正在编写相关软著,借此机会了解R语言的基本语法和一些处理流程,所以解释稍微繁琐。
Note:
使用的R语言版本是 R version 4.3.2 (2023-10-31 ucrt)
使用的RStudio编辑器版本是:
01 基于随机森林的插值填补缺失值
这是目前处理的数据样式如下:

1.1 准备工作
library(mice) # 加载mice包, 这是一个用于处理缺失数据的R包, 可以进行多重插值填补缺失值
setwd("I:\\ObjectRS\\软著_绘姐\\SC1_Rs\\") # 设置工作目录, 类似环境变量配置
TJ<-read.csv("TJ_var8_1970-2022_2st_ori.csv") # 添加数据
library():加载包到当前运行文件中,类似Python的import,如果你想要使用某个统计包,你需要先加载至当前文件中才可以在当前代码块中使用该包相关函数和方法。
setwd():设置工作目录,类似于环境变量。即如果传入一个文件名而非文件的绝对路径时,此时解释器会先在工作目录中检索该文件是否存在。
变量 <- read.csv():读取csv文件内数据,并将得到的对象使用<-赋值给某一变量,<-等价于Python中的=。值得注意的是,read.csv并非是指利用.访问read对象中的方法csv方法,而是说.仅仅是作为函数名的一部分,并没有特殊含义,即read.csv就是一个函数的名称。
运行结果:
1.2 读取数据和数据预处理
mydata <- TJ[, 9:ncol(TJ)]
md.pattern(mydata) # 返回数据的缺失值的模式
anyNA(mydata) #> TRUE
str(mydata)
TJ[, 9:ncol(TJ)]:表示取第9列(包含)到最后一列(包含)的所有行,值得注意的是,R的索引是从1开始计数,而非如Python从0开始,使用[,]进行截取,,前面为行,后面为列。如果需要选择所有行,那么逗号前面无需添加任何内容。ncol函数用于获取TJ变量的总列数,注意9:ncol(TJ)表示第9到最后一列(左右闭区间),而非像Python为第9到倒数第二列(左闭右开)。
运行得到的结果mydata为:

md.pattern():表示输出该数据框的缺失模式,输出如下:
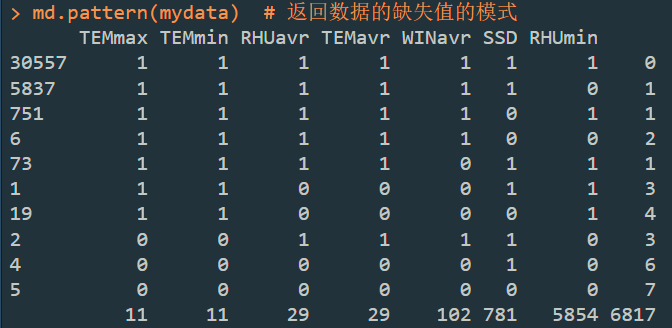
也即:
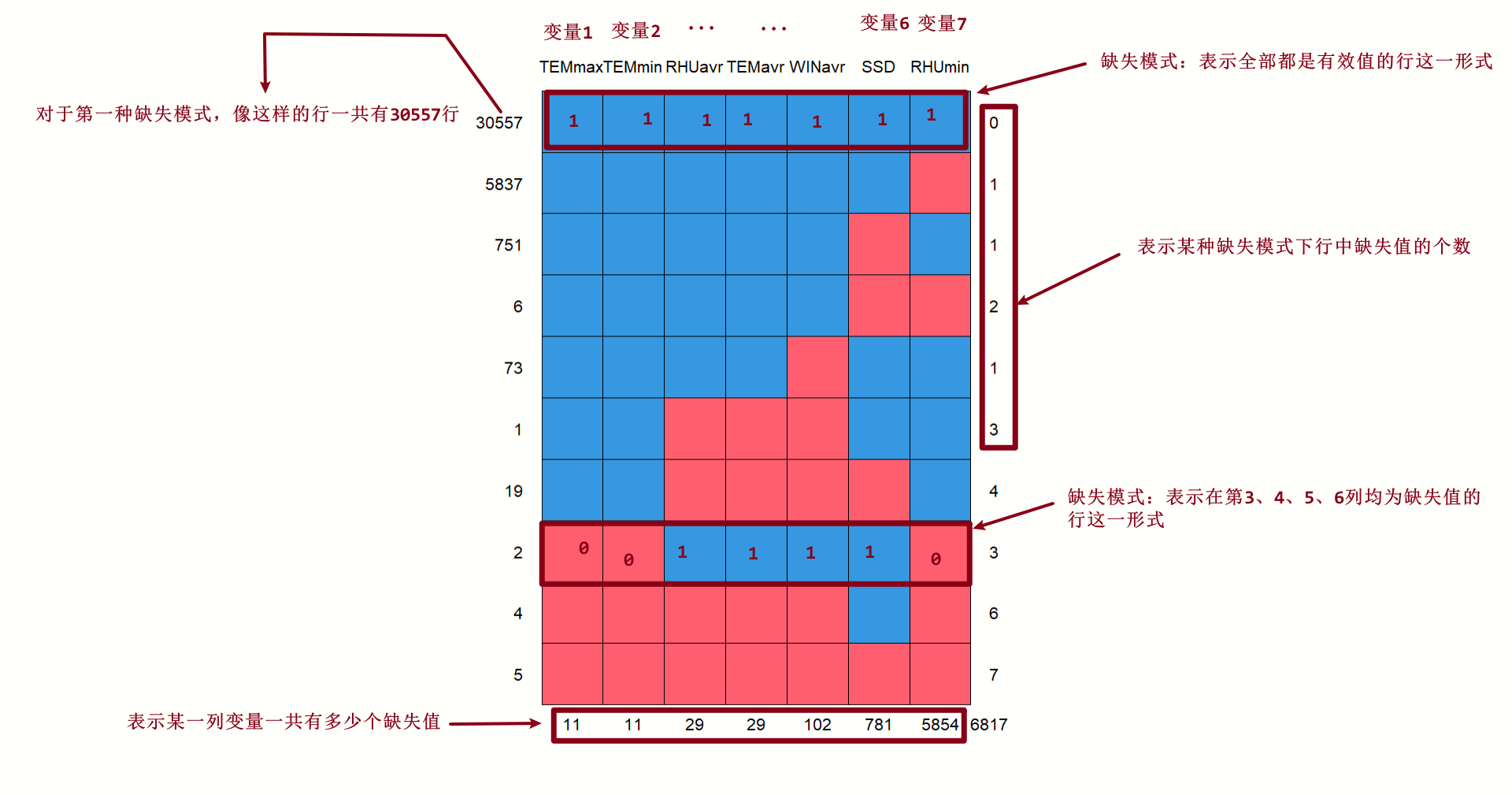
anyNA():表示只要传入的数据框中但凡存在一个缺失值,那么返回True,否则返回False。
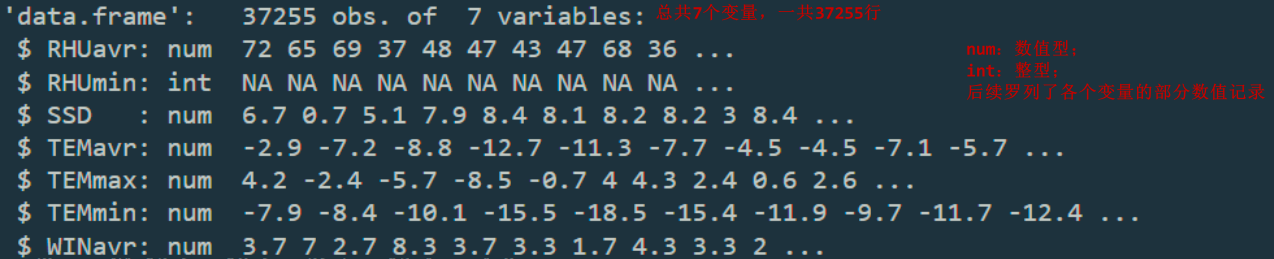
str():输出传入数据框中各个列标签的数值类型和部分内容,注意这里的str不是将其转化为字符串而是输出数据框结构(structure)。运行结果如下:
1.3 插值和输出
miceMod <- mice(mydata, method="rf")#默认为PMM(预测均值匹配),norm(贝叶斯线性回归)、norm.boot(基于bootstrap的线性回归)、norm.predict(线性回归预测值)、cart、rf
summary(miceMod)
