文章目录
RAG(Retrieval-Augmented Generation)综述 Retrieval-Augmented Generation for Large Language Models: A Survey 粗略笔记,笔记中的图片大部分来自论文。
概述
LLM令人赞叹的能力之外也面临着幻觉、过时的知识、不透明、无法回溯的推理过程等挑战,RAG(Retrieval-Augmented Generation,检索增强)在2023年以来是解决这些LLM面临的挑战的热门解决方法。
综述《Retrieval-Augmented Generation for Large Language Models: A Survey》对RAG的发展和相关技术作了全面的总结。作者们将RAG范式进展概括为三个部分:Naive RAG, the Advanced RAG, the Modular RAG。将RAG相关研究演变分为如下图的四个阶段,这四个阶段是伴随着大模型的能力来演进的,其共性都是为了让模型更好的利用知识。

作者总结的RAG生态图

RAG 的定义
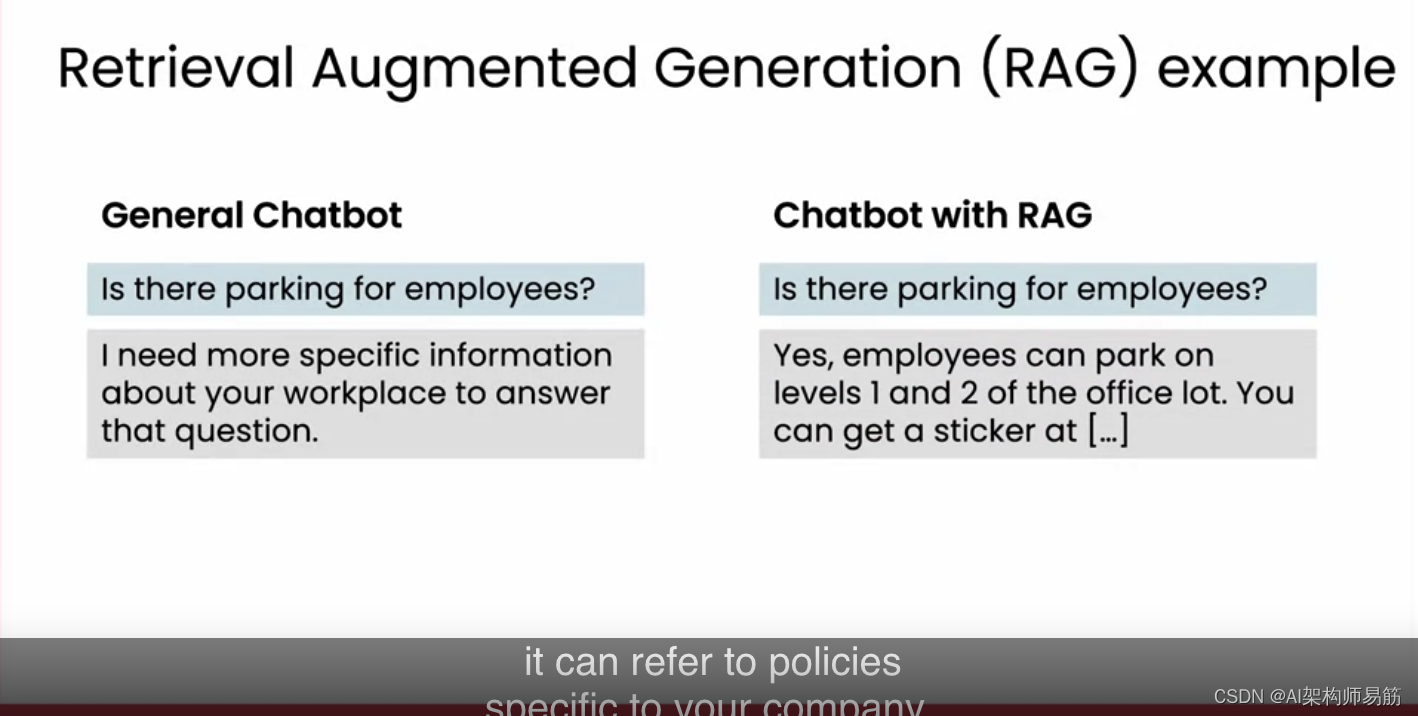
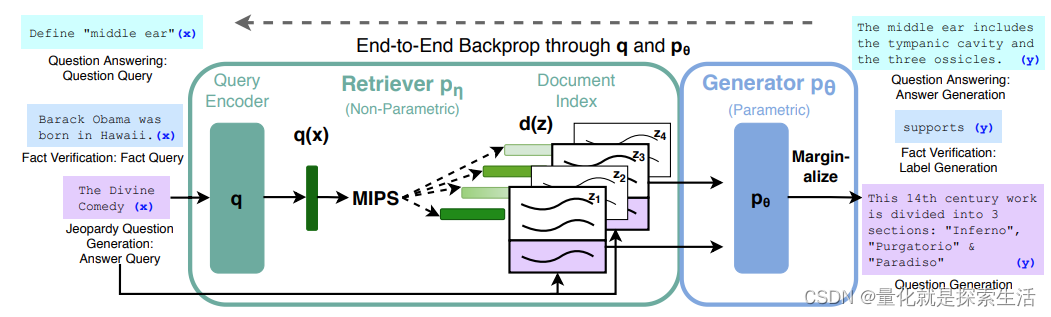
下图的RAG使用案例展示了RAG的工作流程:
- Indexing: 语料被切分成块,进行向量编码后建立索引
- Retrieval: 检索与问句相似度高的相关文档
- Generation: LLM基于检索到的上下文生成对应问题的回答

