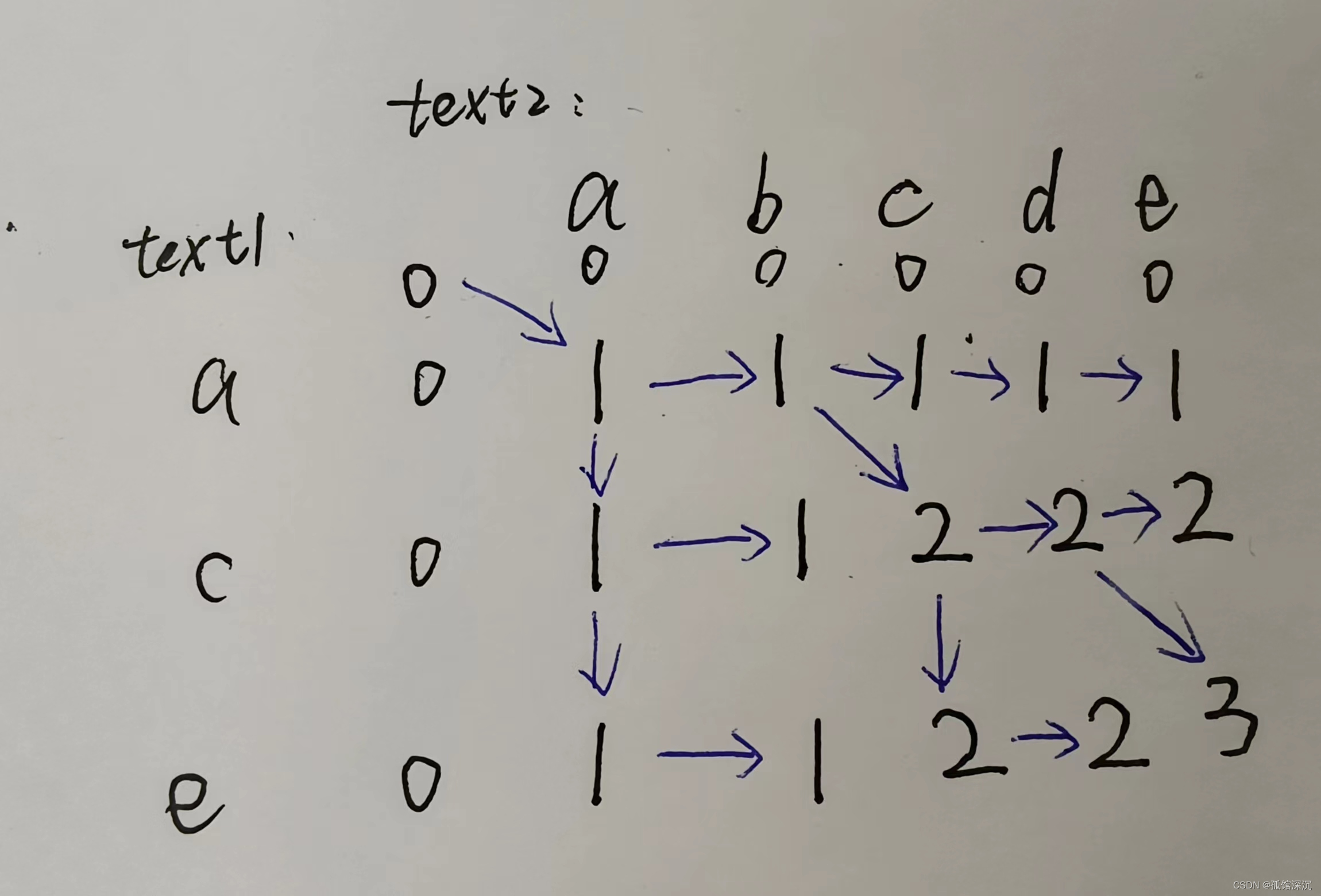
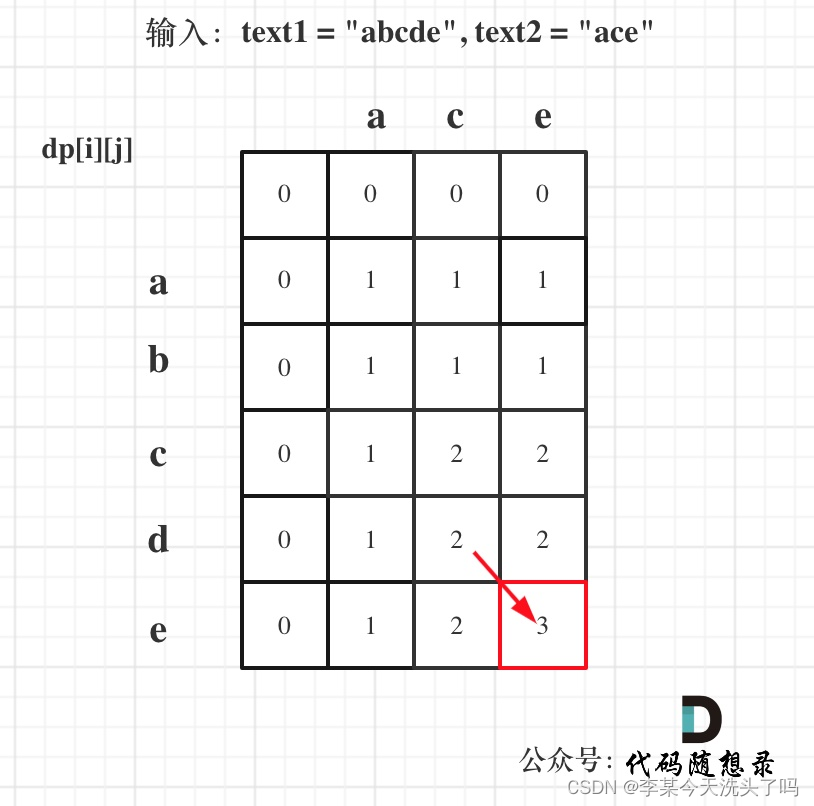
1143. 最长公共子序列
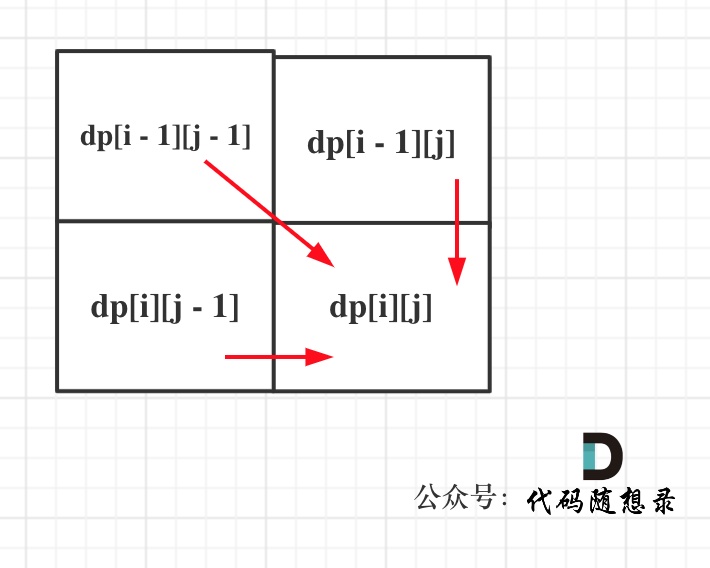
最长公共子序列和最长公共子数组的区别在于,dp中子序列可以不连续,可以从左上(text1[i-1] == text2[j-1])推出,也能从左边或者上边(取最大值)推出;公共子数组只能从左上角推出。
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> dp(text1.size()+1, vector<int>(text2.size()+1, 0));
for (int i = 1; i <= text1.size(); i++) {
for (int j = 1; j <= text2.size(); j++) {
// dp整体向右下移动一个
if (text1[i-1] == text2[j-1]) {
// 如果当前值相等,直接从左上角推
dp[i][j] = dp[i-1][j-1]+1;
}
else {
// 如果不相等,从左边或者上边取最大值推下来
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
}
return dp[text1.size()][text2.size()];
}
};
1035. 不相交的线
和最长公共子序列一个意思,就是找到两个数组或者字符串最长的公共序列(不要求连续)。时间复杂度O(m*n)。
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
// 笑死,根本想不出来就是最长公共子序列
vector<vector<int>> dp(nums1.size()+1, vector<int>(nums2.size()+1, 0));
for (int i = 1; i <= nums1.size(); i++) {
for (int j = 1; j <= nums2.size(); j++) {
if (nums1[i-1] == nums2[j-1]) {
dp[i][j] = dp[i-1][j-1]+1;
}
else {
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
}
return dp[nums1.size()][nums2.size()];
}
};
53. 最大子数组和
贪心:从前往后,用一个count计数,如果变量count大于结果值,更新结果值,如果count小于零,直接从零开始重新计数。其实就是如果到达一个值,该值之前的数加该值为正,表示对后面的数有益,可以容纳,如果加值为负,表示对后面的数组无益,直接归零,从头开始。
