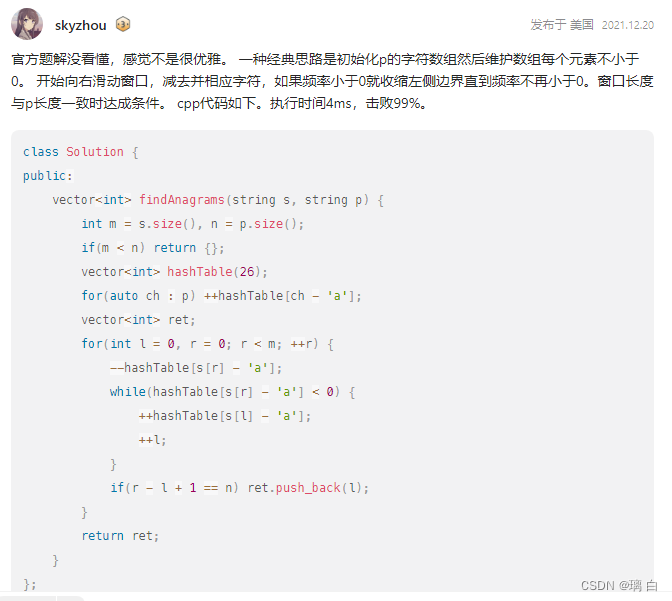
1.问题描述
给定两个字符串 s 和 p,找到 s 中所有 p 的「异位词」的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
提示:
- s 和 p 仅包含小写字母
2.难度等级
Medium。
3.热门指数
★★★★☆
出题公司:阿里、腾讯、字节。
4.解题思路
方法一:暴力法
容易想到的解法是遍历字符串的所有字符,判断每个字符为起点、长度为 len§ 的子串是否是异位词。
如何判断是否是异位词呢?
异位词指由相同字母重排列形成的字符串(包括相同的字符串)。
通过定义,我们可以知道如果构成字符串的字母相同,且每个字母出现的次数相同,则为异位词。
关于数据结构的选择,可以使用 map 存储字母及其出现的个数。
时间复杂度: 这种解法的空间复杂度很高 O(len(s)*len(p))。
空间复杂度: O(len(p))。
注意:这种解法可以通过测试用例,但会超时。
下面以 Golang 为给出实现。
func findAnagrams(s string, p string) []int {
pmap := make(map[rune]int)
for _, r := range p {
pmap[r] += 1
}
var positions []int
for i := 0; i <= len(s) - len(p); {
smap := make(map[rune]int)
var jump bool
for j := i; j - i < len(p); j++ {
if _, ok := pmap[rune(s[j])]; !ok {
i = j+1
jump = true
break
}
smap[rune(s[j])] += 1
}
if !jump {
if maps.Equal(pmap, smap) {
positions = append(positions, i)
}
i++
}
}
return positions
}
方法二:滑动窗口
因为字符串 p 的异位词的长度一定与字符串 p 的长度相同,所以我们可以在字符串 s 中构造一个长度为与字符串 p 的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量;当窗口中每种字母的数量与字符串 p 中每种字母的数量相同时,则说明当前窗口为字符串 p 的异位词。
在算法的实现中,我们可以使用数组来存储字符串 p 和滑动窗口中每种字母的数量。
当字符串 s 的长度小于字符串 p 的长度时,字符串 s 中一定不存在字符串 p 的异位词。但是因为字符串 s 中无法构造长度与字符串 p 的长度相同的窗口,所以这种情况需要单独处理。
复杂度分析: O(m+(n−m)×Σ),其中 n 为字符串 s 的长度,m 为字符串 p 的长度,Σ 为所有可能的字符数。我们需要 O(m) 来统计字符串 p 中每种字母的数量;需要 O(m) 来初始化滑动窗口;需要判断 n−m+1 个滑动窗口中每种字母的数量是否与字符串 p 的相同,每次判断需要 O(Σ)。因为 s 和 p 仅包含小写字母,所以 Σ=26。
空间复杂度: O(Σ)。用于存储字符串 p 和滑动窗口中每种字母的数量。
func findAnagrams(s string, p string) []int {
if len(s) < len(p) {
return nil
}
var indices []int
var sCount, pCount [26]int
// 初始化字符串 p 中每种字母的数量。
// 初始化滑动窗口中每种字母的数量。
for i := 0; i < len(p); i++ {
sCount[s[i]-'a']++
pCount[p[i]-'a']++
}
if sCount == pCount {
indices = append(indices, 0)
}
for i := range s[:len(s)-len(p)] {
// 向右移动滑动窗口,移动一个字母。
sCount[s[i]-'a']--
sCount[s[i+len(p)]-'a']++
if sCount == pCount {
