大家好,我是带我去滑雪!
地质灾害的预测对于人们的生命财产安全、社会稳定和经济发展具有重要意义。地质灾害如地震、泥石流、山体滑坡等往往会造成严重的人员伤亡和财产损失。大规模的地质灾害往往会导致社会秩序混乱、人员流动、灾民避难等问题,影响社会的稳定和治安。地质灾害预测可以帮助人们避免在高风险地区建设,合理规划城市和土地利用,避免浪费资源并保护生态环境。
基于逻辑回归与决策树的地质灾害预测是一种常见的预测模型,结合了两种不同的机器学习算法,可以有效地预测地质灾害的发生概率和可能的影响因素。逻辑回归是一种用于解决分类问题的线性模型。它通过将特征的线性组合与Sigmoid函数结合来进行分类预测。在地质灾害预测中,逻辑回归可以用来分析不同地质因素(如地形、地质构造、降水等)对灾害发生的影响,并建立模型预测地质灾害的发生概率。例如,可以利用历史地质灾害数据和相关地质因素,训练逻辑回归模型来预测未来某地区发生地质灾害的可能性。决策树是一种基于树结构的分类和回归模型。它通过对数据集进行递归地划分,选择最优的特征来进行预测。在地质灾害预测中,决策树可以用来识别不同地质条件下地质灾害的可能性,并提供可解释的规则和决策路径。例如,可以利用决策树模型根据地质构造、地下水情况、地表覆盖等因素来评估地质灾害的潜在风险,并指导相关的防灾减灾工作。
将逻辑回归与决策树结合在地质灾害预测中,可以综合利用它们各自的优势,提高预测的准确性和可解释性。例如,可以先使用逻辑回归分析地质因素的影响,然后利用决策树根据这些因素建立预测模型,并生成可解释的规则和决策路径,从而为地质灾害的预防和应对提供科学依据和决策支持。下面开始代码实战。
目录
(1)导入相关模块和库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
get_ipython().run_line_magic('matplotlib', 'inline')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
import warnings
import seaborn as sns
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False (2)导入数据
data = pd.read_csv(r'E:\工作\硕士\博客\博客粉丝问题\data.csv',encoding="utf-8")
print(data)
data.info()#查看数据输出结果:
geologic structure human activity underground water susceptibility 0 0 1 1 1 1 0 1 1 1 2 0 1 1 1 3 0 0 1 1 4 0 1 1 1 .. ... ... ... ... 207 1 1 1 1 208 1 1 0 1 209 1 1 1 1 210 0 1 0 1 211 1 1 1 1 [212 rows x 4 columns] <class 'pandas.core.frame.DataFrame'> RangeIndex: 212 entries, 0 to 211 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 geologic structure 212 non-null int64 1 human activity 212 non-null int64 2 underground water 212 non-null int64 3 susceptibility 212 non-null int64 dtypes: int64(4) memory usage: 6.8 KB
