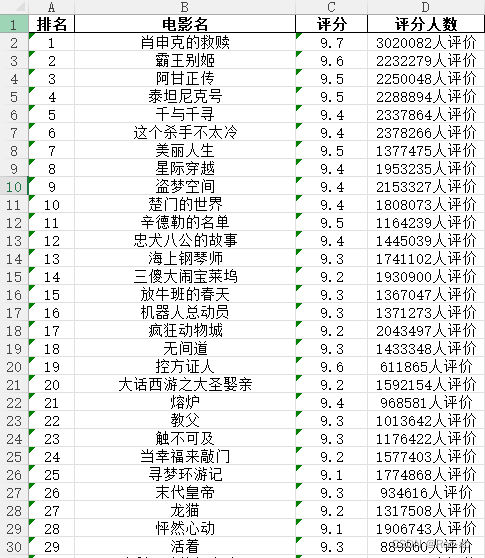
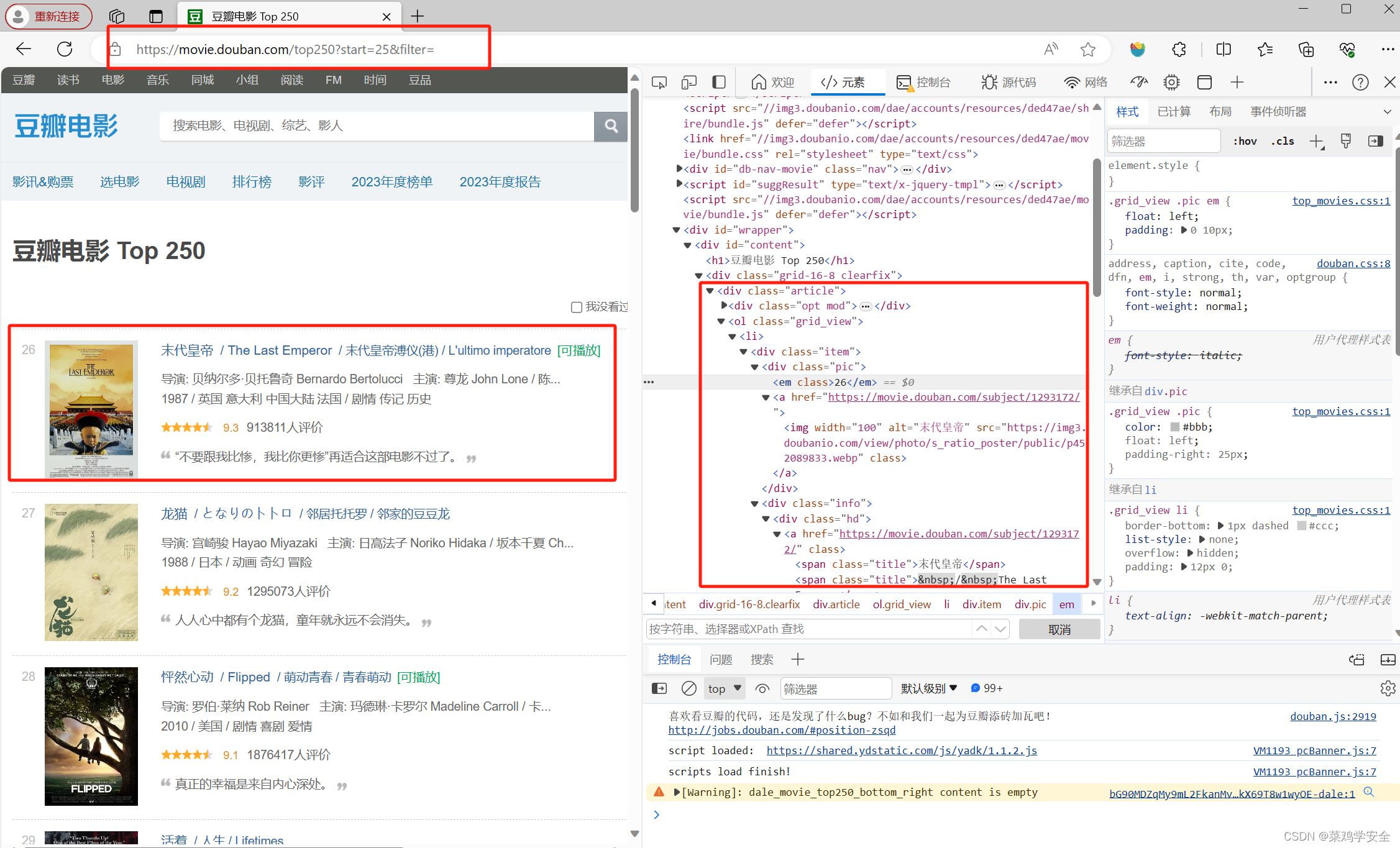
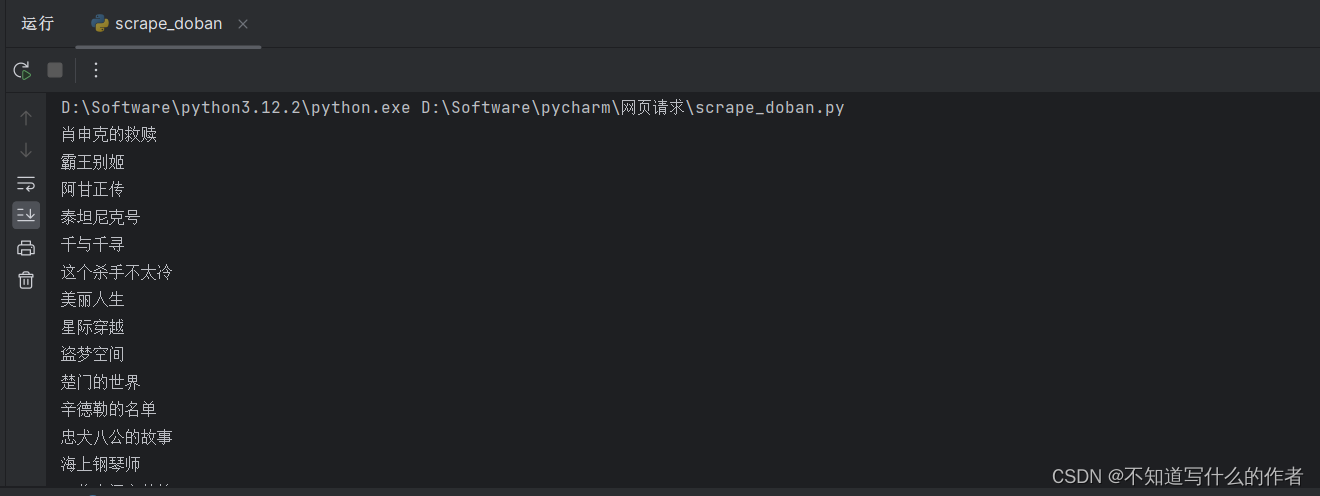
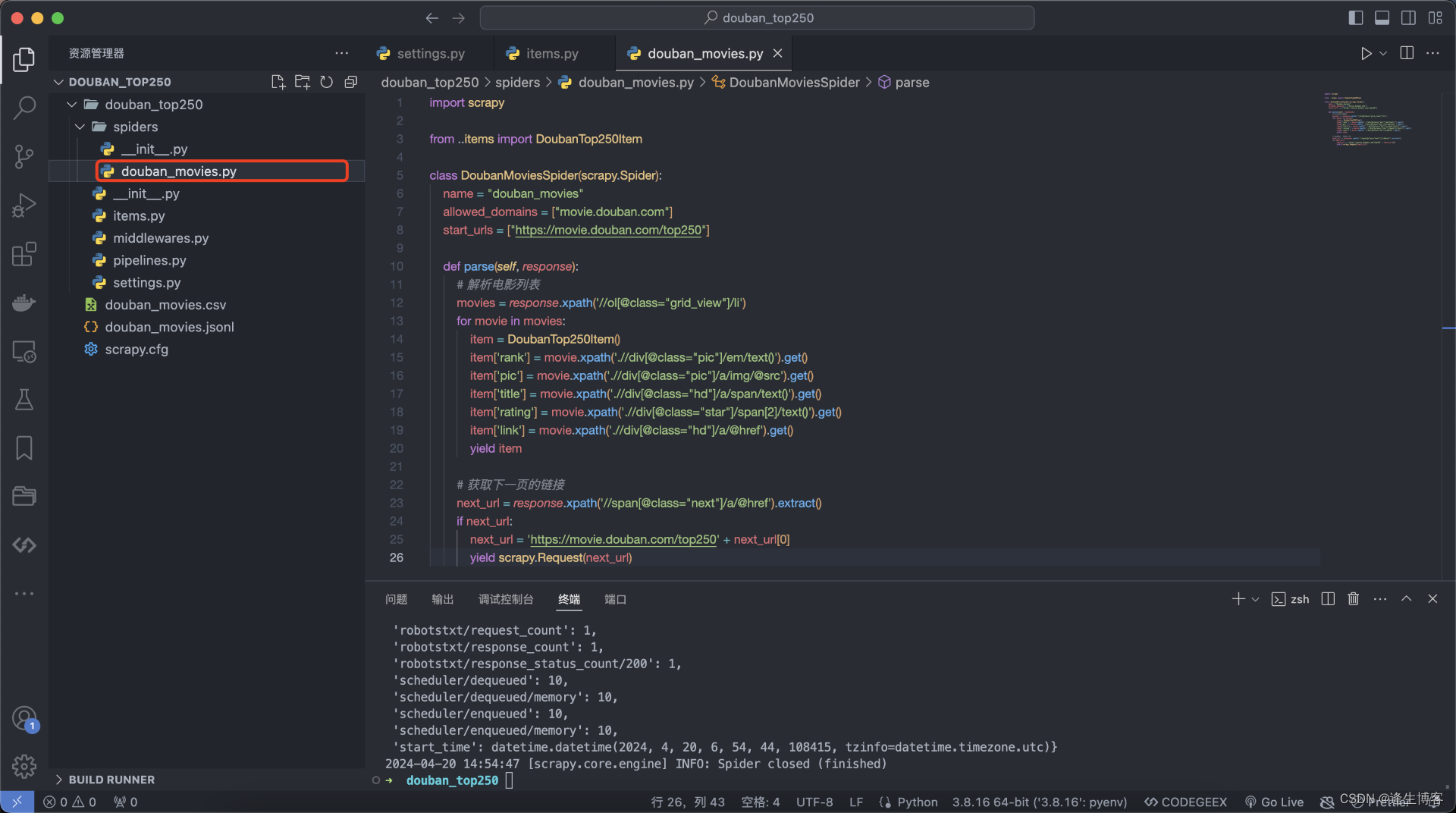
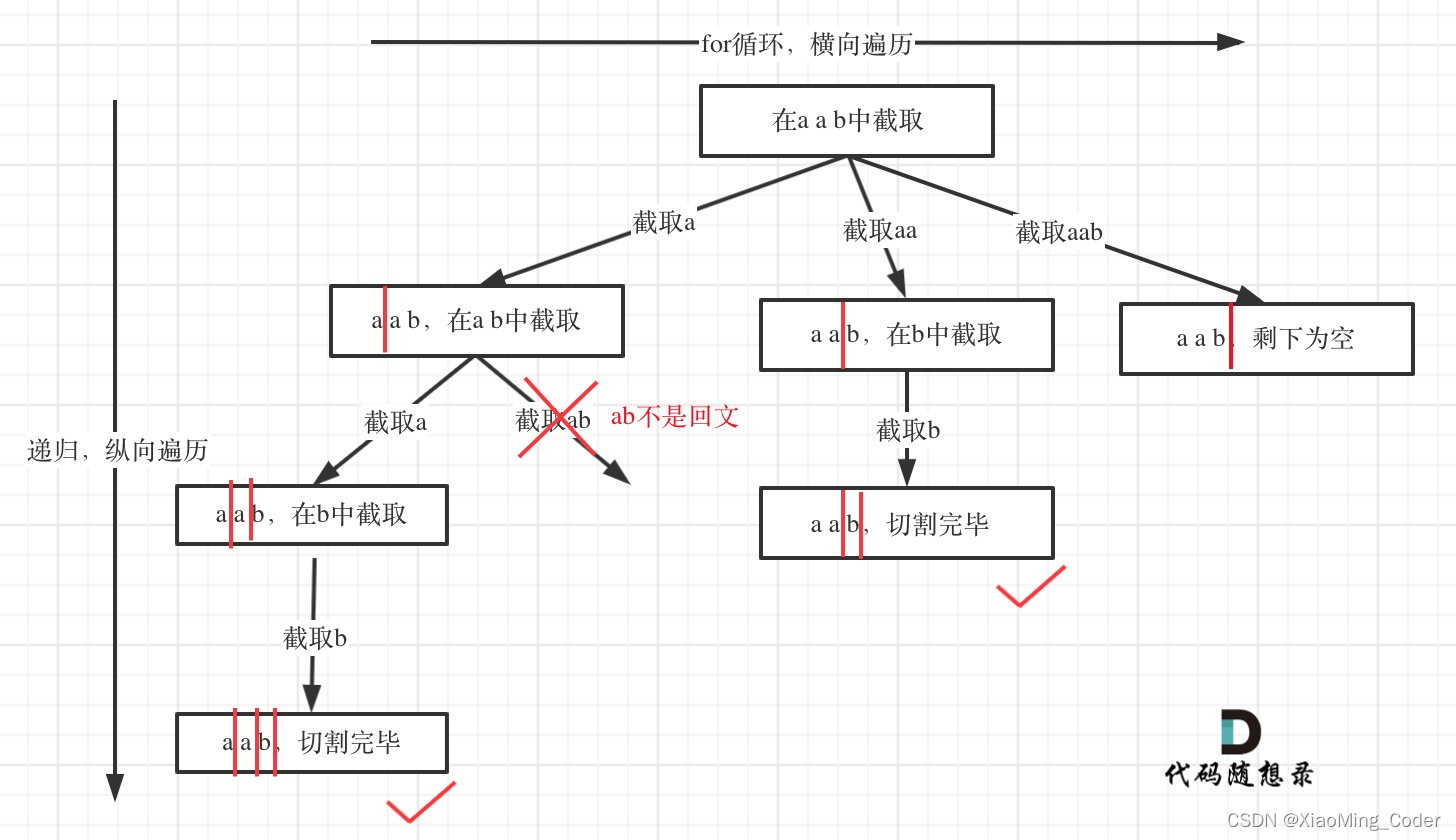
获取网页源码,拿想要的内容就完事了。
import xlwt
import requests
from bs4 import BeautifulSoup
def get_style():
style = xlwt.XFStyle()
alignment = xlwt.Alignment()
alignment.horz = 0x02
alignment.vert = 0x01
style.alignment = alignment
font = xlwt.Font()
font.name = '仿宋'