indices = append(indices, i+1)
}
}
return indices
}
方法三:滑动窗口
在方法一的基础上,我们不再分别统计滑动窗口和字符串 p 中每种字母的数量,而是统计滑动窗口和字符串 p 中每种字母数量的差。也就是将两个记录字母出现次数的数组变成一个记录字母不同的数组。
并引入变量 differ 来记录当前窗口与字符串 p 中数量不同的字母的个数,并在滑动窗口的过程中维护它。
在判断滑动窗口中每种字母的数量与字符串 p 中每种字母的数量是否相同时,只需要判断 differ 是否为零即可。
- 首先还是可以理解成初始化,如果字符串 s 前 pLen 个字母有该字母就加1,字符串 p 有则减1。
- 然后遍历数组计算字母数不同的字母的个数 differ。
- 然后进入到滑动窗口,上面的方法是直接减 sCount 的次数,而这里如果要减 Count 的次数,要保证 differ 的次数正确,所以分了两种情况:
- 第一种是第 i 个字母是 1,也就是字符串 s 在 i 位置的字母比 p 多了 1 个,这时如果去掉这个字母的话,differ 就要 -1。
- 第二种是第 i 个字母是 0,说明这个字母 s 和 p 中都有,如果去掉这个的话 differ 就要 +1。
- 上述操作结束后,就可以安心将 Count[i] 减 1 了。
- 同样地,移动滑动窗口,将第 i+pLen 位置的字母加入窗口,也是两种。
- 第一种情况是第 i+pLen 个的字母数相差 -1,说明子字符串和 p 之间就差了这一个字母,加入这个字母后,differ-1。
- 第二种情况是第 i+pLen 个的字母数相差 0,说明子字符串不需要这个字母,differ+1。
- 结束之后在 i+pLen 位置的 Count+1,表示多了一个这个字母。
- 最后如果 differ 为 0,就可以算为一个答案了。
时间复杂度: O(n+m+Σ),其中 nnn 为字符串 sss 的长度,mmm 为字符串 ppp 的长度,其中Σ\SigmaΣ 为所有可能的字符数。我们需要 O(m) 来统计字符串 p 中每种字母的数量;需要 O(m) 来初始化滑动窗口;需要 O(Σ) 来初始化 differ;需要判断 n−m+1 个滑动窗口内每种字母的数量是否与字符串 p 的相同,每次判断需要 O(1)。因为 s 和 p 仅包含小写字母,所以 Σ=26。
空间复杂度: O(Σ)。用于存储滑动窗口和字符串 p 中每种字母数量的差。
下面以 Golang 为例给出实现。
func findAnagrams(s, p string) (ans []int) {
sLen, pLen := len(s), len(p)
if sLen < pLen {
return
}
count := [26]int{
}
for i, ch := range p {
count[s[i]-'a']++
count[ch-'a']--
}
differ := 0
for _, c := range count {
if c != 0 {
differ++
}
}
if differ == 0 {
ans = append(ans, 0)
}
for i, ch := range s[:sLen-pLen] {
if count[ch-'a'] == 1 {
// 窗口中字母 s[i] 的数量与字符串 p 中的数量从不同变得相同
differ--
} else if count[ch-'a'] == 0 {
// 窗口中字母 s[i] 的数量与字符串 p 中的数量从相同变得不同
differ++
}
count[ch-'a']--
if count[s[i+pLen]-'a'] == -1 {
// 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从不同变得相同
differ--
} else if count[s[i+pLen]-'a'] == 0 {
// 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从相同变得不同
differ++
}
count[s[i+pLen]-'a']++
if differ == 0 {
ans = append(ans, i+1)
}
}
return
}