一、Hadoop基础架构概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它利用集群的威力进行高速运算和存储。用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop不仅稳定可靠,而且具有强大的可伸缩性,能够从单一服务器扩展到数千个节点,每个节点都可以是普通的硬件。这使得Hadoop成为大数据处理领域的首选工具。
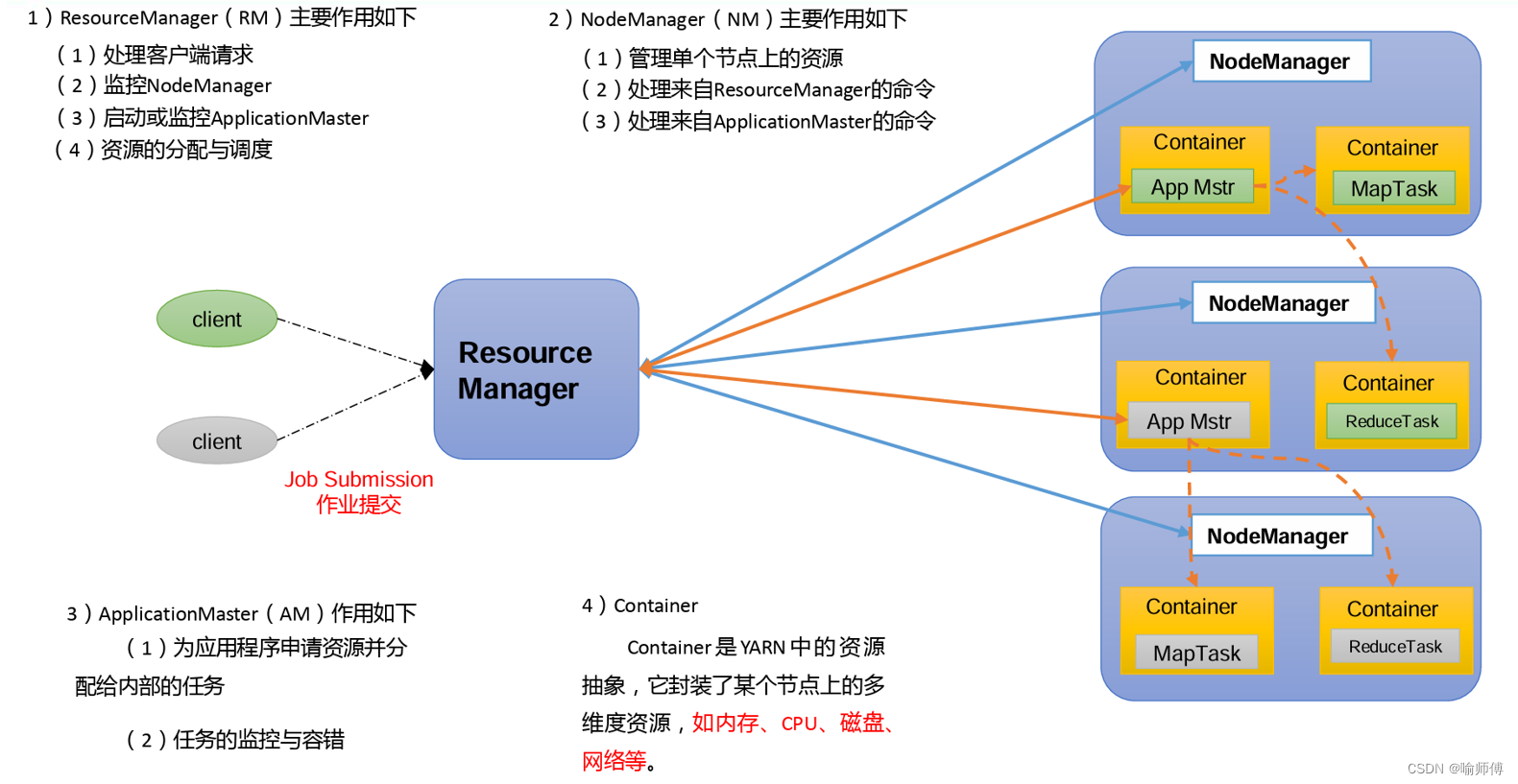
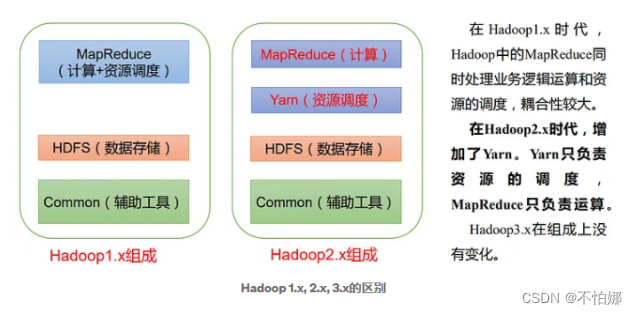
Hadoop的架构主要由两个核心组件构成:Hadoop Distributed File System(HDFS)和MapReduce。HDFS负责分布式存储,而MapReduce则负责分布式计算。
1. Hadoop Distributed File System (HDFS)
HDFS是Hadoop的分布式文件系统,设计用于在普通硬件上存储超大规模数据集。它具有高容错性,并且提供了对大数据集的高吞吐量访问。HDFS将数据分散存储在集群中的多个节点上,每个节点存储数据的一个分片。这种分布式的存储方式不仅提高了数据的可靠性(因为数据有多个副本),而且使得数据访问和处理更加高效。