miceOutput <- complete(miceMod) # 生成完整数据
anyNA(miceOutput)#> FALSE
miceOutput <- cbind(TJ[,1:8],miceOutput)
write.csv(miceOutput, "TJ_var8_1970-2022_2st_rf.csv",row.names = F)
miceMod <- mice(mydata, method="rf"):表示对其中的缺失值进行插值,插值方法选择随机森林。默认为PMM(预测均值匹配),norm(贝叶斯线性回归)、norm.boot(基于bootstrap的线性回归)、norm.predict(线性回归预测值)、cart、rf。迭代过程如下:
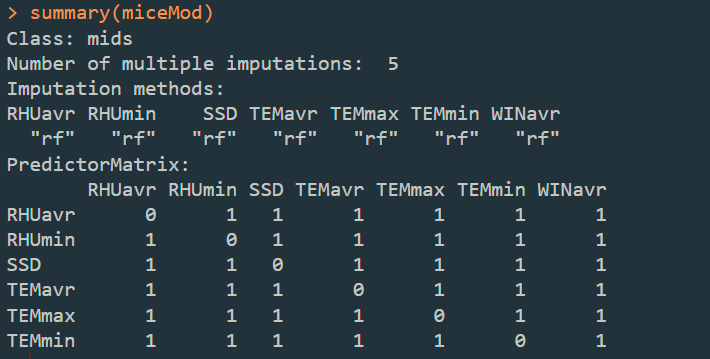
summary(miceMod):用于展示输出插补的一些概要信息,运行结果如下:
miceOutput <- complete(miceMod):生成完整的数据集,将原先的原始数据集中的NA值替换为插值的结果,得到完整无NA的数据集。
anyNA(miceOutput):查看目前完整的数据集是否还存在NA值,保证没有缺失值的存在。
miceOutput <- cbind(TJ[,1:8],miceOutput):将原始数据集TJ的前几列与插值好的相关变量进行列合并。结果如下:
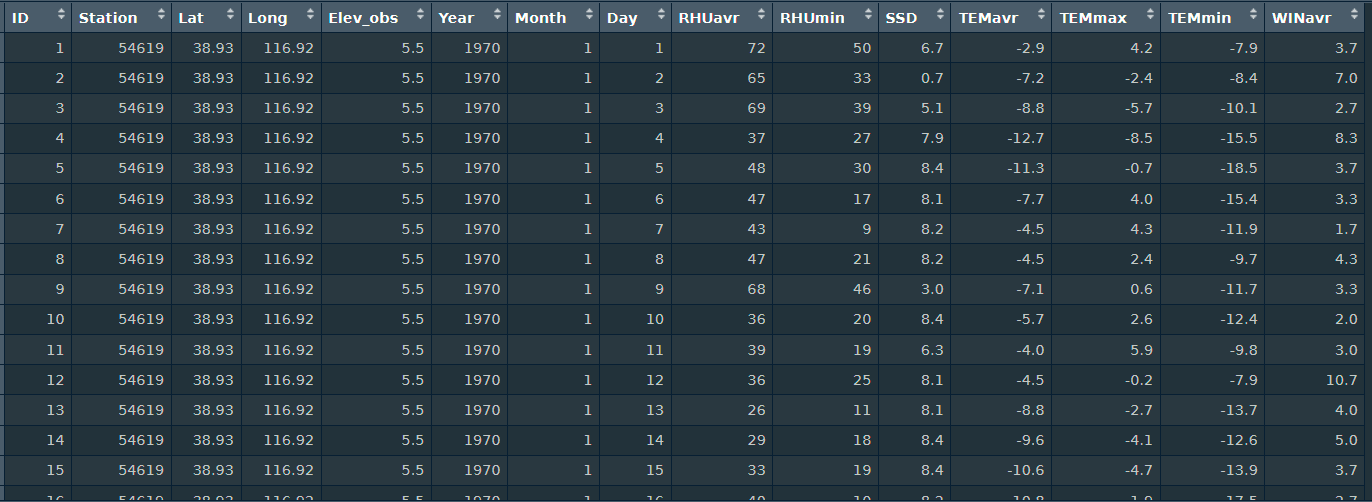
write.csv(miceOutput, "TJ_var8_1970-2022_2st_rf.csv",row.names = F):最后将得到的插值好的数据集输出为csv文件,行索引不加上。
1.4 校验
all(miceOutput$TEMmin <= miceOutput$TEMavr,na.rm = T) #TRUE
all(miceOutput$TEMavr <= miceOutput$TEMmax,na.rm = T) #TRUE
all(miceOutput$RHUmin <= miceOutput$RHUavr,na.rm = T) #FALSE
miceOutput$TEMmin[miceOutput$TEMmin>miceOutput$TEMavr] <- miceOutput$TEMavr[miceOutput$TEMmin>miceOutput$TEMavr]
miceOutput$TEMavr[miceOutput$TEMavr>miceOutput$TEMmax] <- miceOutput$TEMmax[miceOutput$TEMavr>miceOutput$TEMmax]
miceOutput$RHUmin[miceOutput$RHUmin>miceOutput$RHUavr] <- miceOutput$RHUavr[miceOutput$RHUmin>miceOutput$RHUavr]
这里需要说明:miceOutput$TEMmin类似这种是取数据框中列标签为$后的列名称的那一列,即取指定列标签名的所在列。
