leetcode 438. 找到字符串中所有字母异位词
俺的图图呢

leetcode 438. 找到字符串中所有字母异位词 | 中等难度
1. 题目详情
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
输入: s = “cbaebabacd”, p = “abc”
输出: [0,6]
解释:
起始索引等于 0 的子串是 “cba”, 它是 “abc” 的异位词。
起始索引等于 6 的子串是 “bac”, 它是 “abc” 的异位词。
示例 2:
输入: s = “abab”, p = “ab”
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 “ab”, 它是 “ab” 的异位词。
起始索引等于 1 的子串是 “ba”, 它是 “ab” 的异位词。
起始索引等于 2 的子串是 “ab”, 它是 “ab” 的异位词。
提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
1. 原题链接
2. 基础框架
● Cpp代码框架
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
}
};
2. 解题思路
1. 题目分析
( 1 ) (1) (1) 本题要求找到字符串s中是字符串p的异位词的所有起始下标。
( 2 ) (2) (2) 在思考解法之前先来考虑这样一个问题:如何比较两个字符串s1,s2是否是异位词?
解法1:先分别对两个字符串进行排序,然后同时遍历这两个字符串,依次判断字符是否相等;
时间复杂度是 O ( n ∗ l o g 2 n ) O(n*log_2n) O(n∗log2n),时间复杂度比 O ( n 2 ) O(n^2) O(n2)好,但还是太高;
解法2:既然是判断异位词,只需要考虑对应字符出现的次数是否相等即可,不需要考虑字符顺序,不必对其进行排序,而是使用两个哈希表建立字符与出现次数的映射,分别遍历两个字符串,对应字符出现的次数保存在哈希表中,再来一次遍历,比较两个哈希表中字符出现的次数是否相等即可,时间复杂度 O ( n ) O(n) O(n)。