style.font = font
return style
def get_excel(style):
workbook = xlwt.Workbook(encoding='ascii')
worksheet = workbook.add_sheet("MovieTop250")
col_names = ["排名", "影名", "评论", "链接"]
for i in range(len(col_names)):
worksheet.write(0, i, col_names[i], style)
worksheet.col(0).width = 100 * 20
worksheet.col(1).width = 400 * 20
worksheet.col(2).width = 1200 * 20
worksheet.col(3).width = 650 * 20
return workbook, worksheet
def crawler(worksheet, style):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 '
}
count = 1
for page_num in range(0, 250, 25):
content = requests.get(f"https://movie.douban.com/top250?start={page_num}", headers=headers).text
soup = BeautifulSoup(content, "html.parser")
all_movies = soup.findAll("div", attrs={"class": "info"})
for movie in all_movies:
movie_name = movie.find("span", attrs={"class": "title"}).string
comment = movie.find("span", attrs={"class": "inq"})
movie_comment = "None" if comment is None else comment.string
movie_link = movie.find("a").attrs["href"]
worksheet.write(count, 0, count, style)
worksheet.write(count, 1, f"《{movie_name}》", style)
worksheet.write(count, 2, f"{movie_comment}", style)
worksheet.write(count, 3, f"{movie_link}", style)
count += 1
if __name__ == '__main__':
_style = get_style()
_workbook, _worksheet = get_excel(_style)
crawler(_worksheet, _style)
_workbook.save("MovieTop250.xls")