all(miceOutput$TEMmin <= miceOutput$TEMavr,na.rm = T):若TEMavr所在列全部大于TEMmin 所在列,那么返回True。按理返回True是正常的,因为TEMaver表示平均值,TEMmin表示最小值数据。na.rm表示在进行比较时忽略NA。(至于其他代码类似)
miceOutput$TEMmin[miceOutput$TEMmin>miceOutput$TEMavr] <- miceOutput$TEMavr[miceOutput$TEMmin>miceOutput$TEMavr]表示将最小值大于平均值的那部分最小值用平均值替代。(其他代码类似)
02 常量定义
这些常量会在后续的计算中使用到。
#2. constants
FUN.constants<-data.frame(
pi,
lambda <- 2.45,
sigma <- 4.90E-09,
Gsc <- 0.082,
Roua <- 1.2,
Ca <- 0.001013,
G <- 0,
alphaA <- 0.14,
alphaPT <- 1.26, #for Priestley-Taylor formula
alphaSJ <- 1.31, #for Szilagyi-Jozsa formula
alphaBS <- 1.28, #for Brutsaert-Strickler formula
ap <- 2.4, #in Penpan formula = 2.4
b0 <- 1, #in Morton’s procedure = 1
b1 <- 14, #in Morton’s procedure = 14 W.m^-2
b2 <- 1.2, #in Morton’s procedure = 1.2
epsilonMo<- 0.92, #in Morton’s procedure = 0.92,
sigmaMo <- 5.67E-08, #in Morton’s procedure = 5.67e-08 W.m^-2.K^-4
#end.constants in all places
as <- 0.25, #no observed data in China
bs <- 0.5 #no observed data in China
)
通过data.frame()创建一个数据框,并将其赋值给变量FUN.constants。结果如下:

在对上述变量进行解释时需要对之前的几个变量进行说明:
RHUavr:平均相对湿度(Average Relative Humidity),相对湿度是指空气中水蒸气含量与在同一温度下空气能够容纳的最大水蒸气量的比例。它是影响蒸发潜能的重要因素之一
RHUmin:最小相对湿度(Minimum Relative Humidity),通常指一天中相对湿度的最低值,这个指标有助于了解日内湿度变化的范围。
SSD:日照时数(Sunshine Duration, 这是实际日照时数,h),指一天中太阳光直接照射地面的时间长度,是评估太阳辐射量和进一步估算蒸发潜能的一个重要指标。
TEMavr:平均温度(Temperature),温度直接影响蒸发速率,一般来说,温度越高,蒸发潜能越大。