( 3 ) (3) (3) 现在思考如何kill本题:
还是先暴力枚举:
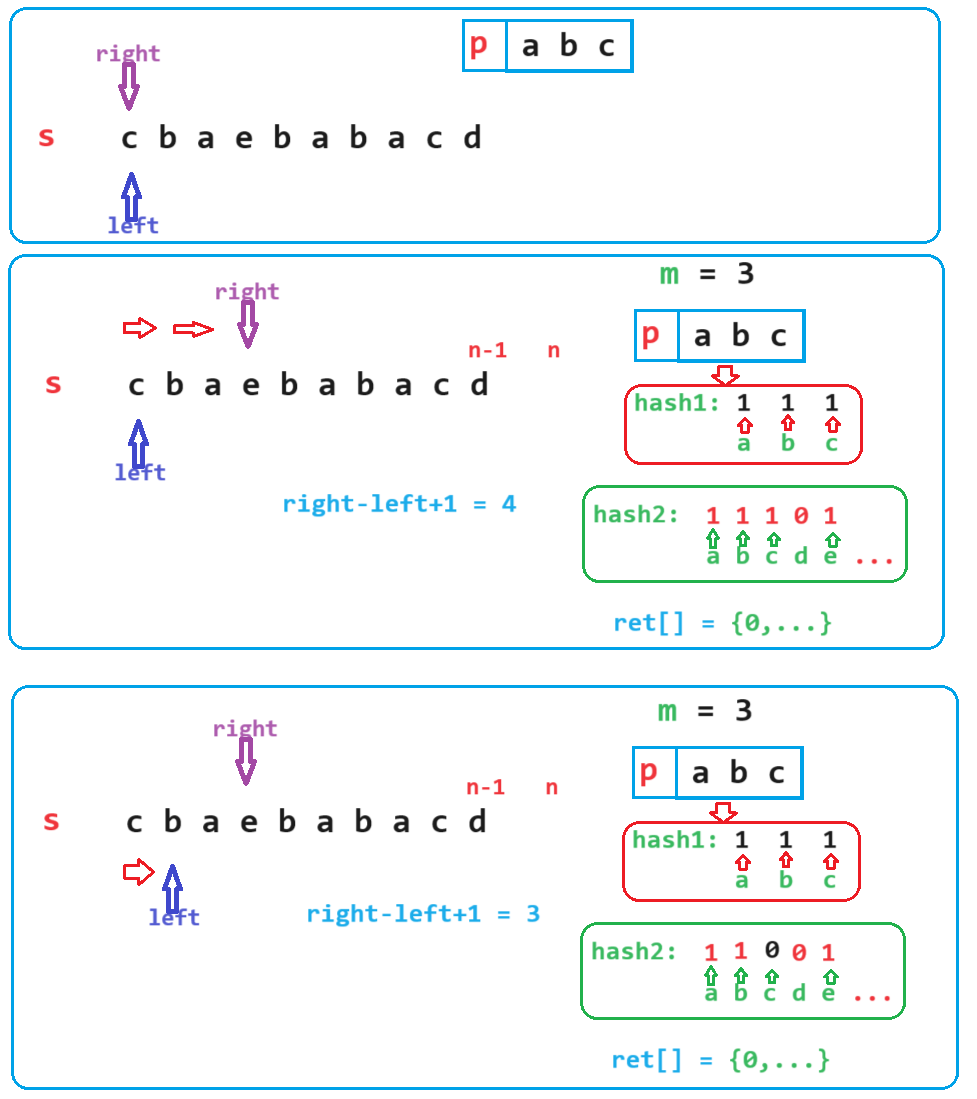
设字符串s的长度为n,p的长度为m,哈希表1hash1记录p中字符出现的次数,哈希表2hash2记录遍历s时的子串字符出现的次数;
固定left作为起始位置,right从left位置开始向右依次遍历,每次遍历进行判断:
如果right-left+1 < m,说明当前[left, right]范围的字符串长度小于p的长度m,一定不是异位词,故不需要进行比较,right++即可;
如果right-left+1 == m,此时子串的长度恰好等于p的长度m,此时进行是否是异位词的比较:遍历两个哈希表hash1和hash2,比较对应元素出现次数是否相等:
——如果相等则子串就是异位词,把起始下标尾插入结果数组ret中;
——如果不相等,则子串[left,right]不是异位词,那么以right及其之后位置为结尾的子串也不可能是异位词,所以也就没有了遍历的必要;可以直接开始以新left为起始位置,哈希表2hash2清空,right回退,并重新进行遍历了。
如果right-left+1 > m,子串也不可能是异位词,所以也就没有了遍历的必要;可以直接开始以新left为起始位置,哈希表2hash2清空,right回退,并重新进行遍历了。
( 4 ) (4) (4)
2. 算法原理
( 1 ) (1) (1) 对暴力枚举的优化:
设字符串s的长度为n,p的长度为m,哈希表1hash1记录p中字符出现的次数,哈希表2hash2记录遍历s时的子串字符出现的次数;
固定left作为起始位置,right从left位置开始向右依次遍历;
假设某一次遍历,right位置元素进入哈希表后,[left,right]范围内长度恰好大于m,我们定格在此:
对于暴力枚举:子串[left, right]一定不是p的异位词,所以需要以新的left,继续重新开始遍历,对应的哈希表hash2会清空,right会回退到新的left位置。
可是真的需要进行清空hash2和right回退操作吗?
