实验2 字符级RNN分类实验
必做题:
(1)数据准备:academy_titles.txt为“考硕考博”板块的帖子标题,job_titles.txt为“招聘信息”板块的帖子标题,将上述两个txt进行划分,其中训练集为70%,测试集为30%。二分类标签:考硕考博为0,招聘信息为1。字符使用One-hot方法表示。
(2)设计模型:在训练集上训练字符级RNN模型。注意,字符级不用分词,是将文本的每个字依次送入模型。
(3)将训练好的模型在测试数据集上进行验证,计算准确率,并分析实验结果。要给出每一部分的代码。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.model_selection import train_test_split
# 读取academy_titles文件内容
with open('C:\\Users\\hp\\Desktop\\academy_titles.txt', 'r', encoding='utf-8') as file:
academy_titles = file.readlines()
# 读取job_titles文件内容
with open('C:\\Users\\hp\\Desktop\\job_titles.txt', 'r', encoding='utf-8') as file:
job_titles = file.readlines()
# 将招聘信息与学术信息分开
academy_titles = [title.strip() for title in academy_titles]
job_titles = [title.strip() for title in job_titles]
# 构建标签和数据
X = academy_titles + job_titles
y = [0] * len(academy_titles) + [1] * len(job_titles)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建字符到索引的映射
all_chars = set(''.join(academy_titles + job_titles))
char_to_index = {char: i for i, char in enumerate(all_chars)}
# 将文本转换为模型可接受的输入形式
def text_to_input(text, max_len, char_to_index):
X_indices = np.zeros((len(text), max_len, len(char_to_index)), dtype=np.float32)
for i, title in enumerate(text):
for t, char in enumerate(title):
X_indices[i, t, char_to_index[char]] = 1
return torch.tensor(X_indices)
max_len = max([len(title) for title in X])
X_train_indices = text_to_input(X_train, max_len, char_to_index)
X_test_indices = text_to_input(X_test, max_len, char_to_index)
# 构建字符级RNN模型
class CharRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(CharRNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.LSTM(input_size, hidden_size)
self.fc = nn.Linear(hidden_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden, _ = self.i2h(input)
output = self.fc(hidden[-1])
output = self.sigmoid(output)
return output
model = CharRNN(input_size=len(char_to_index), hidden_size=128)
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 转换数据为PyTorch张量
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
# 定义新的训练周期数和学习率
num_epochs = 30
learning_rate = 0.01
# 定义新的优化器
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
best_accuracy = 0.0
best_model = None
# 训练模型并输出每一轮的准确率
for epoch in range(num_epochs):
optimizer.zero_grad()
output = model(X_train_indices)
output = output.view(-1, 1)
loss = criterion(output, y_train_tensor[:output.size(0)])
loss.backward()
optimizer.step()
# 计算训练集准确率
predictions = (output > 0.5).float()
correct = (predictions == y_train_tensor[:output.size(0)]).float()
accuracy = correct.sum() / len(correct)
print(f'Epoch {epoch+1}, 训练集准确率: {accuracy.item()}')
# 保存准确率最高的模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model.state_dict().copy()
# 加载最佳模型参数
model.load_state_dict(best_model)
# 使用测试集上准确率最高的模型进行测试
test_output = model(X_test_indices)
test_output = test_output.view(-1, 1)
test_loss = criterion(test_output, y_test_tensor[:test_output.size(0)])
predictions = (test_output > 0.5).float()
correct = (predictions == y_test_tensor[:test_output.size(0)]).float()
accuracy = correct.sum() / len(correct)
print(f'使用测试集上准确率最高的模型进行测试,准确率: {accuracy.item()}')
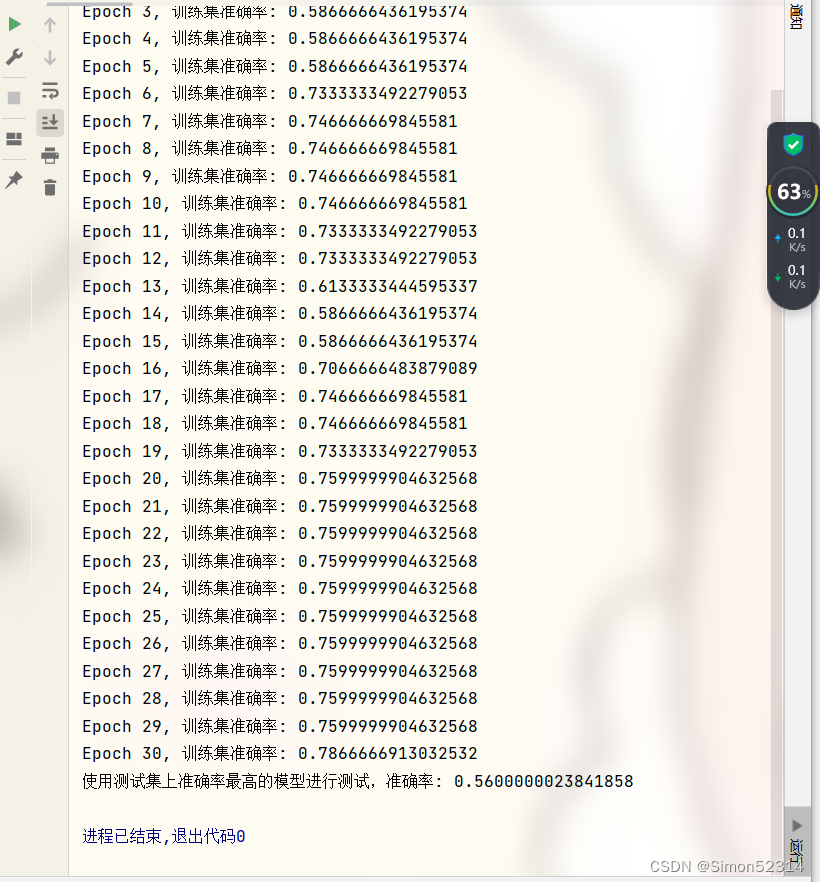 这个实验准确率目前是偏低的,但是我没有很多时间去一直调整参数
这个实验准确率目前是偏低的,但是我没有很多时间去一直调整参数
希望后面有需要的同学,可以去调整参数!