TEMmax:最高温度(Maximum Temperature),一天中的最高气温,对蒸发量的计算同样重要。
TEMmin:最低温度(Minimum Temperature),一天中的最低气温,结合最高温度,可用于评估日温差对蒸散发的影响。
WINavr: 平均风速(Average Wind Speed,这里指2m高处风速, m/s),风速加快蒸发过程,因为它帮助移走饱和层(空气中水蒸气含量接近饱和的层面),使得更多的水分可以从水面或植被中蒸发。
由于上述常量部分包含蒸散发相关的代码,所以这里只解释与太阳辐射相关变量。
太阳辐射公式:

这是详细说明:

上述常量中:
as:0.25,回归常数,在阴天(n=0)时,表示到达地球表面的地球外辐射的透过系数;
bs:0.50,回归系数,在晴天(n=N)时,as+bs表示到达地球表面的地球外辐射透过率。
对于式中的Ra即日地球外辐射,计算公式如下:

可以解释:
pi:即圆周率Π;
Gsc:太阳常数(为0.0820),单位为兆焦每平方米每分;
其余常数并未在太阳辐射中使用到,这里不予解释。
03 太阳辐射计算
#3. FUN.factor()
FUN.factor <- function(J, Lat, Elev, n, u2, Tmean, Tmax, Tmin, RHmax, RHmin){
e_Tmax <- 0.6108*exp(17.27*Tmax/(Tmax+237.3))
e_Tmin <- 0.6108*exp(17.27*Tmin/(Tmin+237.3))
e_Tmean <- 0.6108*exp(17.27*Tmean/(Tmean+237.3))
es <- (e_Tmax+e_Tmin)/2.0
ea <- (e_Tmin*RHmax/100+e_Tmax*RHmin/100)/2.0 #1???#2 ea <- (RHmax+RHmin)/200.0*es
delta_ <- 0.409*sin(2*pi*J/365-1.39)
dr <- 1+0.033*cos(2*pi*J/365)
phi_ <- pi/180*Lat
omega_s <- acos(-tan(phi_)*tan(delta_))
Ra <- 24*60/pi*Gsc*dr*(omega_s*sin(phi_)*sin(delta_)+cos(phi_)*cos(delta_)*sin(omega_s))
N <- 24*omega_s/pi
Rs <- (as+bs*n/N)*Ra
Rso <- (0.75+2E-05*Elev)*Ra
Rnl <- sigma*((Tmax+273.16)^4+(Tmin+273.16)^4)/2*(0.34-0.14*sqrt(ea))*(1.35*Rs/Rso-0.35)
alpha_ <- 0.23
Rns <- (1-alpha_)*Rs
Rn <- Rns-Rnl
DELTA_ <- 4098*0.6108*exp(17.27*Tmean/(Tmean+237.3))/(Tmean+237.3)^2
gamma_ <- 0.000665*101.3*((293-0.0065*Elev)/293)^5.26