2. MapReduce
MapReduce是Hadoop的分布式计算框架,它允许程序员在不了解分布式系统底层细节的情况下,编写处理大规模数据的程序。MapReduce将复杂的任务分解为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,系统并行处理输入数据,生成一系列的中间键值对;在Reduce阶段,系统对具有相同键的所有值进行归约操作,生成最终的结果。
二、Hadoop的特点
Hadoop之所以在大数据处理领域得到广泛应用,主要得益于其以下几个显著特点:
1. 高可靠性
Hadoop按位存储和处理数据的能力值得人们信赖。HDFS能检测并自动处理硬件故障,因此数据丢失的可能性极小。MapReduce的设计也考虑到了硬件故障的可能性,它能自动重新分配失败的任务。
2. 高扩展性
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。也就是说,Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,非常适合在PB级以上的海量数据上运行MapReduce类型的程序。
3. 高效性
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。此外,Hadoop利用并行处理,使得数据处理的速度大大加快。
4. 高容错性
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。这使得Hadoop在硬件故障或数据损坏的情况下,仍能保持数据的完整性和任务的连续性。
5. 成本低廉
Hadoop是开源的,用户可以免费获取并修改其源代码。此外,Hadoop可以运行在普通的硬件上,无需购买昂贵的专用设备。这使得Hadoop成为许多企业和研究机构的理想选择。
三、Hadoop代码示例
下面是一个简单的Hadoop MapReduce程序示例,用于计算文本文件中单词的出现次数:
1. Mapper类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String str : words) {
