经典方法,但它们在算法原理、适用场景和性能表现上有一些不同之处。以下是 RLS 算法和 Kalman 滤波算法的比较:
算法原理
- RLS 算法:RLS 算法基于最小二乘法原理,通过不断调整参数来最小化预测误差的加权平方和。它是一种基于批处理的算法,每次迭代更新使用所有可用的数据。
- Kalman 滤波算法:Kalman 滤波算法是一种递归状态估计算法,基于动态系统的状态空间模型和最小均方误差准则。Kalman 滤波算法通过递归地更新状态估计值和协方差矩阵,以最小化预测误差的均方和。
适用场景
- RLS 算法:RLS 算法适用于静态或缓慢变化的系统,特别适用于批处理任务,例如离线数据处理、系统辨识等。
- Kalman 滤波算法:Kalman 滤波算法适用于动态系统的在线状态估计,特别适用于实时控制、运动跟踪、导航等需要实时更新状态的任务。
参数估计与状态估计
- RLS 算法:RLS 算法主要用于参数估计,即估计系统的模型参数。它通常用于线性模型的参数估计和自适应滤波器设计。
- Kalman 滤波算法:Kalman 滤波算法用于状态估计,即估计动态系统的状态变量。它能够处理动态系统的状态估计和预测,并在不确定性条件下提供最优估计。
鲁棒性与实时性
- RLS 算法:RLS 算法在静态或缓慢变化的环境下通常具有较高的估计精度,但对于快速变化或非线性系统的适应性较差。
- Kalman 滤波算法:Kalman 滤波算法能够处理动态环境下的状态估计,具有较好的鲁棒性和实时性,适用于动态系统的实时监测和控制。
计算复杂度
- RLS 算法:RLS 算法通常具有较高的计算复杂度,特别是在处理大规模数据集时,需要存储和处理大量的历史数据。
- Kalman 滤波算法:Kalman 滤波算法具有较低的计算复杂度,特别适用于在线状态估计和实时控制任务,能够快速更新状态估计值。
七、自适应谱线增强器与陷波器
自适应谱线增强器(Adaptive Spectrum Enhancer)和陷波器(Notch Filter)是两种用于信号处理的滤波器,它们在不同的应用场景中起着不同的作用。
自适应谱线增强器(Adaptive Spectrum Enhancer)
自适应谱线增强器是一种用于增强信号频谱中特定频率成分的滤波器。它基于信号的频谱特性,在频域对信号进行增强或抑制,以实现特定频率成分的增强或衰减。自适应谱线增强器通常用于信号的频谱修复、音频增强、图像增强等应用中。
陷波器(Notch Filter)
陷波器是一种用于抑制特定频率成分的滤波器,它在频率域上通过对特定频率成分进行抑制,以消除或减弱信号中的干扰或噪声。陷波器通常用于消除电力线杂散、滤除特定频率的噪声、抑制共模干扰等应用中。
比较
功能:
- 自适应谱线增强器主要用于增强特定频率成分,以提高信号的可辨识性或品质。
- 陷波器主要用于抑制特定频率成分,以消除信号中的干扰或噪声。
设计方法:
- 自适应谱线增强器通常基于信号的频谱特性,采用自适应滤波器设计方法实现频谱增强。
- 陷波器设计方法主要考虑需要抑制的频率成分,采用滤波器设计方法实现特定频率的抑制。
应用场景:
- 自适应谱线增强器适用于需要增强特定频率成分的信号处理任务,如音频增强、图像增强等。
- 陷波器适用于需要抑制特定频率成分的信号处理任务,如噪声消除、干扰抑制等。
效果评估:
- 自适应谱线增强器的效果通常通过信号的频谱分析来评估,评价频谱中特定频率成分的增强效果。
- 陷波器的效果通常通过信号的频谱分析和陷波后的信号质量来评估,评价是否成功抑制了特定频率的成分。

传递函数
八、广义旁瓣对消器