return(cbind(es, ea, Ra, Rs, Rn, DELTA_, gamma_, delta_, dr, phi_, omega_s, N, e_Tmax, e_Tmin, e_Tmean))
}
这里包含了不止太阳辐射的计算,其中涉及太阳辐射Rs的代码式子包括:
delta_ <- 0.409*sin(2*pi*J/365-1.39)
dr <- 1+0.033*cos(2*pi*J/365)
phi_ <- pi/180*Lat
omega_s <- acos(-tan(phi_)*tan(delta_))
Ra <- 24*60/pi*Gsc*dr*(omega_s*sin(phi_)*sin(delta_)+cos(phi_)*cos(delta_)*sin(omega_s))
N <- 24*omega_s/pi
Rs <- (as+bs*n/N)*Ra
delta_为计算的太阳磁偏角,数学公式为:
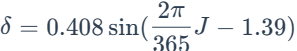
式中,J表示日序,取值范围为1到365或者366,1月1日取日序为1。
dr为计算的日地平均距离,数学公式为:
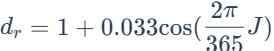
phi_计算的是弧度制的纬度,数学公式为:

omega_s为计算的日出时角,单位为弧度制,数学公式为:

Ra计算的是日地球外辐射,数学公式为:

计算出Ra之后,我们知道,太阳辐射计算公式为:
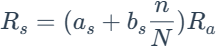
因此,这里需要计算出N,因为as和bs为常数,n作为函数参数提供,Ra在刚刚的式子中进行了计算,而N的计算(下式中ws为前文的omega_s)如下:
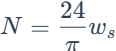
如此,太阳辐射计算即全部完成。
在函数中,需要传入以下参数:
J:日序,取值范围为1到365或者366,1月1日取日序为1。
Lat:纬度(单位为°/度)
Elev:高程/海拔
n:实际日照时数
u2:2m高处风速,m/s
Tmean:平均温度
Tmax:最高温度
Tmin:最低温度
RHmax:最大相对湿度
RHmin:最小相对湿度
04 实例说明
#4. eg
TJ_rf<-read.csv("TJ_var8_1970-2022_2st_rf.csv")
J = NULL
data = TJ_rf[TJ_rf$Station==54619, ]
for (i in 1970:2022){
tj = data[data$Year==i,]
j = seq(1,length(tj$ID),1)
J = c(J, j)
}
data = TJ_rf[TJ_rf$Station==54622, ]
for (i in 1974:2022){
tj = data[data$Year==i,]
j = seq(1,length(tj$ID),1)
J = c(J, j)
}
TJ_rf<-cbind(TJ_rf,J)
TJ_rf_factor<-NULL
Lat <- TJ_rf$Lat
Elev <- TJ_rf$Elev_obs
J <- TJ_rf$J
n <- TJ_rf$SSD