(3)划分训练集和测试集并进行标准化
#划分训练集和验证集
y=data.iloc[:,-1]
print(y)
X=data.iloc[:,:-1]
size=np.arange(0.1,1,0.1)
scorelist=[[],[],[],[]]
from sklearn.model_selection import train_test_split
for i in range(0,9):
train_X, test_X, train_y, test_y = train_tst_split(X ,
y,
train_size=size[i],
random_state=76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
train_X = sc.fit_transform(train_X)
test_X = sc.transform(test_X)(3)构建决策树模型和逻辑回归模型
#逻辑回归
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit( train_X , train_y )
scorelist[].append(model.score(test_X , test_y ))
#决策树
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(train_X, train_y)
scorelist[1].append(model.score(test_X,test_y))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minu'] = False
color_list = ('red', 'blue')
for i in range(0,2):
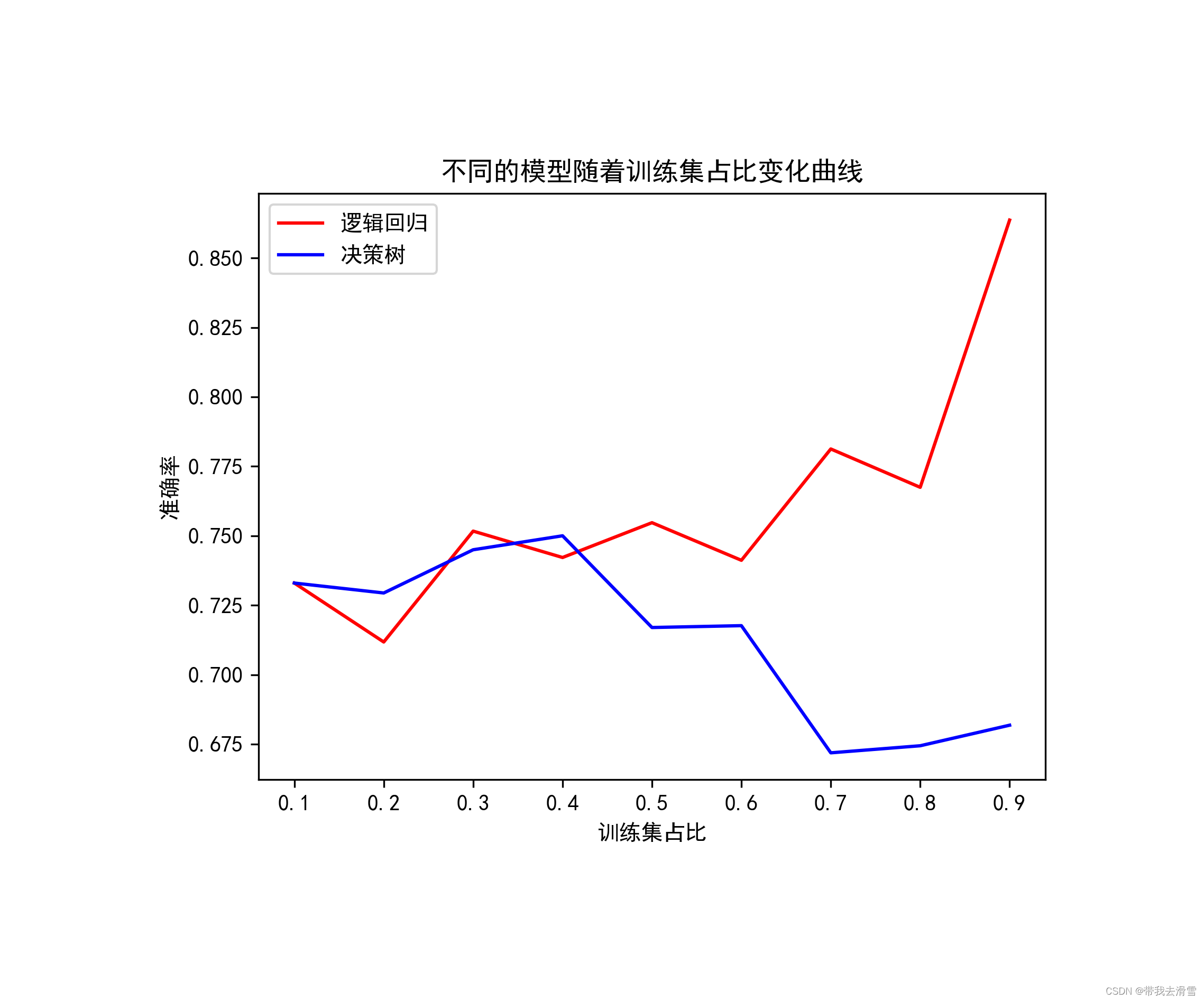
plt.plot(size,scorelist[i],color=color_list[i])
plt.legend(['逻辑回归', '决策树'])
plt.xlabel('训练集占比')
plt.ylabel('准确率')
plt.title('不同的模型随着训练集占比变化曲线')
plt.savefig(r'E:\工作\硕士\博客\博客粉丝问题\对比图.png',
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果展示:
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/173deLlgLYUz789M3KHYw-Q?pwd=0ly6
提取码:2138
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!

























![[Redis]——Redis持久化的两种方式RDB、AOF](https://img-blog.csdnimg.cn/direct/2dcfc522601b482e99eb71bdc5bb06d5.png)