在医学领域,文档资料常常涉及到大量的专业术语和生僻字,例如唑吡坦、哌替啶、氟桂利嗪等。这些专业词汇对于非专业人士来说可能较为陌生,但在医学研究和临床实践中却具有不可或缺的重要性。然而,当这些生僻字出现在PDF文档中,尤其是当需要将这些文档转化为可编辑的文本格式时,往往会遇到一些困难。许多常见的光学字符识别(OCR)软件在处理这些特殊字符时,往往效果不佳,无法准确识别。
在医学领域,文档资料常常涉及到大量的专业术语和生僻字,例如唑吡坦、哌替啶、氟桂利嗪等。这些专业词汇对于非专业人士来说可能较为陌生,但在医学研究和临床实践中却具有不可或缺的重要性。然而,当这些生僻字出现在PDF文档中,尤其是当需要将这些文档转化为可编辑的文本格式时,往往会遇到一些困难。许多常见的光学字符识别(OCR)软件在处理这些特殊字符时,往往效果不佳,无法准确识别。
针对这一问题,市场上出现了一款名为“金鸣表格文字识别大师”的软件,它以其强大的识别能力和专业的特点,受到了广大医学工作者的青睐。下面,我们将详细介绍这款软件的优点及其操作方法,帮助用户更好地解决医学文档PDF生僻字识别难题。
金鸣表格文字识别大师识别生僻字的操作方法
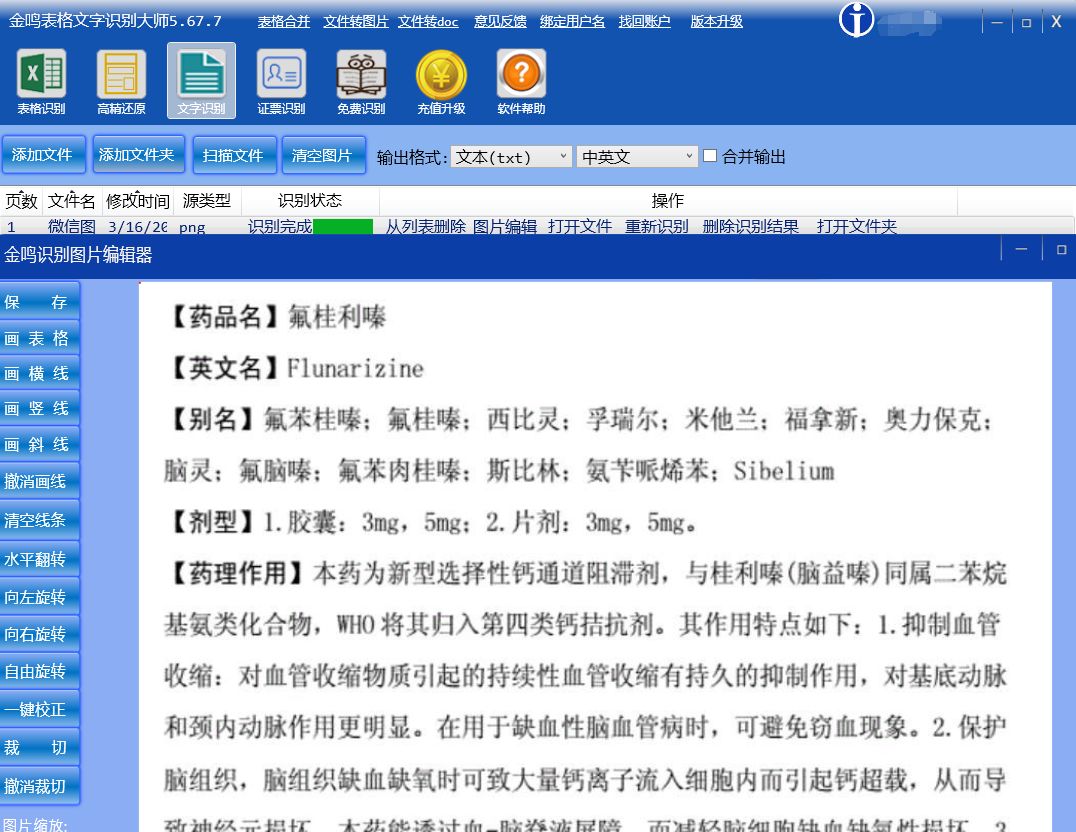
以带较多生僻字的药品说明书为例
1. 打开软件:首先,用户需要打开金鸣表格文字识别大师的电脑客户端。
2. 选择识别类型:在软件界面左上角,点击“文字识别”选项,并选择“文本(.txt)”作为识别类型。如果需要进行合并识别,可以勾选“合并”选项。
3. 添加文件:通过点击“添加文件”或“添加文件夹”按钮,将需要识别的医学文档PDF文件添加到程序中。用户也可以直接将PDF文件拖拽到程序窗口中进行添加。
4. 查看图片并确认:在添加文件后,点击“图片编辑”按钮,软件将使用电脑默认的图片编辑软件打开图片。
5. 提交识别:确认图片质量无误后,点击“提交识别”或“识别全部”按钮,软件将开始对PDF文档进行识别处理。
6. 查看识别结果:识别完成后,点击“打开文件”按钮,可以直接打开识别成功的文件。用户可以在软件中直接查看和编辑识别结果。
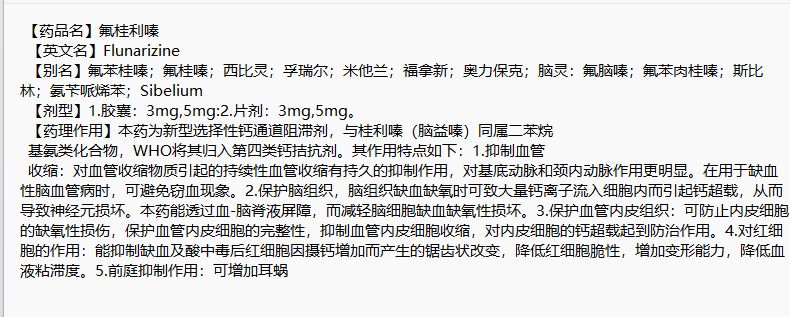
识别结果
7. 打开文件夹:如果需要查看识别结果所在的文件夹,可以点击“打开文件夹”按钮,软件将打开包含识别结果的文件夹路径。通过以上步骤,用户可以轻松地使用金鸣表格文字识别大师软件,解决医学文档PDF生僻字识别难题。这款软件以其高精度识别、多格式支持、强大编辑功能以及用户友好的界面等优点,成为了医学工作者在处理文档资料时的得力助手。无论是临床研究、学术交流还是医学教育等领域,金鸣表格文字识别大师都能为用户带来极大的便利和效益。























![[蓝桥杯练习题]确定字符串是否包含唯一字符/确定字符串是否是另一个的排列](https://img-blog.csdnimg.cn/direct/c7ef1b7c1cc143d8bd9eefdfd4286ca4.png)