word.set(str);
context.write(word, one);
}
}
}2. Reducer类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}3. 主程序
主程序是Hadoop MapReduce作业的入口点,它负责设置作业配置,指定Mapper和Reducer类,以及输入和输出路径。
java复制代码import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class); // 可以选择性地使用Combiner进行本地归约
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}在这个例子中,WordCount类是主类,它设置了作业的配置,并指定了输入和输出路径。WordCountMapper和WordCountReducer类分别实现了Map和Reduce阶段的功能。Mapper将输入的每一行文本分割成单词,并为每个单词输出一个键值对(单词,1)。Reducer则接收具有相同键的所有值,并计算它们的和,输出最终的单词计数。
四、Hadoop的生态系统
除了HDFS和MapReduce之外,Hadoop还拥有一个庞大的生态系统,包括一系列与数据处理和分析相关的工具和服务。这些工具和服务扩展了Hadoop的功能,使其能够应对更复杂的数据处理任务。以下是一些Hadoop生态系统中的重要组件:
- HBase:一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase可以在Hadoop之上提供类似于BigTable的能力。
- Hive:一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
- Pig:一个用于大规模数据处理的平台,它提供了一种高级查询语言Pig Latin,使得用户能够编写简单的脚本进行数据处理。
- Spark:一个快速、通用的大规模数据处理引擎,支持批处理、交互式查询、实时流处理、机器学习和图计算等多种处理模式。
- Flume:一个分布式、可靠和高可用的服务,用于有效地收集、聚合和移动大量日志数据。
五、总结
