实践疑惑 | 使用pandas库读取文件,与直接使用read()函数读取文件相比,有何不同?
- 开发
- 38
-
1、数据结构化
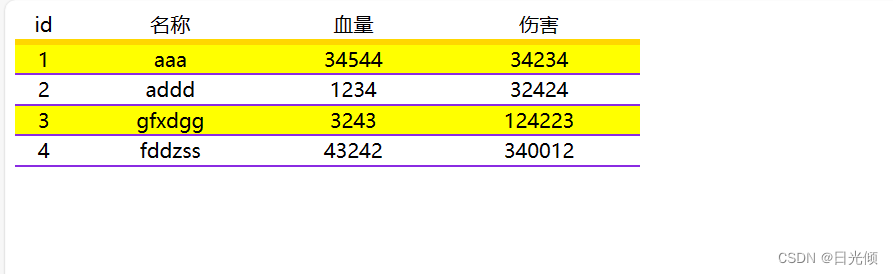
- pandas:当使用pandas的read_excel、read_csv等函数读取文件时,你得到的是一个结构化的DataFrame对象。DataFrame是一个二维的、大小可变的、具有潜在异构类型列的表格数据结构。它非常适合于存储和处理表格数据,并提供了丰富的API来进行数据清洗、转换、分析和可视化。
- 标准读取函数:使用Python的open()、read()函数读取文件时,你得到的是一个原始的字符串,其中包含了文件的全部内容。你需要自己处理这个字符串来解析数据,并将其结构化为你想要的形式(例如,转换为列表、字典或自定义的对象)。
2、性能与内存管理
- pandas:针对性能进行了优化,尤其是在处理大型数据集时。它内部使用了高效的数据存储和算法,可以更快地加载和处理数据。然而,对于非常大的数据集,pandas可能会消耗大量内存。
- 标准读取函数:标准读取函数在处理小型文件时通常足够快,但对于大型文件或需要复杂解析的文件,性能可能会成为问题。此外,由于你需要自己管理数据结构,因此在内存使用方面也可能不如pandas高效。
3、易用性和功能
- pandas:pandas提供了大量高级功能,如数据筛选、分组、排序、合并、连接、统计等,这些功能都很容易通过简洁的API调用实现。此外,pandas还集成了与许多其他库(如NumPy、Matplotlib、SciPy等)的互操作性。
- 标准读取函数:使用标准读取函数时,你需要自己实现所有这些功能,这通常意味着编写更多的代码和进行更多的调试。然而,这也给了你更大的灵活性来控制数据的处理方式。
4、文件格式支持
- pandas:pandas支持多种文件格式,包括CSV、Excel、SQL、HDF5、JSON等。这使得pandas成为处理多种不同来源数据的理想选择。
- 标准读取函数:标准读取函数主要支持文本文件(如CSV),但对于更复杂的文件格式(如Excel或JSON),你可能需要使用额外的库或编写更多的自定义代码来解析数据。
原文地址:https://blog.csdn.net/qq_48185833/article/details/136669996
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1767754968917479424.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!























![[LeetCode][LCR174] 寻找二叉搜索树中的目标节点](https://img-blog.csdnimg.cn/direct/f225a14825394334b3f16083bbf87355.png)