RAG关键问题:
- what to retrieve,从simple token --> entity retrieval --> chunk --> knowledge graph 粒度逐渐变粗。
- when to retrieve,从single --> adaptive --> multiple retrieval method检索频次增加。
- how to use the retrieved information, 结合方式从 input–> intermedia --> output layers 发展
RAG的框架
Naive RAG
Naive RAG的三个主要流程Indexing、Retrieval、Generation如前一节所述。实际应用时它在Retrieval、Generation、Augmentation这三个地方面临着一些挑战:
- 检索质量面临的挑战:低精度可能会造成幻觉、低召回可能使LLM无法全面回答问题
- 生成质量可能产生幻觉
- 增强过程面临着如何有效结合检索到的上下文到生成任务的挑战,可能会生成杂乱无章和不一致的输出。此外还有信息冗余和重复的问题
- 如何区分多个检索文档的重要性和相关度,如何调和不同写作风格和语调确保输出的一致性
- 如何避免模型只是重复检索的内容而不提供有价值的信息
Advanced RAG
为了克服Naive RAG的缺点,对于检索质量,Advanced RAG采用了一些检索前(pre-retrieval)和检索后(post-retrieval)策略,对于索引使用了滑动窗口、细粒度分隔和metadata等。
pre-retrieval process
这一过程主要是优化数据索引,目的是为了提高被索引内容的质量,有五个主要策略:
- 增加数据粒度(Enhancing data granularity):去掉不相关信息、消除实体和词项的模糊性、确认事实准确性、更新过期文档。
- 优化索引结构(Optimizing index structures): 调整分块chunk的大小、查询多个索引、利用图结构来捕捉相关信息
- 添加元数据信息(Adding metadata information):添加相关元数据信息如日期、目的等用来过滤chunk,以及参考文献的章节和分段信息来提高检索效率。
- 对齐优化(Alignment optimization): 引入”假设问题“来对齐文档(HyDE)
- 混合检索
Retrieval
检索阶段主要是计算查询与chunk的相似性,而向量模型对这个过程很关键,优化向量模型的方法:
- 微调向量模型,使用大模型如GPT-3.5-turbo基于文档chunk来生成一些问题后组成的语料对可作为微调语料。
- Dynamic Embedding,即相同的词对应到不同的上下文会有不同的向量表示。(对作者列的这一点有些疑问,现在主流的向量模型都是动态Embedding了,为啥要在这里单独列出来?)
post-retrieval process
如果直接将检索到的所有信息都喂给LLM,可能会超过LLM的上下文窗口限制,并且也可能会引入噪声使LLM不能专注在主要信息上。现在的检索后处理方法有:
- Re-Ranking. 对检索到的信息进行重排序,可以使用bge-rerank、cohereAI rerank等,也可以使用LostInTheMiddleRanker(将最不重要的内容放在prompt的中间)、Diversity Ranker(按照片段多样性来排序)等策略
- Prompt Compression. 压缩prompt中的不相关信息,相关研究有Selective Context、LLMLingua、Recomp、Context、Walking in the Memory Maze等
Modular RAG