Hadoop以其高可靠性、高扩展性、高效性、高容错性和低成本等特点,成为大数据处理领域的领军技术。通过HDFS和MapReduce等基础组件,Hadoop能够处理PB级以上的海量数据,并提供强大的分布式计算能力。此外,Hadoop的生态系统提供了丰富的工具和服务,使得数据处理和分析变得更加简单和高效。随着大数据技术的不断发展,Hadoop将继续在各个领域发挥重要作用。

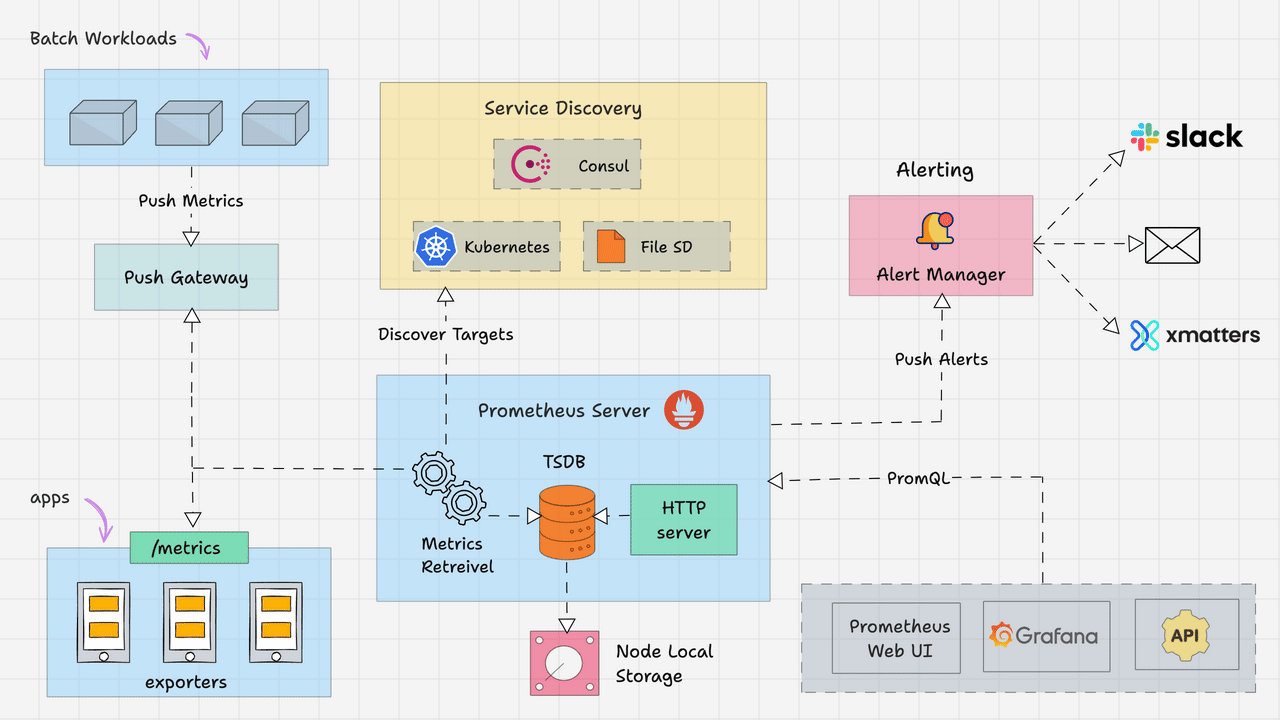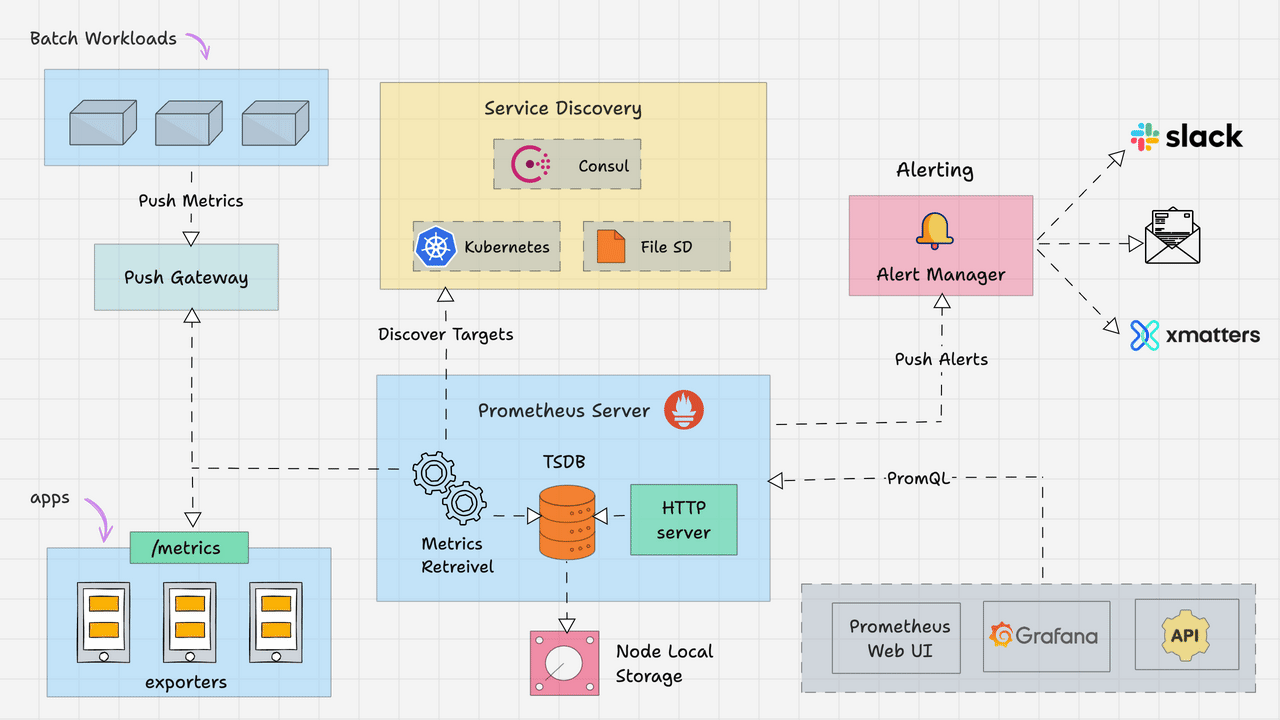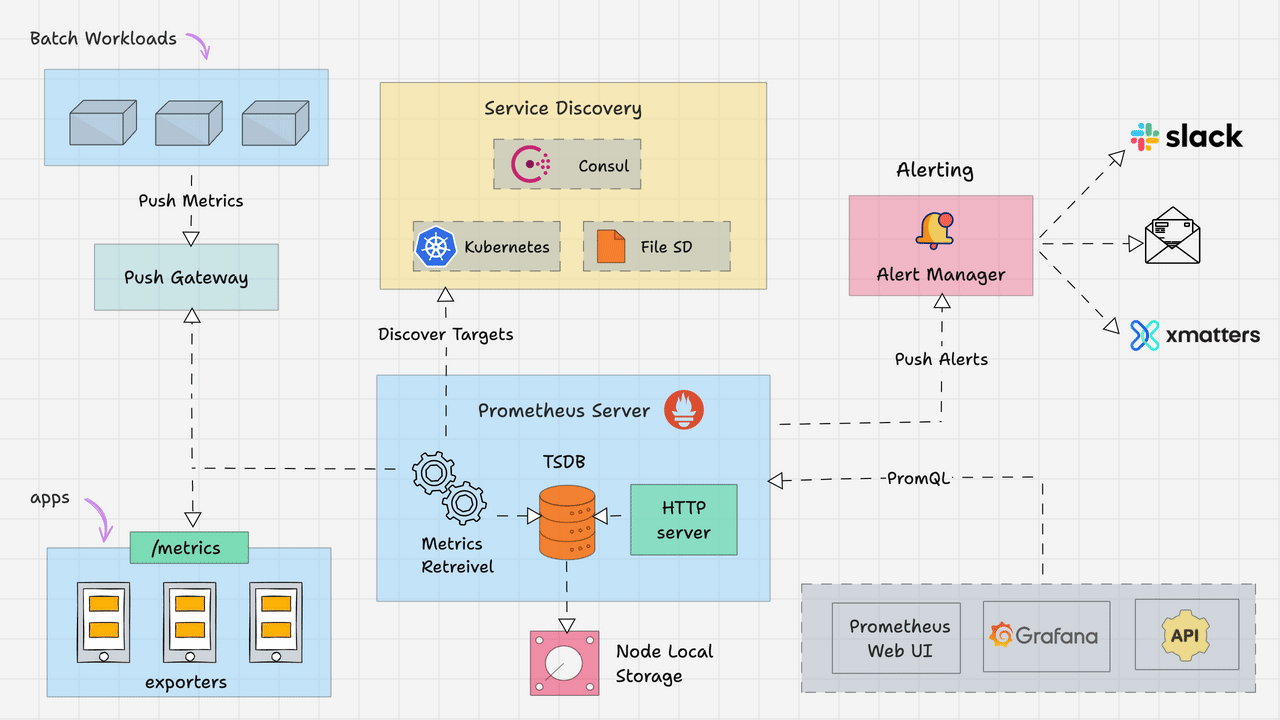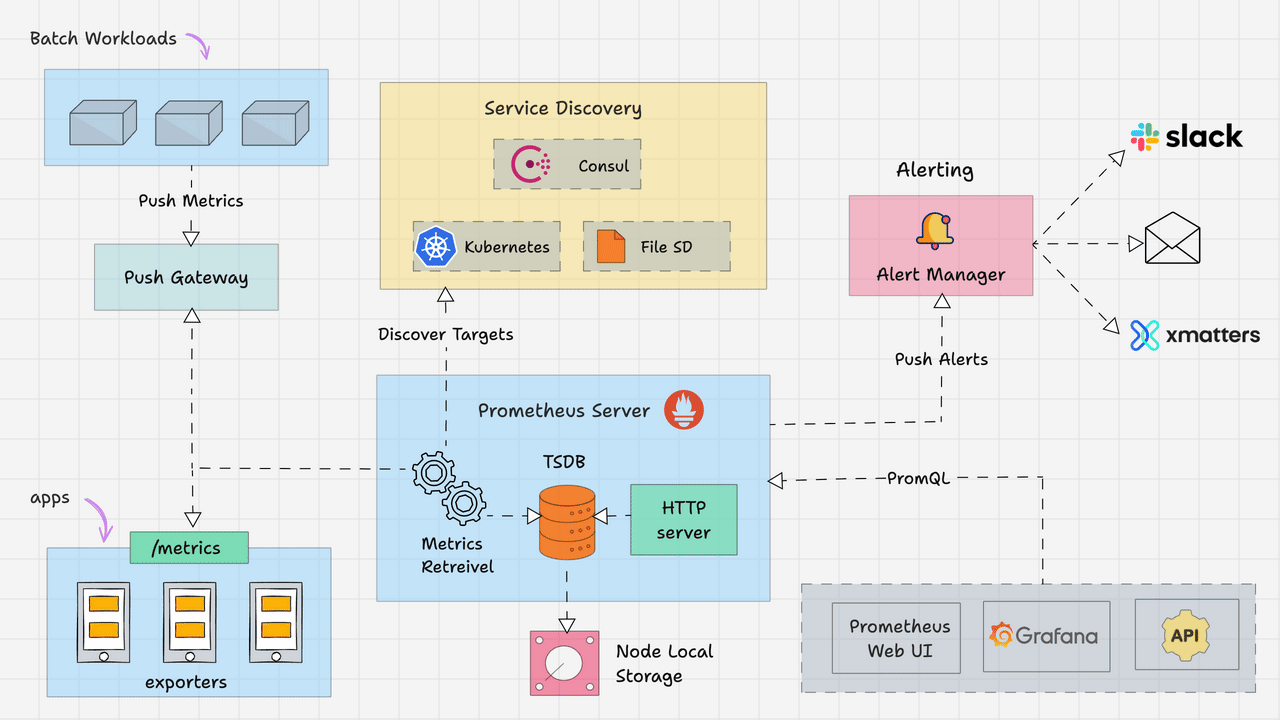


















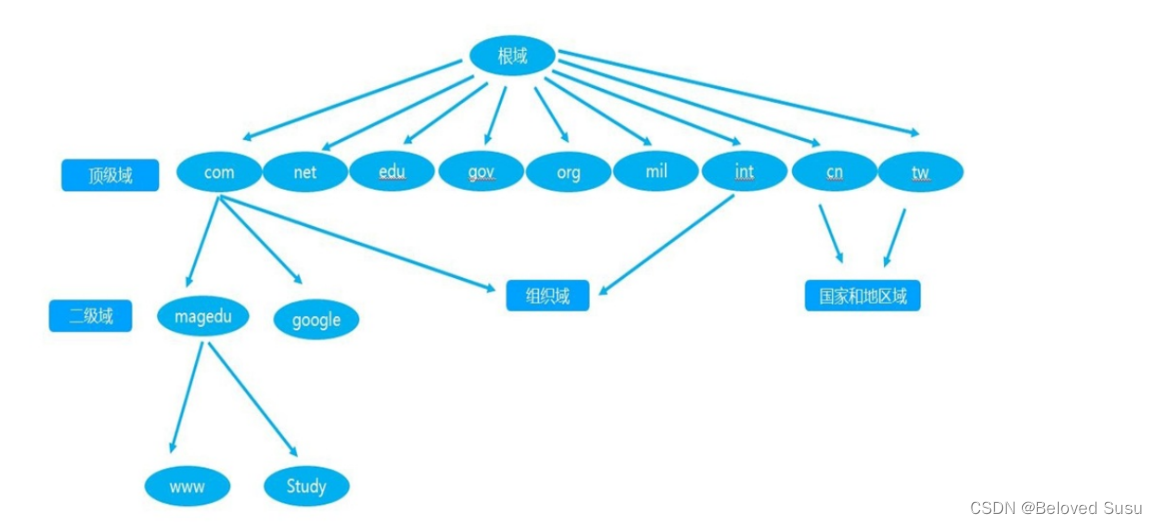
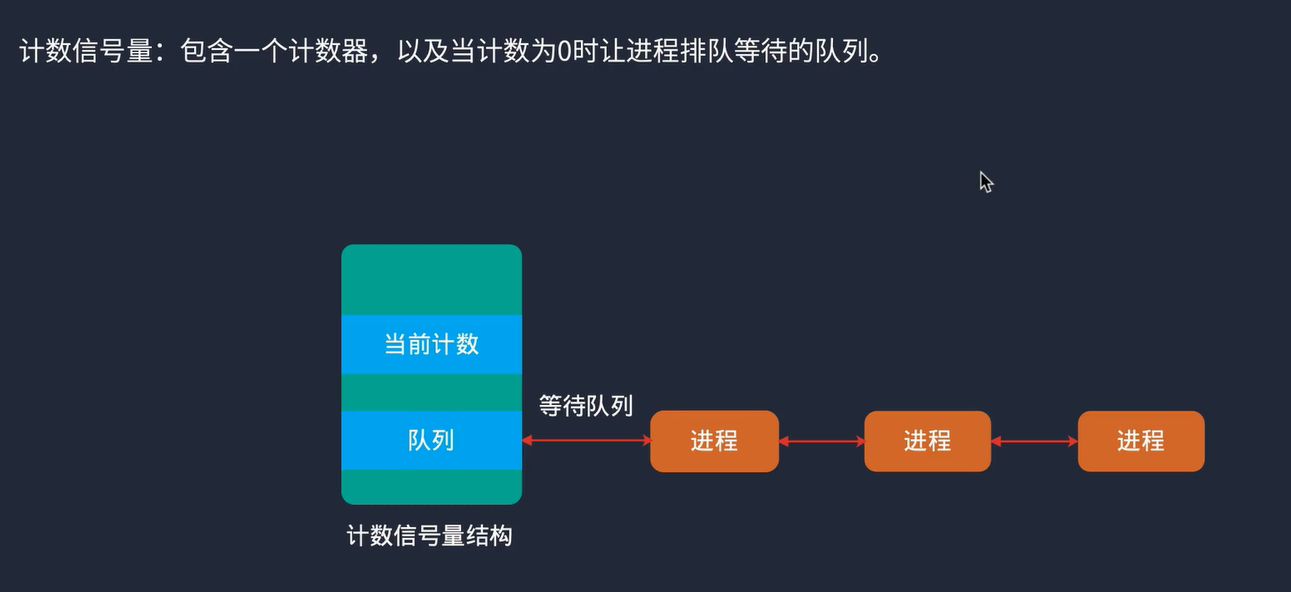





![[蓝桥杯练习题]确定字符串是否包含唯一字符/确定字符串是否是另一个的排列](https://img-blog.csdnimg.cn/direct/c7ef1b7c1cc143d8bd9eefdfd4286ca4.png)