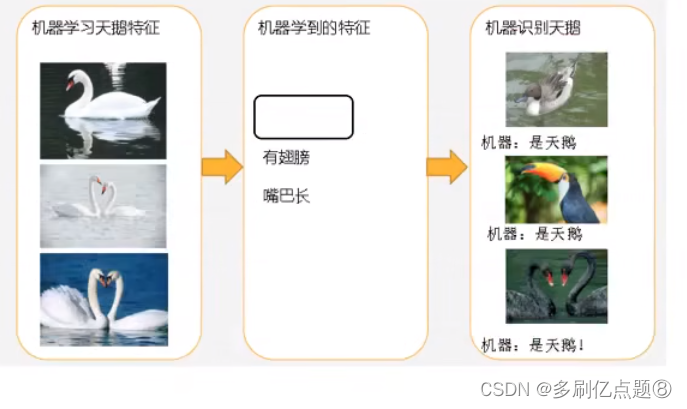
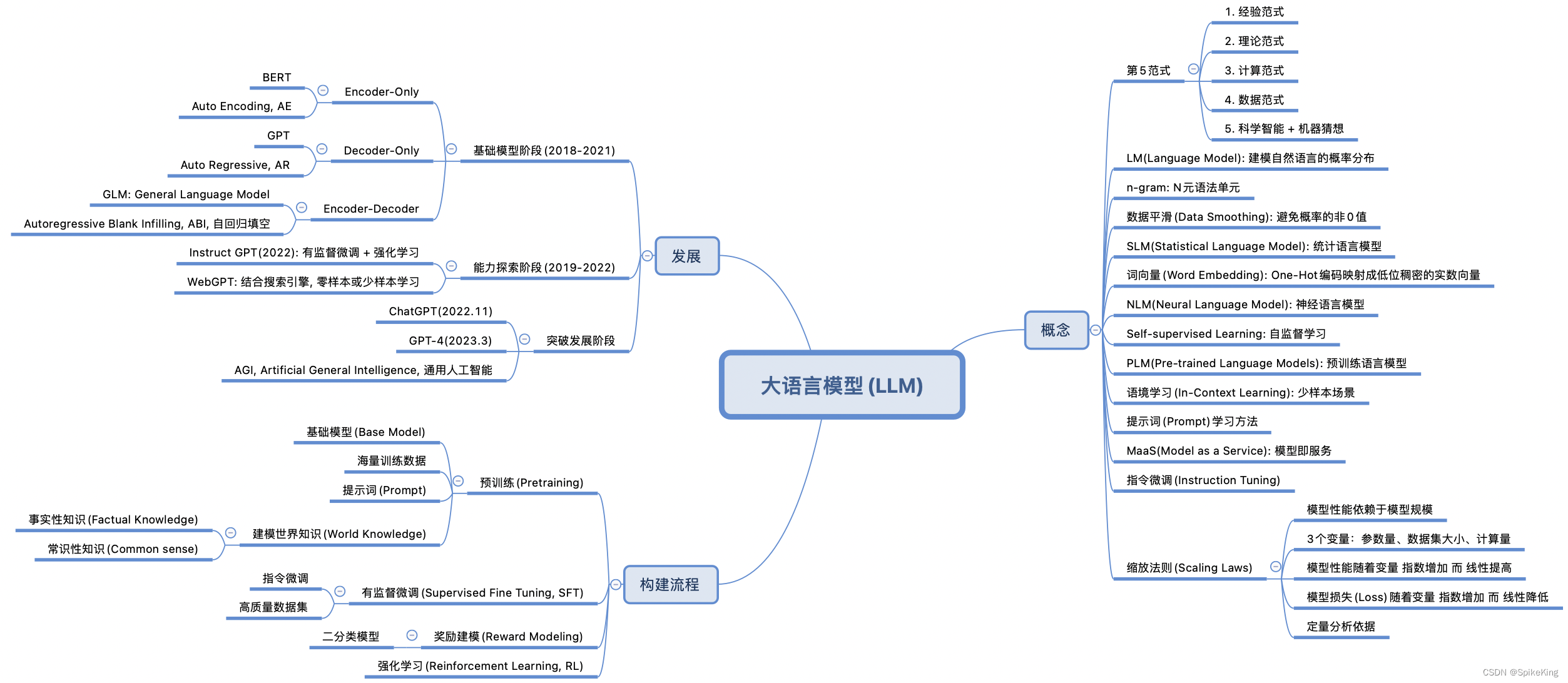
过拟合是指机器学习模型在训练数据上表现良好,但在未见过的测试数据上表现较差的现象。在大语言模型(LLM)中,过拟合问题也是需要注意和应对的重要挑战之一。
以下是在大语言模型中处理过拟合问题的一些常见方法:
数据增强(Data Augmentation): 增加训练数据的多样性是减轻过拟合的有效方法之一。可以通过对文本进行随机删除、替换、插入等操作来生成更多的训练样本,从而提高模型的泛化能力。
正则化(Regularization): 正则化技术可以限制模型的复杂度,减少过拟合的风险。常见的正则化方法包括L1正则化、L2正则化以及Dropout等。在LLM中,通常会采用参数范数惩罚(如权重衰减)或者在训练过程中随机丢弃一部分神经元来进行正则化。
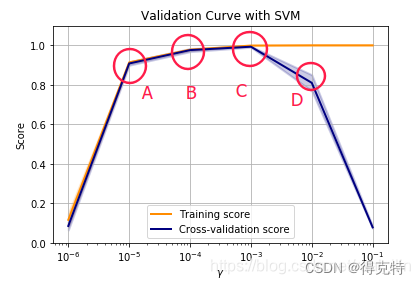
提前停止(Early Stopping): 在训练过程中监控模型在验证集上的性能,并在性能不再提升时停止训练,可以避免模型过拟合训练数据。
模型集成(Model Ensemble): 将多个不同的LLM集成在一起,可以减少单个模型的过拟合风险。通过投票或取平均等方式结合多个模型的预测结果,可以提高模型的鲁棒性和泛化能力。
交叉验证(Cross-Validation): 将数据集划分为多个子集,轮流使用其中的一个子集作为验证集,其余作为训练集进行模型训练,可以更准确地评估模型的泛化性能。
模型简化(Model Simplification): 有时候,减少模型的复杂度可以减轻过拟合问题。可以通过减少模型的层数、节点数量或者采用更简单的模型架构来实现。
综上所述,过拟合是大语言模型中需要重点关注和解决的问题之一。通过采用合适的数据增强、正则化、提前停止等技术,可以有效地减轻模型的过拟合现象,提高模型的泛化能力和性能。