文档处理
Excel电子表格
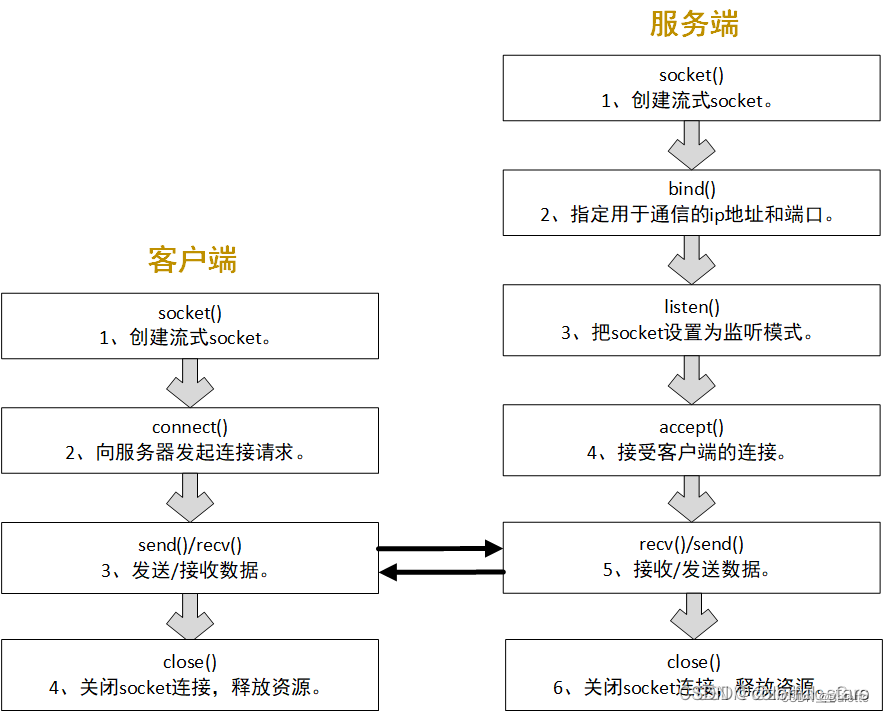
Python 的 openpyxl 模块让我们可以在 Python 程序中读取和修改 Excel 电子表格,由于微软从 Office 2007 开始使用了新的文件格式,这使得 Office Excel 和 LibreOffice Calc、OpenOffice Calc 是完全兼容的,这就意味着 openpyxl 模块也能处理来自这些软件生成的电子表格。
创建 excel 文件
开始使用 openpyxl 时,无需在文件系统中创建文件,只要导入 workbook 类就可以了。
from openpyxl import Workbook
wb = Workbook()至少有一个工作表在工作簿创建后,可以通过 Workbook.active 属性来定位到工作表。
ws = wb.active该工作簿的默认索引是从0开始。除非索引值被修改,否则使用这个方法将总是获取第一个工作表。
可以使用 Workbook.create_sheet() 方法来创建新工作表。
ws1 = wb.create_sheet("Mysheet") # 插入到最后 (默认)
ws2 = wb.create_sheet("Mysheet", 0) # 插入到最前
ws3 = wb.create_sheet("Mysheet", -1) # 插入到倒数第二工作表将在创建时按照数字序列自动命名(如 Sheet,Sheet1,Sheet2,……)。可以在任何时候通过 Worksheet.title 属性修改工作表名:
ws.title = "New Title"
创建的工作表的标签背景色默认是白色。可以通过在 Worksheet.sheet_properties.tableColor 对象中设置 RRGGBB 格式的颜色代码进行修改:
ws.sheet_properties.tabColor = "1072BA"
当设置了 worksheet 名称,可以将名称作为工作表的索引:
ws3 = wb["New Title"]
可以通过 Workbook.sheetname 对象来查看工作簿中所有工作表的名称
print(wb.sheetnames)
['Sheet2', 'New Title', 'Sheet1']
可以遍历整个工作簿:
for sheet in wb:
print(sheet.title)
可以使用 Workbook.copy_worksheet() 方法来创建一个工作簿中所有表的副本:
source = wb.active
target = wb.copy_worksheet(source)
只有单元格(包括值、样式、超链接、备注)和一些工作表对象(包括尺寸、格式和参数)会被复制。其他属性不会被复制,如图片、图表。
无法在两个工作簿中复制工作表。当工作簿处于只读或只写状态时也无法复制工作表。
访问一个单元格
现在我们知道如何获取一个工作表,我们可以开始修改单元格内容。单元格可以通过工作表中的索引直接访问:
c = ws['A4']
这将返回位于“A4”的单元格内容,如果不存在则创建一个。可以直接对单元格进行赋值:
ws['A4'] = 4
这是 Worksheet.cell() 的方法。
工具支持通过行列号访问单元格:
d = ws.cell(row=4, column=2, value=10)
当在内存中创建工作表后,表中不包含任何单元格。单元格将在第一次访问时创建。
因为这种特性,遍历而不是访问这些单元格将在内存中全部创建它们,即使并没有给它们赋值。比如说:
for x in range(1,101):
for y in range(1,101):
ws.cell(row=x, column=y)
访问多个单元格
可以通过切片访问一个范围内的单元格:
cell_range = ws['A1':'C2']
行或列的单元格也可以通过类似的方法访问:
colC = ws['C']
col_range = ws['C:D']
row10 = ws[10]
row_range = ws[5:10]
同样也可以使用 Worksheet.iter_rows() 方法:
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
for cell in row:
print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.B1>
<Cell Sheet1.C1>
<Cell Sheet1.A2>
<Cell Sheet1.B2>
<Cell Sheet1.C2>
类似的,使用 Worksheet.iter_cols() 方法将返回列:
for col in ws.iter_cols(min_row=1, max_col=3, max_row=2):
for cell in col:
print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.A2>
<Cell Sheet1.B1>
<Cell Sheet1.B2>
<Cell Sheet1.C1>
<Cell Sheet1.C2>
出于性能考虑,
Worksheet.iter_cols()方法不支持在只读模式使用
如果需要遍历文件内的所有行和列,可以使用 Worksheet.rows 属性:
ws = wb.active
ws['C9'] = 'hello world'
tuple(ws.rows)
((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>),
(<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>),
(<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>),
(<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>),
(<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>),
(<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>),
(<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>),
(<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>),
(<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
或者 Worksheet.columns 属性
tuple(ws.columns)
((<Cell Sheet.A1>,
<Cell Sheet.A2>,
<Cell Sheet.A3>,
<Cell Sheet.A4>,
<Cell Sheet.A5>,
<Cell Sheet.A6>,
...
<Cell Sheet.B7>,
<Cell Sheet.B8>,
<Cell Sheet.B9>),
(<Cell Sheet.C1>,
<Cell Sheet.C2>,
<Cell Sheet.C3>,
<Cell Sheet.C4>,
<Cell Sheet.C5>,
<Cell Sheet.C6>,
<Cell Sheet.C7>,
<Cell Sheet.C8>,
<Cell Sheet.C9>))
出于性能原因,
Worksheet.columns属性不支持只读模式
取值
如果只需要从工作表中获取值,可以使用 Worksheet.values 属性。这将遍历工作表中所有行,但只返回单元格值:
for row in ws.values:
for value in row:
print(value)
Worksheet.iter_rows() 和 Worksheet.iter_cols() 可以只返回单元格值:
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True):
print(row)(None, None, None)
(None, None, None)
赋值
当我们创建了一个单元格对象,我们可以对其赋值:
c.value = 'hello, world'
print(c.value)
d.value = 3.14
print(d.value)
'hello, world'
3.14
保存
对 Workbook 对象使用 Workbook.save() 方法可以简单安全的保存工作簿:
wb = Workbook()
wb.save('test.xlsx')
该操作将覆盖同名文件,而不会有任何警告
读取文件
和写操作一样,可以使用 openpyxl.load_workbook() 打开存在的工作簿:
from openpyxl import load_workbook
wb2 = load_workbook('test.xlsx')
print wb2.sheetnames['Sheet2', 'New Title', 'Sheet1']





















![[LeetCode][LCR169]招式拆解 II——巧妙利用字母的固定顺序实现查找复杂度为O(1)的哈希表](https://img-blog.csdnimg.cn/direct/5250460aa7c04ad894586eb58d47aee6.png)