作者所定义的RAG的三个范式概览如上图所示,虽然概念上有做区分,但是Modular RAG不是孤立的,Advanced RAG 是Modular RAG的特殊形式,Naive RAG 是Advanced RAG 的特殊形式。
modular RAG 包括的新模块:
- 搜索模块(Search),除相似性检索外,还包括搜索引擎、数据库、知识图谱等
- 记忆模块(Memory),利用LLM的记忆能力来辅助检索,代表工作如Selfmem
- 融合模块(Fusion),将查询扩展为multi-query,代表工作如RAG-Fusion
- 路由模块(Routing),对于用户请求决定接下来的行为,比如是否要搜索特定数据库、是否要进行摘要等等
- 预测模块(Predict),使用LLM来生成上下文,而不是直接先去检索
- 任务适配模块(Task Apapter),使RAG适应不同的下游任务,相关工作有UPRISE和 PROMPTAGATOR 。
相比于Naive RAG 和Advanced RAG由固定的一些模块组成,modular RAG的模式更多样和灵活,目前的研究主要分两块:Adding or Replacing Modules和Adjusting the Flow between Modules.
RAG的Pipeline涉及到的优化工作:
- Hybrid Search Exploration,应用不同的检索技术:keyword-based search, semantic search, vector search
- Recursive Retrieval and Query Engine,既检索小chunk,也检索更大chunk
- StepBack-prompt,鼓励LLM考虑更大的概念
- Sub-Queries,不同的查询策略如树查询、向量查询、chunk的依次查询
- Hypothetical Document Embeddings,HyDE(使用LLM根据查询语句生成假设的问句,使用假设问句来进行相似度检索)
Retrieval
创建有效的检索器设计到的三个基础问题:1. 怎么得到有效的语义表征?2. 哪些方法可对齐查询和文档的语义空间?3.怎么使检索器的输出对齐大模型的偏好?
Enhancing Semantic Representations
chunk 优化
chunk太大或者太小都可能会造成次优结果,所以选择合适chunk大小很重要,选择合适的chunk大小要考虑以下因素:
- 索引内容的特性
- 向量模型和其最佳编码长度,比如sentence-transformer更适合句子编码,而text-embedding-ada-002更适合大小为256或512个token的文本块
- 用户查询请求的长度和复杂性
- 检索结果的应用场景,比如语义搜索或问答
- 所使用的LLM的上下文窗口大小
目前RAG相关的块优化方法:
- 滑动窗口技术,使得可以合并多个检索过程的相关结果
- small2big,在初始检索阶段使用小的文本块,接着将相关的更大的文本块喂给LLM处理
- abstract embedding technique,排序基于文档摘要的top K 个检索结果,提供了对文档更综合的理解
- 基于metadata的文档过滤
- 图索引技术,将实体与关系转变成节点和连接,可提升相关度,特别是对于多跳问题很有帮助。
微调向量模型
现在的向量模型性能已经比以前更强,但是对于专业领域内的应用仍有力不从心的情况,并且微调向量模型之后可以使得模型更好的理解用户请求。微调向量模型的两种方法:
- Domain Knowledge Fine-tuning,重要的是构建一个涵盖领域相关的数据集,数据集包括:queries、a corpus、relevant documents.
- Fine-tuning for Downstream Tasks,代表工作如 PROMPTAGATOR、LLM-Embedder。
Aligning Queries and Documents
- Query Rewriting ,Query2Doc和ITER-RETGEN将原查询添加额外的指引语句后使用LLM生成伪文档;HyDE生成假设文档;RRR引入一个反转传统检索和阅读顺序的框架。STEP-BACKPROMPTING基于概念使LLM进行抽象的推理和检索。
- Embedding Transformation,使用一些技巧来转变向量,比如LlamaIndex里演示在query encoder后面添加一个adapter,SANTA也尝试去对齐查询和结构化文档
Aligning Retriever and LLM
- Fine-tuning Retrievers,利用LLM的反馈来优化检索模型,相关工作有AAR、REPLUG、UPRISE、Atlas等
- Apapter,训练一个外部adapter来对齐Retriever和LLM,相关工作有PRCA、RECOMP、PKG等
Generation
Post-retrieval with Frozen LLM,对检索到的相关文档进行处理,提高检索结果的质量。
Information Compression,相关工作有PRCA、RECOMP等
Reranking,
对LLM进行微调
Augmentation in RAG
关于Augmentation的想法,它不是RAG的流程中具体的一个部分,而是RAG如何去增强LLM,所以在RAG中各个流程中都有所涉及,在内容上看起来也跟前面介绍的一些内容会有重复之处

RAG in Augmentation Stages
Pre-training Stage,在大模型的预训练阶段进行知识增强,相关工作有REALM、RETRO、Atlas、COG、RETRO++等
Fine-tuning Stage,在大模型的微调阶段进行知识增强
Inference Stage,在大模型的推理阶段进行知识增强
Augmentation Source
增强的数据来源被分为:
Unstructured Data
Structured Data
LLMs-Generated Content
下图是使用不同数据来源的RAG相关研究的示意(不同的颜色表示不同类别的数据源)