广义旁瓣对消器(Generalized Sidelobe Canceller,GSC)是一种自适应滤波器结构,用于抑制信号处理中的旁瓣干扰。它在通信系统、雷达系统等领域中被广泛应用,用于消除接收信号中的干扰和噪声,从而提高系统性能。
广义旁瓣对消器的基本原理是利用自适应滤波器的结构,通过抑制接收信号中的旁瓣干扰来提高信号质量。它通常由两部分组成:
- 主通道(Main Channel):负责接收期望信号和旁瓣干扰。
- 辅助通道(Auxiliary Channel):负责接收旁瓣干扰。
广义旁瓣对消器通过自适应滤波器来调整辅助通道的权重系数,使其输出的干扰信号与主通道的干扰信号相消,从而实现干扰的抑制。
广义旁瓣对消器的结构特点包括:
- 双通道结构:由主通道和辅助通道组成,其中主通道接收期望信号和干扰信号,辅助通道接收干扰信号。
- 自适应滤波器:用于调整辅助通道的权重系数,以最小化干扰信号与主通道信号的相关性。
- 多级结构:可以通过串联多个广义旁瓣对消器单元来提高抑制效果和适应性。
广义旁瓣对消器主要应用于以下场景:
- 通信系统中,用于抑制多径干扰和自干扰。
- 雷达系统中,用于抑制旁瓣回波和干扰信号。
广义旁瓣对消器的实现通常采用自适应滤波器算法,如LMS算法、RLS算法等。通过在线自适应调整辅助通道的权重系数,使其输出的干扰信号与主通道的干扰信号相消,从而实现干扰的抑制。
九、盲自适应多用户检测
盲自适应多用户检测(Blind Adaptive Multiuser Detection)是一种用于多用户通信系统中的信号检测技术。在多用户通信系统中,由于多个用户同时发送信号并共享同一频谱资源,接收端需要对多个用户的信号进行分离和检测,以正确地解调和译码每个用户的信号。盲自适应多用户检测技术旨在无需事先知道用户的信号结构和通信参数,即可对多个用户的信号进行有效的检测。
盲自适应多用户检测利用自适应滤波器结构,通过自适应地估计信道和用户信号的结构,来实现对多用户信号的分离和检测。其基本原理包括以下几个步骤:
- 自适应滤波器设计:设计自适应滤波器,用于估计和分离多个用户信号。
- 自适应参数估计:利用自适应算法,如LMS算法、RLS算法等,根据接收到的信号数据,自适应地估计信道特性和用户信号结构。
- 多用户信号分离:通过自适应滤波器对接收信号进行处理,分离出不同用户的信号成分。
- 信号检测和解调:对分离后的信号进行检测和解调,以恢复原始用户信号。
盲自适应多用户检测技术具有以下特点:
- 无需先验信息:无需事先知道用户的信号结构和通信参数,即可实现多用户信号的检测。
- 适应性强:能够自适应地对信道特性和用户信号的结构进行估计和调整,适应性强。
- 实时性:能够实时地对接收到的信号进行处理和检测,适用于动态的通信环境。
盲自适应多用户检测技术在多用户通信系统中具有广泛的应用,特别适用于以下场景:
- CDMA系统:在CDMA系统中,多个用户同时共享同一频率资源,盲自适应多用户检测技术能够有效地分离和检测多个用户信号。
- 多输入多输出(MIMO)系统:在MIMO系统中,由于存在多个发射和接收天线,盲自适应多用户检测技术能够实现有效的信号检测和解调。
盲自适应多用户检测技术的实现通常基于自适应滤波器算法和盲源分离算法,如LMS算法、RLS算法、独立成分分析(ICA)等。这些算法能够根据接收到的信号数据,自适应地估计信道和用户信号的结构,从而实现多用户信号的分离和检测。
总结
本文首先讨论两种常用的最优滤波器-匹配滤波器和 Wiener 滤波器,然后集中介绍Kalman滤波器和 Wiener滤波器的各种自适应实现算法。对任何一种自适应滤波器而言,自适应算法本身固然重要,但算法的统计性能尤其是跟踪系统或环境动态变化的能力,以及在实际中的应用也同样重要。