动态规划:dp[i]表示包含下标i的数据的最大子数组的和,初始化dp[0]=nums[0],递推公式为:dp[i] = max(dp[i-1] + nums[i], nums[i]);i从1开始。最后的结果值不一定在dp数组结尾取得,因此需要一个res值保存目前遍历过的子数组和的最大值。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
// 贪心
// int res = INT_MIN;
// int count = 0;
// for (int i = 0; i < nums.size(); i++) {
// count += nums[i];
// if (count > res) res = count;
// if (count < 0) count = 0;
// }
// return res;
// 动态规划
if (nums.size() == 1) return nums[0];
vector<int> dp(nums.size(), 0);
dp[0] = nums[0];
int res = nums[0];
for (int i = 1; i < nums.size(); i++) {
dp[i] = max(dp[i-1] + nums[i], nums[i]);
if (dp[i] > res)
res = dp[i];
}
for (auto i : dp) {
cout<<i<<" ";
}
return res;
}
};
今天还做了几道PTA的乙级题目,比较简单就不做总结了。但是acm模式所发现的一些不同记录下来,方便之后的机试使用。
1、万能头文件:#include<bits/stdc++.h>
用这个就不用去记每个函数、容器的对应头文件了,运行时间应该影响不大,编译比较费时一点。
2、初始化数组为全零,负一:memset(record, 0, sizeof(record));
record表示数组的指针,0表示初始化为0,sizeof(record)表示初始化大小。
3、sort函数从大到小排序:
sort(data.begin(), data.end(), greater<int>());
sort默认为从小到大排序,如果要从大到小,可以自己定义一个cmp函数,a>b,或者直接使用这个greater(),这种好像叫做仿函数吧。
4、如果一个数组输出最后不要空格,其余要空格,可以这样写
for (int i = 0; i < res.size(); i++) {
if(i == res.size()-1) {
cout<<res[i];
}
else {
cout<<res[i]<<" ";
}
}
5、使用unordered_map定义的时候可以这样写:
unordered_map<int, string> umap = {
{0,"ling"},
{1,"yi"},
{2,"er"},
{3,"san"},
{4,"si"},
{5,"wu"},
{6,"liu"},
{7,"qi"},
{8,"ba"},
{9,"jiu"}
};
有点类似二维数组的初始化。