如果算法预测出的结果不太好,可以考虑以下几个方面:
获得更多的训练样本
采用更少的特征
尝试获取更多的特征
增加多项式特征
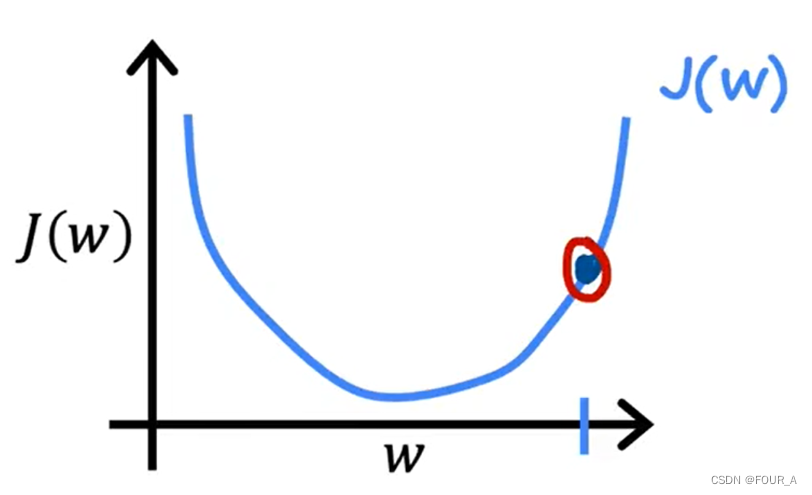
增大或减小 λ

模型评估(evaluate model)
例如房价预测,用五个数据训练出的模型能很好的拟合这几个数据,但不能泛化到新的数据。

将数据按70%、30%的比例分成两份,一份是训练集,一份是测试集。


模型选择
一种有缺陷的方法:
可以计算一阶多项式、二阶多项式、...、十阶多项式的J(w,b),看看哪一个更小 ,就选择哪个作为模型。但这样仍可能出现泛化的不好的情况。

好的方法:
将数据集分成三部分,60%训练集(training set) ,20%交叉验证集(cross validation set / developent set / dev set),20%测试集(test set)。

三个部分的 error 计算公式如下
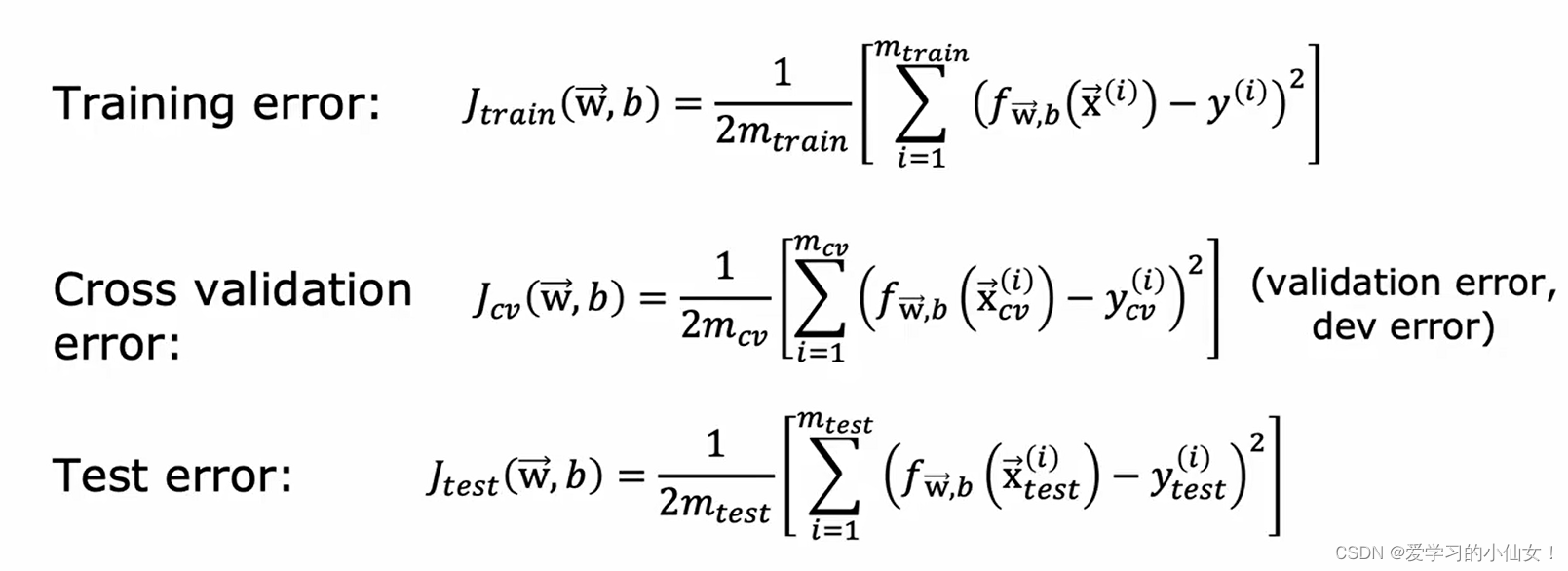
可以选择交叉测试集误差最小的那个,然后用测试集误差来评估模型泛化的好坏。模型的选择要看模型在训练集和交叉验证集的好坏!不看测试集的结果。