u2 <- TJ_rf$WINavr
Tmin <- TJ_rf$TEMmin
Tmax <- TJ_rf$TEMmax
Tmean <- (TJ_rf$TEMmax + TJ_rf$TEMmin)/2.0 #not a Temp
RHmax <- 2*TJ_rf$RHUavr-TJ_rf$RHUmin
RHmin <- TJ_rf$RHUmin
RHmean <- TJ_rf$RHUavr
TJ_rf_factor<-cbind(TJ_rf,FUN.factor(J, Lat, Elev, n, u2, Tmean, Tmax, Tmin, RHmax, RHmin)) #return 25 values
write.csv(TJ_rf_factor,"TJ_var8_1970-2022_2st_rf_Rs.csv", row.names = F)
下述这部分代码意在读取csv文件,并分别筛选出站点ID为54619和54622(csv文件仅只有这两个站点的记录)的所有行记录,然后为每一行记录生成J即日序值。
TJ_rf<-read.csv("TJ_var8_1970-2022_2st_rf.csv")
J = NULL
data = TJ_rf[TJ_rf$Station==54619, ]
for (i in 1970:2022){
tj = data[data$Year==i,]
j = seq(1,length(tj$ID),1)
J = c(J, j)
}
data = TJ_rf[TJ_rf$Station==54622, ]
for (i in 1974:2022){
tj = data[data$Year==i,]
j = seq(1,length(tj$ID),1)
J = c(J, j)
}
下述代码将读取csv文件中的数据与前面计算的日序J进行列拼接,然后分别提取出各个需要的列变量,最后将其传入前面编写的FUN.factor函数中进行各种辐射的计算,包括本篇所说的太阳辐射。接着将得到的结果与前文数据框进行列合并,最后输出为csv文件。
TJ_rf<-cbind(TJ_rf,J)
TJ_rf_factor<-NULL
Lat <- TJ_rf$Lat
Elev <- TJ_rf$Elev_obs
J <- TJ_rf$J
n <- TJ_rf$SSD
u2 <- TJ_rf$WINavr
Tmin <- TJ_rf$TEMmin
Tmax <- TJ_rf$TEMmax
Tmean <- (TJ_rf$TEMmax + TJ_rf$TEMmin)/2.0 #not a Temp
RHmax <- 2*TJ_rf$RHUavr-TJ_rf$RHUmin
RHmin <- TJ_rf$RHUmin
RHmean <- TJ_rf$RHUavr
TJ_rf_factor<-cbind(TJ_rf,FUN.factor(J, Lat, Elev, n, u2, Tmean, Tmax, Tmin, RHmax, RHmin)) #return 25 values
write.csv(TJ_rf_factor,"TJ_var8_1970-2022_2st_rf_Rs.csv", row.names = F)