由假设当前right位置恰好大于m,故[left,right-1]范围元素恰好等于m,那么[left+1, right-1]范围长度就是是m-1,假设left右移1位,要想新的子串[left+1, right]满足恰好等于m,当前的right就无须移动,即使right回退到新left位置重新遍历,最后right还是会回到回退之前的位置,哈希表2hash2还是会进入上一次被清空的数。
( 2 ) (2) (2) 在子串left, right]范围恰好等于m时进行异位词的判断:
如果直接遍历两个哈希表判断时间复杂度是 O ( 26 n ) O(26n) O(26n),本题中哈希表使用26长度的数组替代,26是个常数可以忽略,但是如果哈希表中放入的是类似字符串的数据,这时时间复杂度就不是 O ( n ) 了 O(n)了 O(n)了。
所以需要对异位词判断流程再次进行优化:
新增一个计数变量count,用于记录子串中有效字符的个数。
这里的有效字符指的是在子串中出现且在p中出现且hash2中该字符计数不超过hash1中该字符计数时,该字符才是有效字符并进行计数。
进窗口,对于新元素s[right],hash2计数先++,如果hash2[s[right]-'a'] <=hash1[s[right]-'a'],那么count计数++;
判断:子串[left, right]范围长度是否大于m:
出窗口:如果大于m,说明子串长度太长,left需要右移,并移除多余元素。在移除之前额外判断count计数是否也需要–,因为可能会移除有效字符:如果hash2[s[left]-'a']<=hash1[s[left]-'a'],说明将要移除的元素是有效字符,过count需要–;
更新结果:在有效字符计数count==m时,说明s的[left,right]子串是p的异位词,把起始下标left加入结果数组ret中即可;
right++,为下一次字符进入窗口做准备;
( 3 ) (3) (3)
3. 时间复杂度
暴力枚举 O ( n 2 ) O(n^2) O(n2)
滑动窗口 O ( n ) O(n) O(n)
left和right都只向右移动,right移动到字符串s末尾就停下来,循环内的只有判断异位词时可能出现多次判断,但可以通过加一个有效字符计数来避免。总体时间复杂度是 O ( n ) O(n) O(n)
3. 代码实现
遍历方式判断是否是异位词
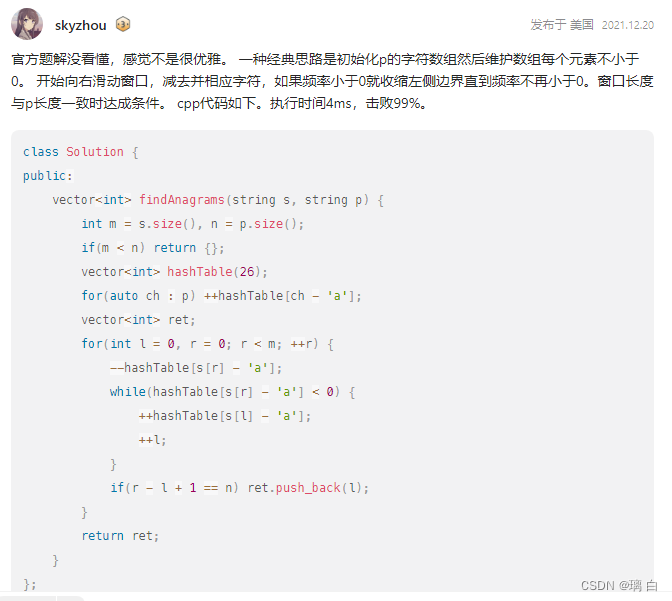
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int hash1[26] = { 0 };
int hash2[26] = { 0 };
for(auto e : p) hash1[e - 'a']++;
vector<int> ret;
int l = 0, r = 0;
int n = s.size(), m = p.size();
while(r < n){
hash2[s[r] - 'a']++;
while(r - l + 1 > m){
hash2[s[l] - 'a']--;
l++;
}
if(r - l + 1 == m){
int flag = 1;
for(int i = 0; i < m; i++){
if(hash1[p[i] - 'a'] != hash2[p[i] - 'a']) {
flag = 0;
break;
}
}
if(flag) ret.push_back(l);
}
r++;
}
return ret;
}
};
有效字符计数方式判断是否是异位词
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int hash1[26] = { 0 };//统计字符串p中字符出现的个数
for(auto e : p) hash1[e - 'a']++;
int hash2[26] = { 0 };//统计滑动窗口里字符出现的子树
vector<int> ret;
int l = 0, r = 0;
int count = 0;//记录窗口中的有效字符
int n = s.size(), m = p.size();
while(r < n){
char in = s[r];
hash2[in - 'a']++;//进窗口
if(hash2[in - 'a'] <= hash1[in - 'a']) count++;//维护count
if(r - l + 1 > m){//判断
char out = s[l]
if(hash2[out - 'a'] <= hash1[out - 'a']) count--;//维护count
hash2[out - 'a']--;//出窗口
l++;
}
if(count == m) ret.push_back(l);//更新结果
r++;
}
return ret;
}
};
4. 知识与收获
( 1 ) (1) (1) 本题题目很短,但内容还是不少的。除了基本的滑动窗口思想之外,对于字符串异位词的判断也使用哈希表进行了优化,特别是引入了有效字符计数count来进一步减少遍历哈希表,以便可以直接通过count和m是否相等直接进行判断。
T h e The The E n d End End