Augmentation Process
对于检索方式,一次检索的效率可能不够高,所以衍生除了如下三种检索方式(上面图片叶子边框示意了不同类型的检索方式):
Iterative Retrieval
Recursive Retrieval
Adaptive Retrieval
RAG vs Fine-Tuning

RAG像是给模型一本教科书、而微调像一个学生在不断去内化知识。两者不是互相排斥的而是互补的,在不同的层次上增强大模型的能力。

RAG Evaluation
Evaluation Targets
RAG的评估主要涉及检索和生成两个关键模块,因此主要评估:
Retrieval Quality,评估指标有Hit Rate,MRR、NDGG
Generation Quality,分为未标注内容和标注内容两类,对于未标注内容包括:faithfulness, relevance, non-harmfulness of the generated answers。对于标注内容主要是信息的准确度。
Evaluation Aspects
Quality Scores
- context relevance
- answer faithfulness
- answer relevance
Required Abilities
- noise robustness
- negative rejection
- information integration
- counterfactual robustness
Context relevance和noise robustness对评估检索质量很重要,answer faithfulness, answer relevance, negative rejection, information integration, counterfactual robustness 对评估生成质量很重要。

Evaluation Benchmarks and Tools
评估基准和框架总结如下图

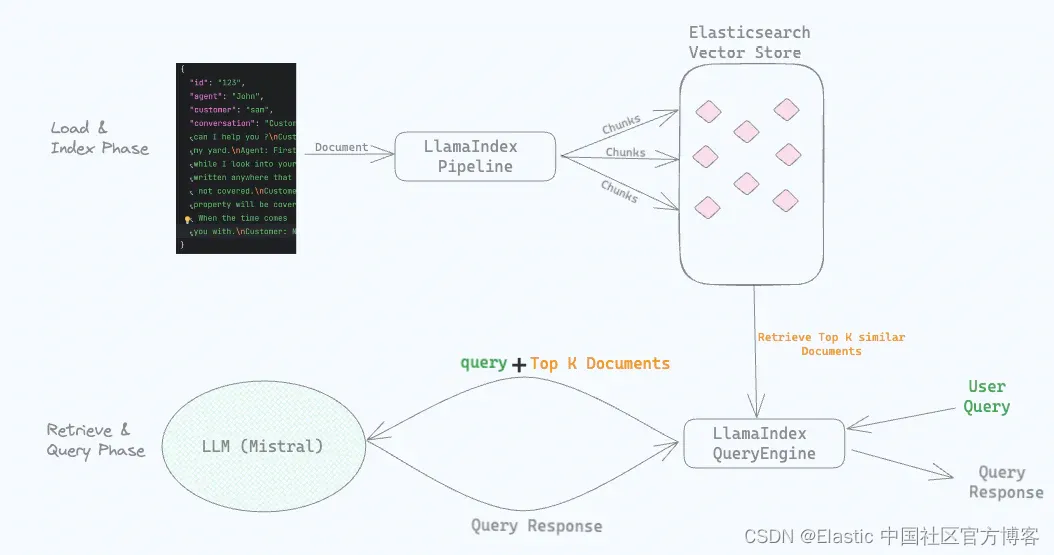
Llamaindex的cheet sheet
Llamaindex 针对这篇综述整理了一个Llamaindex 使用的cheet sheet(下面两张图片来自链接网页)


参考资料
- Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. n.d. “Retrieval-Augmented Generation for Large Language Models: A Survey.” 本笔记中大部分图片来自于论文。
- 论文对应的github
- llama index 针对此篇综述整理的cheet sheet

![[阅读<span style='color:red;'>笔记</span>21][<span style='color:red;'>RA</span>-CM3]<span style='color:red;'>Retrieval</span>-Augmented Multimodal Language Modeling](https://img-blog.csdnimg.cn/direct/36f167981eba42499f9b4d0c8d9f1f82.png)
![[论文阅读] |<span style='color:red;'>RAG</span>评估_<span style='color:red;'>Retrieval</span>-Augmented Generation Benchmark](https://img-blog.csdnimg.cn/direct/77abf882e4ca477fa70852e5cd7bcc7a.png)

![[论文<span style='color:red;'>笔记</span>]Corrective <span style='color:red;'>Retrieval</span> Augmented Generation](https://img-blog.csdnimg.cn/img_convert/0a59a6029e0fcb356abd3fe8ab1eb181.png)